sinkhorn transformer
0.11.4
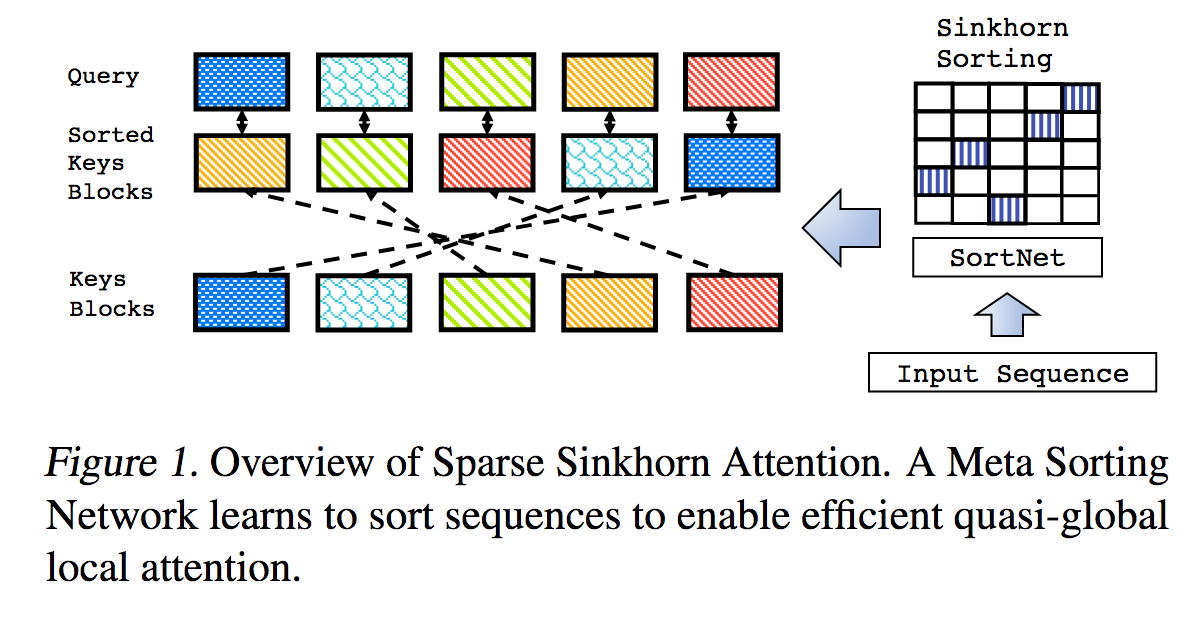
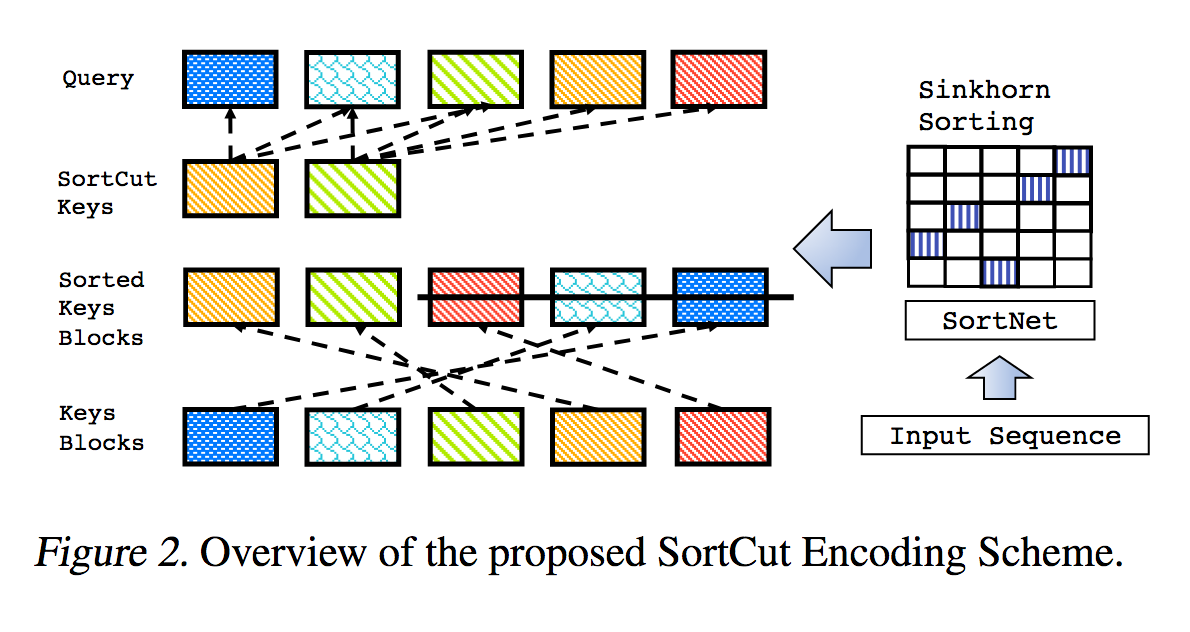
Il s'agit d'une reproduction du travail décrit dans Sparse Sinkhorn Attention, avec des améliorations supplémentaires.
Il comprend un réseau de tri paramétré, utilisant la normalisation Sinkhorn pour échantillonner une matrice de permutation qui fait correspondre les groupes de clés les plus pertinents aux groupes de requêtes.
Ce travail intègre également des réseaux réversibles et un chunking à rétroaction (concepts introduits par Reformer) pour permettre des économies de mémoire supplémentaires.
204 000 jetons (à des fins de démonstration)
$ pip install sinkhorn_transformerUn modèle de langage basé sur Sinkhorn Transformer
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 8192 ,
bucket_size = 128 , # size of the buckets
causal = False , # auto-regressive or not
n_sortcut = 2 , # use sortcut to reduce memory complexity to linear
n_top_buckets = 2 , # sort specified number of key/value buckets to one query bucket. paper is at 1, defaults to 2
ff_chunks = 10 , # feedforward chunking, from Reformer paper
reversible = True , # make network reversible, from Reformer paper
emb_dropout = 0.1 , # embedding dropout
ff_dropout = 0.1 , # feedforward dropout
attn_dropout = 0.1 , # post attention dropout
attn_layer_dropout = 0.1 , # post attention layer dropout
layer_dropout = 0.1 , # add layer dropout, from 'Reducing Transformer Depth on Demand' paper
weight_tie = True , # tie layer parameters, from Albert paper
emb_dim = 128 , # embedding factorization, from Albert paper
dim_head = 64 , # be able to fix the dimension of each head, making it independent of the embedding dimension and the number of heads
ff_glu = True , # use GLU in feedforward, from paper 'GLU Variants Improve Transformer'
n_local_attn_heads = 2 , # replace N heads with local attention, suggested to work well from Routing Transformer paper
pkm_layers = ( 4 , 7 ), # specify layers to use product key memory. paper shows 1 or 2 modules near the middle of the transformer is best
pkm_num_keys = 128 , # defaults to 128, but can be increased to 256 or 512 as memory allows
)
x = torch . randint ( 0 , 20000 , ( 1 , 2048 ))
model ( x ) # (1, 2048, 20000)Un transformateur Sinkhorn simple, des couches d'attention Sinkhorn
import torch
from sinkhorn_transformer import SinkhornTransformer
model = SinkhornTransformer (
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128
)
x = torch . randn ( 1 , 2048 , 1024 )
model ( x ) # (1, 2048, 1024)Transformateur codeur/décodeur Sinkhorn
import torch
from sinkhorn_transformer import SinkhornTransformerLM
DE_SEQ_LEN = 4096
EN_SEQ_LEN = 4096
enc = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
heads = 8 ,
bucket_size = 128 ,
max_seq_len = DE_SEQ_LEN ,
reversible = True ,
return_embeddings = True
). cuda ()
dec = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 512 ,
depth = 6 ,
causal = True ,
bucket_size = 128 ,
max_seq_len = EN_SEQ_LEN ,
receives_context = True ,
context_bucket_size = 128 , # context key / values can be bucketed differently
reversible = True
). cuda ()
x = torch . randint ( 0 , 20000 , ( 1 , DE_SEQ_LEN )). cuda ()
y = torch . randint ( 0 , 20000 , ( 1 , EN_SEQ_LEN )). cuda ()
x_mask = torch . ones_like ( x ). bool (). cuda ()
y_mask = torch . ones_like ( y ). bool (). cuda ()
context = enc ( x , input_mask = x_mask )
dec ( y , context = context , input_mask = y_mask , context_mask = x_mask ) # (1, 4096, 20000) Par défaut, le modèle se plaindra si une entrée qui n'est pas un multiple de la taille du compartiment. Pour éviter d'avoir à faire les mêmes calculs de remplissage à chaque fois, vous pouvez utiliser la classe d'assistance Autopadder . Il s'occupera également du input_mask pour vous, s'il est fourni. Les clés/valeurs contextuelles et le masque sont également pris en charge.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
from sinkhorn_transformer import Autopadder
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
max_seq_len = 2048 ,
bucket_size = 128 ,
causal = True
)
model = Autopadder ( model , pad_left = True ) # autopadder will fetch the bucket size and autopad input
x = torch . randint ( 0 , 20000 , ( 1 , 1117 )) # odd sequence length
model ( x ) # (1, 1117, 20000) Ce référentiel s'est éloigné du papier et attire désormais l'attention à la place du filet de tri original + échantillonnage de gumbel Sinkhorn. Je n'ai pas encore trouvé de différence notable en termes de performances, et le nouveau schéma me permet de généraliser le réseau à des longueurs de séquence flexibles. Si vous souhaitez essayer Sinkhorn, veuillez utiliser les paramètres suivants, qui ne fonctionnent que pour les réseaux non causals.
import torch
from sinkhorn_transformer import SinkhornTransformerLM
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 128 ,
max_seq_len = 8192 ,
use_simple_sort_net = True , # turn off attention sort net
sinkhorn_iter = 7 , # number of sinkhorn iterations - default is set at reported best in paper
n_sortcut = 2 , # use sortcut to reduce complexity to linear time
temperature = 0.75 , # gumbel temperature - default is set at reported best in paper
non_permutative = False , # allow buckets of keys to be sorted to queries more than once
)
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
model ( x ) # (1, 8192, 20000) Pour voir les avantages de l'utilisation de PKM, le taux d'apprentissage des valeurs doit être défini à un niveau supérieur au reste des paramètres. (Recommandé pour être 1e-2 )
Vous pouvez suivre les instructions ici pour le configurer correctement https://github.com/lucidrains/product-key-memory#learning-rates
Sinkhorn, lorsqu'il est entraîné sur des séquences de longueur fixe, semble avoir du mal à décoder les séquences à partir de zéro, principalement en raison du fait que le réseau de tri a du mal à généraliser lorsque les seaux sont partiellement remplis de jetons de remplissage.
Heureusement, je pense avoir trouvé une solution simple. Lors de l'entraînement, pour les réseaux causals, tronquer aléatoirement les séquences et forcer le réseau de tri à se généraliser. J'ai fourni un indicateur ( randomly_truncate_sequence ) pour l'instance AutoregressiveWrapper afin de rendre cela plus facile.
import torch
from sinkhorn_transformer import SinkhornTransformerLM , AutoregressiveWrapper
model = SinkhornTransformerLM (
num_tokens = 20000 ,
dim = 1024 ,
heads = 8 ,
depth = 12 ,
bucket_size = 75 ,
max_seq_len = 8192 ,
causal = True
)
model = AutoregressiveWrapper ( model )
x = torch . randint ( 0 , 20000 , ( 1 , 8192 ))
loss = model ( x , return_loss = True , randomly_truncate_sequence = True ) # (1, 8192, 20000)Je suis ouvert aux suggestions si quelqu'un a trouvé une meilleure solution.
Il existe un problème potentiel avec le réseau de tri causal, dans lequel la décision quant aux compartiments clé/valeur du passé triés dans un compartiment dépend uniquement du premier jeton et non du reste (en raison du schéma de regroupement et de la prévention des fuites futures vers passé).
J'ai tenté d'atténuer ce problème en faisant pivoter la moitié des têtes vers la gauche en fonction de la taille du seau - 1, favorisant ainsi le dernier jeton comme étant le premier. C'est également la raison pour laquelle AutoregressiveWrapper utilise par défaut le remplissage à gauche pendant l'entraînement, pour toujours s'assurer que le dernier jeton de la séquence a son mot à dire sur ce qu'il faut récupérer.
Si quelqu'un a trouvé une solution plus propre, merci de me le faire savoir dans les problèmes.
@misc { tay2020sparse ,
title = { Sparse Sinkhorn Attention } ,
author = { Yi Tay and Dara Bahri and Liu Yang and Donald Metzler and Da-Cheng Juan } ,
year = { 2020 } ,
url. = { https://arxiv.org/abs/2002.11296 }
} @inproceedings { kitaev2020reformer ,
title = { Reformer: The Efficient Transformer } ,
author = { Nikita Kitaev and Lukasz Kaiser and Anselm Levskaya } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=rkgNKkHtvB }
} @misc { lan2019albert ,
title = { ALBERT: A Lite BERT for Self-supervised Learning of Language Representations } ,
author = { Zhenzhong Lan and Mingda Chen and Sebastian Goodman and Kevin Gimpel and Piyush Sharma and Radu Soricut } ,
year = { 2019 } ,
url = { https://arxiv.org/abs/1909.11942 }
} @misc { shazeer2020glu ,
title = { GLU Variants Improve Transformer } ,
author = { Noam Shazeer } ,
year = { 2020 } ,
url = { https://arxiv.org/abs/2002.05202 }
} @misc { roy*2020efficient ,
title = { Efficient Content-Based Sparse Attention with Routing Transformers } ,
author = { Aurko Roy* and Mohammad Taghi Saffar* and David Grangier and Ashish Vaswani } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=B1gjs6EtDr }
} @inproceedings { fan2020reducing ,
title = { Reducing Transformer Depth on Demand with Structured Dropout } ,
author = { Angela Fan and Edouard Grave and Armand Joulin } ,
booktitle = { International Conference on Learning Representations } ,
year = { 2020 } ,
url = { https://openreview.net/forum?id=SylO2yStDr }
} @misc { lample2019large ,
title = { Large Memory Layers with Product Keys } ,
author = { Guillaume Lample and Alexandre Sablayrolles and Marc'Aurelio Ranzato and Ludovic Denoyer and Hervé Jégou } ,
year = { 2019 } ,
eprint = { 1907.05242 } ,
archivePrefix = { arXiv }
} @misc { bhojanapalli2020lowrank ,
title = { Low-Rank Bottleneck in Multi-head Attention Models } ,
author = { Srinadh Bhojanapalli and Chulhee Yun and Ankit Singh Rawat and Sashank J. Reddi and Sanjiv Kumar } ,
year = { 2020 } ,
eprint = { 2002.07028 }
}


