pixel level contrastive learning
0.1.1
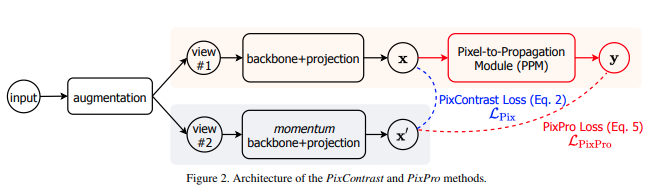
Implémentation de l'apprentissage contrastif au niveau du pixel, proposée dans l'article "Propagate Yourself", dans Pytorch. En plus d'effectuer un apprentissage contrastif au niveau des pixels, le réseau en ligne transmet en outre les représentations au niveau des pixels à un module de propagation de pixels et impose une perte de similarité au réseau cible. Ils ont battu toutes les méthodes précédentes non supervisées et supervisées dans les tâches de segmentation.
$ pip install pixel-level-contrastive-learningVous trouverez ci-dessous un exemple de la façon dont vous utiliseriez le framework pour auto-superviser la formation d'un resnet, en prenant la sortie de la couche 4 (8 x 8 « pixels »).
import torch
from pixel_level_contrastive_learning import PixelCL
from torchvision import models
from tqdm import tqdm
resnet = models . resnet50 ( pretrained = True )
learner = PixelCL (
resnet ,
image_size = 256 ,
hidden_layer_pixel = 'layer4' , # leads to output of 8x8 feature map for pixel-level learning
hidden_layer_instance = - 2 , # leads to output for instance-level learning
projection_size = 256 , # size of projection output, 256 was used in the paper
projection_hidden_size = 2048 , # size of projection hidden dimension, paper used 2048
moving_average_decay = 0.99 , # exponential moving average decay of target encoder
ppm_num_layers = 1 , # number of layers for transform function in the pixel propagation module, 1 was optimal
ppm_gamma = 2 , # sharpness of the similarity in the pixel propagation module, already at optimal value of 2
distance_thres = 0.7 , # ideal value is 0.7, as indicated in the paper, which makes the assumption of each feature map's pixel diagonal distance to be 1 (still unclear)
similarity_temperature = 0.3 , # temperature for the cosine similarity for the pixel contrastive loss
alpha = 1. , # weight of the pixel propagation loss (pixpro) vs pixel CL loss
use_pixpro = True , # do pixel pro instead of pixel contrast loss, defaults to pixpro, since it is the best one
cutout_ratio_range = ( 0.6 , 0.8 ) # a random ratio is selected from this range for the random cutout
). cuda ()
opt = torch . optim . Adam ( learner . parameters (), lr = 1e-4 )
def sample_batch_images ():
return torch . randn ( 10 , 3 , 256 , 256 ). cuda ()
for _ in tqdm ( range ( 100000 )):
images = sample_batch_images ()
loss = learner ( images ) # if positive pixel pairs is equal to zero, the loss is equal to the instance level loss
opt . zero_grad ()
loss . backward ()
print ( loss . item ())
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# after much training, save the improved model for testing on downstream task
torch . save ( resnet , 'improved-resnet.pt' ) Vous pouvez également renvoyer le nombre de paires de pixels positives en forward , à des fins de journalisation ou à d'autres fins.
loss , positive_pairs = learner ( images , return_positive_pairs = True ) @misc { xie2020propagate ,
title = { Propagate Yourself: Exploring Pixel-Level Consistency for Unsupervised Visual Representation Learning } ,
author = { Zhenda Xie and Yutong Lin and Zheng Zhang and Yue Cao and Stephen Lin and Han Hu } ,
year = { 2020 } ,
eprint = { 2011.10043 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

