byol pytorch
0.8.2
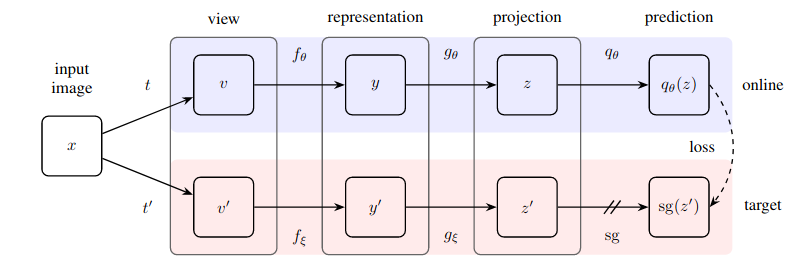
Mise en œuvre pratique d'une méthode étonnamment simple d'apprentissage auto-supervisé qui atteint un nouvel état de l'art (dépassant SimCLR) sans apprentissage contrastif et sans devoir désigner des paires négatives.
Ce référentiel propose un module qui permet d'envelopper facilement n'importe quel réseau neuronal basé sur des images (réseau résiduel, discriminateur, réseau politique) pour commencer immédiatement à bénéficier de données d'images non étiquetées.
Mise à jour 1 : Il existe désormais de nouvelles preuves selon lesquelles la normalisation par lots est essentielle au bon fonctionnement de cette technique.
Mise à jour 2 : un nouvel article a remplacé avec succès la norme de lot par la norme de groupe + la standardisation du poids, réfutant le fait que les statistiques de lot soient nécessaires au fonctionnement du BYOL
Mise à jour 3 : Enfin, nous avons une analyse des raisons pour lesquelles cela fonctionne
L'excellente explication de Yannic Kilcher
Maintenant, évitez à votre organisation d'avoir à payer pour les étiquettes :)
$ pip install byol-pytorchBranchez simplement votre réseau neuronal, en spécifiant (1) les dimensions de l'image ainsi que (2) le nom (ou l'index) de la couche cachée, dont la sortie est utilisée comme représentation latente utilisée pour l'entraînement auto-supervisé.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
learner . update_moving_average () # update moving average of target encoder
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )C'est à peu près tout. Après de nombreuses formations, le réseau résiduel devrait désormais mieux performer dans ses tâches supervisées en aval.
Un nouvel article de Kaiming He suggère que BYOL n'a même pas besoin que l'encodeur cible soit une moyenne mobile exponentielle de l'encodeur en ligne. J'ai décidé d'intégrer cette option afin que vous puissiez facilement utiliser cette variante pour l'entraînement, simplement en définissant l'indicateur use_momentum sur False . Vous n'aurez plus besoin d'invoquer update_moving_average si vous suivez cette voie comme indiqué dans l'exemple ci-dessous.
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
use_momentum = False # turn off momentum in the target encoder
)
opt = torch . optim . Adam ( learner . parameters (), lr = 3e-4 )
def sample_unlabelled_images ():
return torch . randn ( 20 , 3 , 256 , 256 )
for _ in range ( 100 ):
images = sample_unlabelled_images ()
loss = learner ( images )
opt . zero_grad ()
loss . backward ()
opt . step ()
# save your improved network
torch . save ( resnet . state_dict (), './improved-net.pt' )Bien que les hyperparamètres aient déjà été définis sur ce que l'article a trouvé optimal, vous pouvez les modifier avec des arguments de mots clés supplémentaires dans la classe wrapper de base.
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
projection_size = 256 , # the projection size
projection_hidden_size = 4096 , # the hidden dimension of the MLP for both the projection and prediction
moving_average_decay = 0.99 # the moving average decay factor for the target encoder, already set at what paper recommends
) Par défaut, cette bibliothèque utilisera les augmentations de l'article SimCLR (qui est également utilisé dans l'article BYOL). Cependant, si vous souhaitez spécifier votre propre pipeline d'augmentation, vous pouvez simplement transmettre votre propre fonction d'augmentation personnalisée avec le mot-clé augment_fn .
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn
)Dans l'article, ils semblent assurer que l'une des augmentations a une probabilité de flou gaussien plus élevée que l'autre. Vous pouvez également l'ajuster à votre guise.
augment_fn = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip ()
)
augment_fn2 = nn . Sequential (
kornia . augmentation . RandomHorizontalFlip (),
kornia . filters . GaussianBlur2d (( 3 , 3 ), ( 1.5 , 1.5 ))
)
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = - 2 ,
augment_fn = augment_fn ,
augment_fn2 = augment_fn2 ,
) Pour récupérer les intégrations ou les projections, il vous suffit de passer un indicateur return_embeddings = True à l'instance de l'apprenant BYOL
import torch
from byol_pytorch import BYOL
from torchvision import models
resnet = models . resnet50 ( pretrained = True )
learner = BYOL (
resnet ,
image_size = 256 ,
hidden_layer = 'avgpool'
)
imgs = torch . randn ( 2 , 3 , 256 , 256 )
projection , embedding = learner ( imgs , return_embedding = True ) Le référentiel propose désormais des formations distribuées avec ? Huggingface Accélérer. Il vous suffit de transmettre votre propre Dataset dans le BYOLTrainer importé
Configurez d’abord la configuration pour la formation distribuée en appelant la CLI accélérée
$ accelerate config Créez ensuite votre script de formation comme indiqué ci-dessous, par exemple dans ./train.py
from torchvision import models
from byol_pytorch import (
BYOL ,
BYOLTrainer ,
MockDataset
)
resnet = models . resnet50 ( pretrained = True )
dataset = MockDataset ( 256 , 10000 )
trainer = BYOLTrainer (
resnet ,
dataset = dataset ,
image_size = 256 ,
hidden_layer = 'avgpool' ,
learning_rate = 3e-4 ,
num_train_steps = 100_000 ,
batch_size = 16 ,
checkpoint_every = 1000 # improved model will be saved periodically to ./checkpoints folder
)
trainer ()Utilisez ensuite à nouveau la CLI d'accélération pour lancer le script
$ accelerate launch ./train.pySi votre tâche en aval implique une segmentation, veuillez consulter le référentiel suivant, qui étend BYOL à l'apprentissage au niveau « pixel ».
https://github.com/lucidrains/pixel-level-contrastive-learning
@misc { grill2020bootstrap ,
title = { Bootstrap Your Own Latent: A New Approach to Self-Supervised Learning } ,
author = { Jean-Bastien Grill and Florian Strub and Florent Altché and Corentin Tallec and Pierre H. Richemond and Elena Buchatskaya and Carl Doersch and Bernardo Avila Pires and Zhaohan Daniel Guo and Mohammad Gheshlaghi Azar and Bilal Piot and Koray Kavukcuoglu and Rémi Munos and Michal Valko } ,
year = { 2020 } ,
eprint = { 2006.07733 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.LG }
} @misc { chen2020exploring ,
title = { Exploring Simple Siamese Representation Learning } ,
author = { Xinlei Chen and Kaiming He } ,
year = { 2020 } ,
eprint = { 2011.10566 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
}

