q transformer
0.3.0
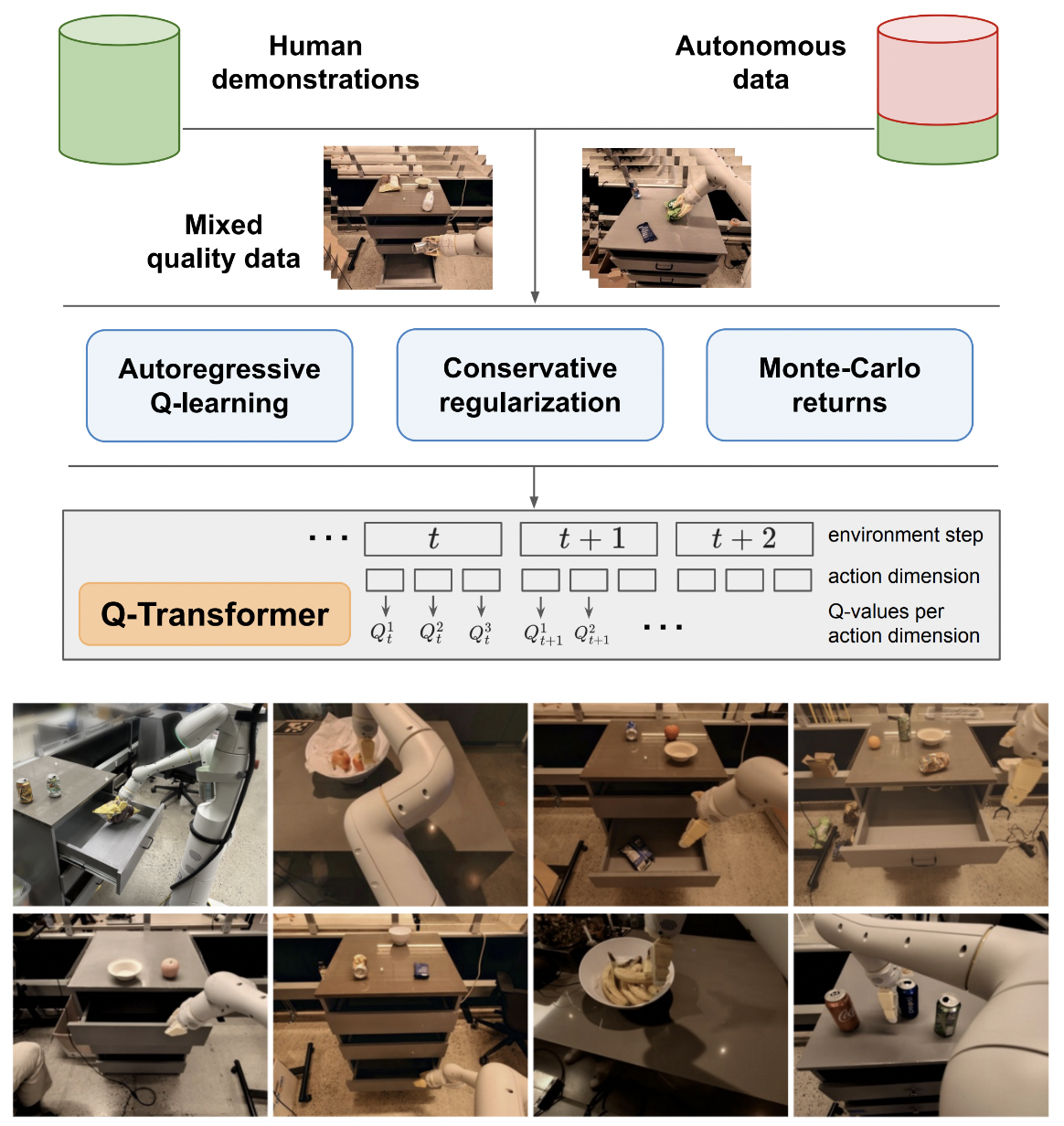
Implémentation de Q-Transformer, apprentissage par renforcement hors ligne évolutif via des fonctions Q autorégressives, à partir de Google Deepmind
Je garderai la logique du Q-learning sur une seule action juste pour une comparaison finale avec le Q-learning autorégressif proposé sur plusieurs actions. Aussi pour servir d’éducation pour moi-même et pour le public.
La formulation autorégressive du Q-learning a été reproduite par Kotb et al.
$ pip install q-transformer import torch
from q_transformer import (
QRoboticTransformer ,
QLearner ,
Agent ,
ReplayMemoryDataset
)
# the attention model
model = QRoboticTransformer (
vit = dict (
num_classes = 1000 ,
dim_conv_stem = 64 ,
dim = 64 ,
dim_head = 64 ,
depth = ( 2 , 2 , 5 , 2 ),
window_size = 7 ,
mbconv_expansion_rate = 4 ,
mbconv_shrinkage_rate = 0.25 ,
dropout = 0.1
),
num_actions = 8 ,
action_bins = 256 ,
depth = 1 ,
heads = 8 ,
dim_head = 64 ,
cond_drop_prob = 0.2 ,
dueling = True
)
# you need to supply your own environment, by overriding BaseEnvironment
from q_transformer . mocks import MockEnvironment
env = MockEnvironment (
state_shape = ( 3 , 6 , 224 , 224 ),
text_embed_shape = ( 768 ,)
)
# env.init() should return instructions and initial state: Tuple[str, Tensor[*state_shape]]
# env(actions) should return rewards, next state, and done flag: Tuple[Tensor[()], Tensor[*state_shape], Tensor[()]]
# agent is a class that allows the q-model to interact with the environment to generate a replay memory dataset for learning
agent = Agent (
model ,
environment = env ,
num_episodes = 1000 ,
max_num_steps_per_episode = 100 ,
)
agent ()
# Q learning on the replay memory dataset on the model
q_learner = QLearner (
model ,
dataset = ReplayMemoryDataset (),
num_train_steps = 10000 ,
learning_rate = 3e-4 ,
batch_size = 4 ,
grad_accum_every = 16 ,
)
q_learner ()
# after much learning
# your robot should be better at selecting optimal actions
video = torch . randn ( 2 , 3 , 6 , 224 , 224 )
instructions = [
'bring me that apple sitting on the table' ,
'please pass the butter'
]
actions = model . get_optimal_actions ( video , instructions )première étape vers un soutien à action unique
proposer une variante sans batchnorm de maxvit, comme dans le modèle météo SOTA metnet3
ajouter une architecture de duel profond en option
ajouter un apprentissage Q en n étapes
construire la régularisation conservatrice
construire la proposition principale sur papier (actions discrètes autorégressives jusqu'à la dernière action, récompense donnée uniquement pour la dernière)
improvisez une variante de tête de décodeur, au lieu de concaténer les actions précédentes au stade images + jetons appris. en d'autres termes, utilisez un encodeur-décodeur classique
refaire maxvit avec des intégrations rotatives axiales + un portail sigmoïde pour ne rien faire. activer l'attention flash pour maxvit avec ce changement
créer une classe de création d'ensemble de données simple, en prenant en compte l'environnement et le modèle et en renvoyant un dossier qui peut être accepté par un ReplayDataset
ReplayDataset qui prend dans le dossier gérer correctement plusieurs instructions
montrer un exemple simple de bout en bout, dans le même style que tous les autres dépôts
ne gère aucune instruction, exploite le conditionneur nul dans la bibliothèque CFG
cache kv pour le décodage des actions
pour l'exploration, permet de randomiser finement un sous-ensemble d'actions, et non toutes les actions à la fois
consultez des experts en RL et déterminez s'il existe de nouveaux progrès dans la résolution des préjugés délirants
déterminer si l'on peut s'entraîner avec des ordres d'actions aléatoires - l'ordre pourrait être envoyé sous forme de conditionnement concaténé ou additionné avant les couches d'attention
fonction de recherche de faisceau simple pour des actions optimales
improvisez une attention croisée sur les actions passées et les états de pas de temps, à la manière de Transformer-XL (avec abandon de mémoire structurée)
voyez si l'idée principale de cet article s'applique aux modèles de langage ici
@inproceedings { qtransformer ,
title = { Q-Transformer: Scalable Offline Reinforcement Learning via Autoregressive Q-Functions } ,
authors = { Yevgen Chebotar and Quan Vuong and Alex Irpan and Karol Hausman and Fei Xia and Yao Lu and Aviral Kumar and Tianhe Yu and Alexander Herzog and Karl Pertsch and Keerthana Gopalakrishnan and Julian Ibarz and Ofir Nachum and Sumedh Sontakke and Grecia Salazar and Huong T Tran and Jodilyn Peralta and Clayton Tan and Deeksha Manjunath and Jaspiar Singht and Brianna Zitkovich and Tomas Jackson and Kanishka Rao and Chelsea Finn and Sergey Levine } ,
booktitle = { 7th Annual Conference on Robot Learning } ,
year = { 2023 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Kumar2023MaintainingPI ,
title = { Maintaining Plasticity in Continual Learning via Regenerative Regularization } ,
author = { Saurabh Kumar and Henrik Marklund and Benjamin Van Roy } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:261076021 }
}

