perfusion pytorch
0.1.23
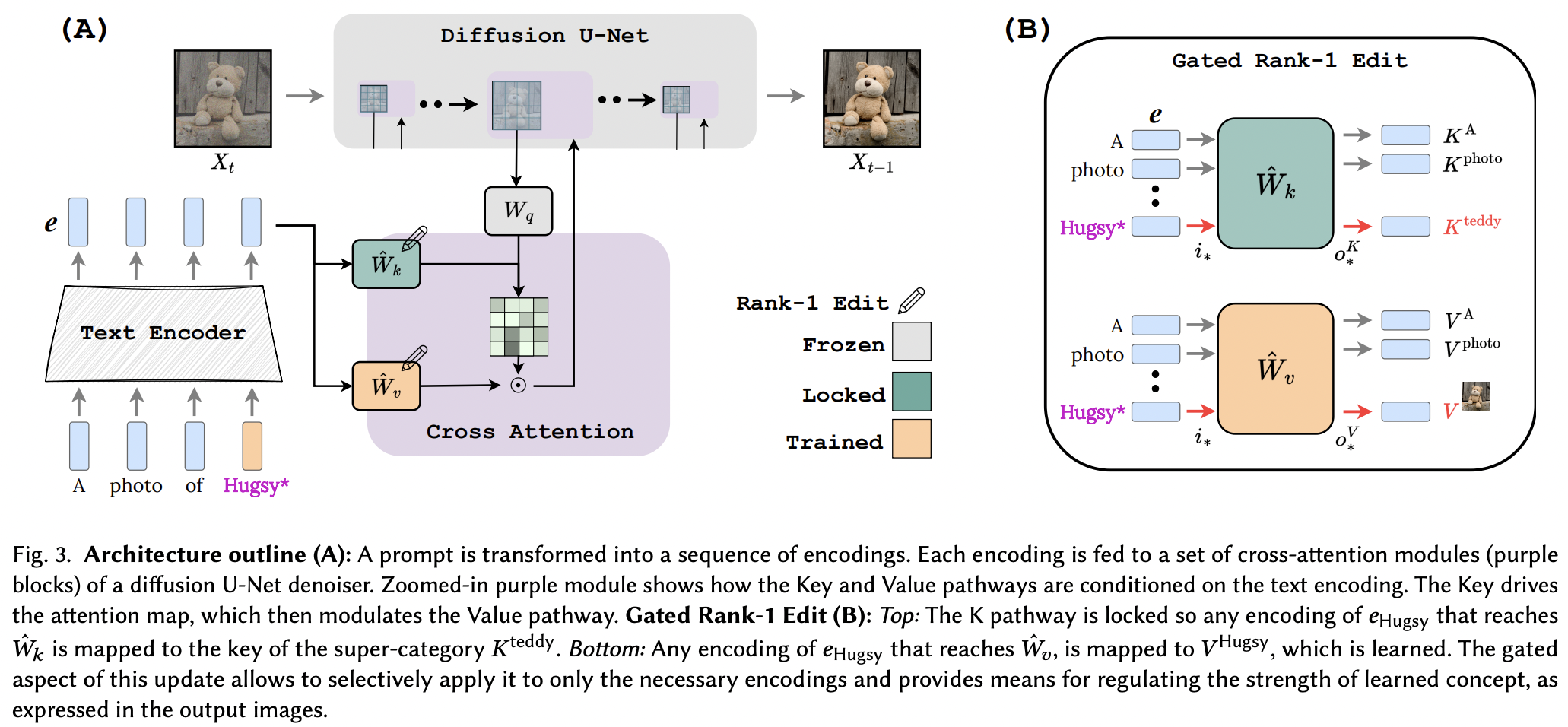
Implémentation de l'édition de rang un verrouillée par clé. Page du projet
L'argument de vente de cet article réside dans le fait que les paramètres supplémentaires par concept ajouté sont extrêmement faibles, jusqu'à 100 Ko.
Il semble qu'ils aient appliqué avec succès la technique d'édition de rang 1 à partir d'un article d'édition de mémoire pour LLM, avec quelques améliorations. Ils ont également identifié que les clés déterminent le « où » du nouveau concept, tandis que les valeurs déterminent le « quoi », et proposent un verrouillage par clé locale/globale sur un concept de superclasse (tout en apprenant les valeurs).
Pour les chercheurs, si cet article est vérifié, les outils de ce référentiel devraient fonctionner pour tout autre réseau texte-à- <insert modality> utilisant le conditionnement d'attention croisée. Juste une pensée
StabilityAI pour son généreux parrainage, ainsi que mes autres sponsors
Yoad Tewel pour les multiples révisions de code et les e-mails de clarification
Brad Vidler pour le précalcul de la matrice de covariance pour le CLIP utilisé dans Stable Diffusion 1.5 !
Tous les responsables d'OpenClip, pour leurs modèles texte-image d'apprentissage contrastif open source SOTA
$ pip install perfusion-pytorch import torch
from torch import nn
from perfusion_pytorch import Rank1EditModule
to_keys = nn . Linear ( 768 , 320 , bias = False )
to_values = nn . Linear ( 768 , 320 , bias = False )
wrapped_to_keys = Rank1EditModule (
to_keys ,
is_key_proj = True
)
wrapped_to_values = Rank1EditModule (
to_values
)
text_enc = torch . randn ( 4 , 77 , 768 ) # regular input
text_enc_with_superclass = torch . randn ( 4 , 77 , 768 ) # init_input in algorithm 1, for key-locking
concept_indices = torch . randint ( 0 , 77 , ( 4 ,)) # index where the concept or superclass concept token is in the sequence
key_pad_mask = torch . ones ( 4 , 77 ). bool ()
keys = wrapped_to_keys (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
values = wrapped_to_values (
text_enc ,
concept_indices = concept_indices ,
text_enc_with_superclass = text_enc_with_superclass ,
)
# after much training ...
wrapped_to_keys . eval ()
wrapped_to_values . eval ()
keys = wrapped_to_keys ( text_enc )
values = wrapped_to_values ( text_enc ) Le référentiel contient également un EmbeddingWrapper qui facilite la formation sur un nouveau concept (et pour une éventuelle inférence avec plusieurs concepts)
import torch
from torch import nn
from perfusion_pytorch import EmbeddingWrapper
embed = nn . Embedding ( 49408 , 512 ) # open clip embedding, somewhere in the module tree of stable diffusion
# wrap it, and will automatically create a new concept for learning, based on the superclass embed string
wrapped_embed = EmbeddingWrapper (
embed ,
superclass_string = 'dog'
)
# now just pass in your prompts with the superclass id
embeds_with_new_concept , embeds_with_superclass , embed_mask , concept_indices = wrapped_embed ([
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]) # (3, 77, 512), (3, 77, 512), (3, 77), (3,)
# now pass both embeds through clip text transformer
# the embed_mask needs to be passed to the cross attention as key padding mask Si vous pouvez identifier l'instance CLIP dans l'instance de diffusion stable, vous pouvez également la transmettre directement à OpenClipEmbedWrapper pour obtenir tout ce dont vous avez besoin pour les couches d'attention croisée.
ex.
from perfusion_pytorch import OpenClipEmbedWrapper
texts = [
'a portrait of dog' ,
'dog running through a green field' ,
'a man walking his dog'
]
wrapped_clip_with_new_concept = OpenClipEmbedWrapper (
stable_diffusion . path . to . clip ,
superclass_string = 'dog'
)
text_enc , superclass_enc , mask , indices = wrapped_clip_with_new_concept ( texts )
# (3, 77, 512), (3, 77, 512), (3, 77), (3,) connectez-vous avec SD 1.5, en commençant par le dreambooth-sd de xiao
montrer un exemple dans le fichier Lisez-moi pour une inférence avec plusieurs concepts
déduire automatiquement où se trouvent la projection des clés et des valeurs si elles ne sont pas spécifiées pour la fonction make_key_value_proj_rank1_edit_modules_
le wrapper d'intégration doit prendre soin de le remplacer par l'identifiant du jeton de super classe et renvoyer l'intégration avec la super classe
revoir plusieurs concepts - grâce à Yoad
offrir une fonction qui connecte l'attention croisée
gérer plusieurs concepts dans une seule invite lors de l'inférence - sommation du terme sigmoïde + sorties
offrir un moyen de combiner des concepts appris séparément à partir de plusieurs Rank1EditModule en un seul pour l'inférence
Rank1EditModule s ajouter le masquage zéro-shot du concept proposé dans l'article
prendre en charge la fonction qui prend en charge l'ensemble de données et l'encodeur de texte et précalcule la matrice de covariance nécessaire à la mise à jour de rang 1
au lieu de laisser le chercheur s'inquiéter des différents taux d'apprentissage, proposez l'astuce du gradient fractionnaire d'un autre article (pour apprendre le concept d'intégration)
@article { Tewel2023KeyLockedRO ,
title = { Key-Locked Rank One Editing for Text-to-Image Personalization } ,
author = { Yoad Tewel and Rinon Gal and Gal Chechik and Yuval Atzmon } ,
journal = { ACM SIGGRAPH 2023 Conference Proceedings } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:258436985 }
} @inproceedings { Meng2022LocatingAE ,
title = { Locating and Editing Factual Associations in GPT } ,
author = { Kevin Meng and David Bau and Alex Andonian and Yonatan Belinkov } ,
booktitle = { Neural Information Processing Systems } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:255825985 }
}

