rtdl revisiting models
1.0.0
Important
Découvrez le nouveau modèle DL tabulaire : TabM
arXiv ? Paquet PythonAutres projets DL tabulaires
Il s'agit de la mise en œuvre officielle de l'article « Revisiting Deep Learning Models for Tabular Data ».
En une phrase : les modèles de type MLP constituent toujours de bonnes bases de référence, et FT-Transformer est une nouvelle adaptation puissante de l'architecture Transformer pour les problèmes de données tabulaires.
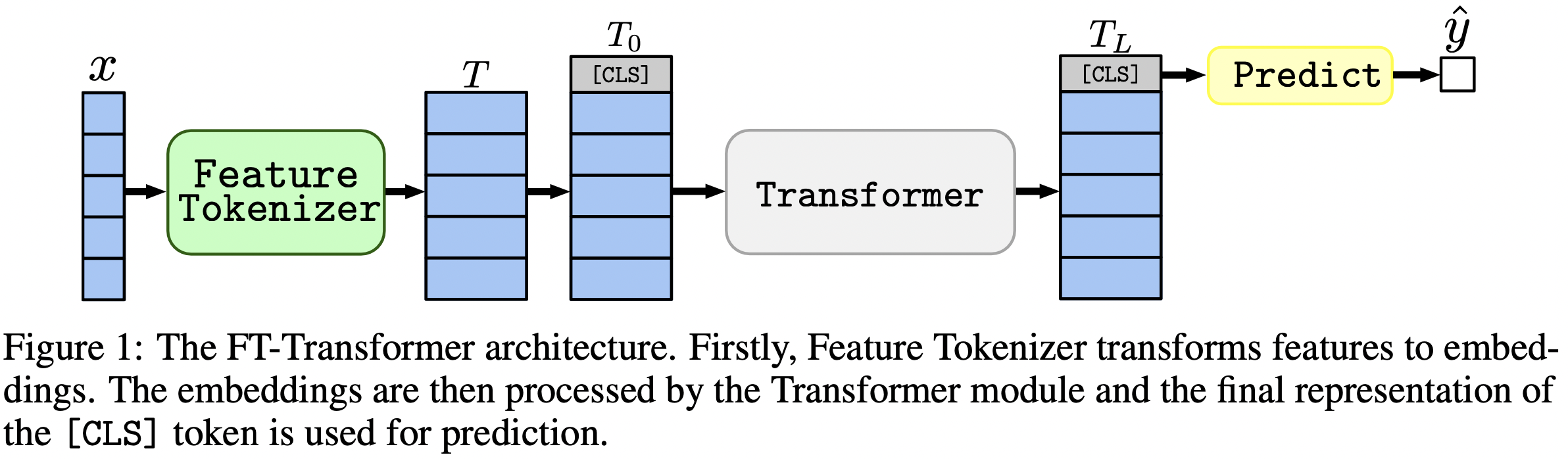
L'article se concentre sur les architectures pour les problèmes de données tabulaires. Les résultats:
Le package Python dans le répertoire package/ est la manière recommandée pour utiliser le document dans la pratique et pour les travaux futurs.
Le reste du document :
Le répertoire output/ contient de nombreux résultats et hyperparamètres (ajustés) pour divers modèles et ensembles de données utilisés dans l'article.
Par exemple, explorons les métriques du modèle MLP. Tout d'abord, chargeons les rapports (les fichiers stats.json ) :
import json
from pathlib import Path
import pandas as pd
df = pd . json_normalize ([
json . loads ( x . read_text ())
for x in Path ( 'output' ). glob ( '*/mlp/tuned/*/stats.json' )
])Maintenant, pour chaque ensemble de données, calculons la moyenne du score du test sur toutes les graines aléatoires :
print ( df . groupby ( 'dataset' )[ 'metrics.test.score' ]. mean (). round ( 3 ))Le résultat correspond exactement au tableau 2 de l'article :
dataset
adult 0.852
aloi 0.954
california_housing -0.499
covtype 0.962
epsilon 0.898
helena 0.383
higgs_small 0.723
jannis 0.719
microsoft -0.747
yahoo -0.757
year -8.853
Name: metrics.test.score, dtype: float64
L'approche ci-dessus peut également être utilisée pour explorer les hyperparamètres afin d'avoir une intuition sur les valeurs d'hyperparamètres typiques pour différents algorithmes. Par exemple, voici comment calculer le taux d'apprentissage médian ajusté pour le modèle MLP :
Note
Pour certains algorithmes (par exemple MLP), des projets plus récents offrent davantage de résultats pouvant être explorés de manière similaire. Par exemple, consultez cet article sur TabR.
Avertissement
Utilisez cette approche avec prudence. Lors de l'étude des valeurs d'hyperparamètres :
print ( df [ df [ 'config.seed' ] == 0 ][ 'config.training.lr' ]. quantile ( 0.5 ))
# Output: 0.0002161505605899536Note
Cette section est longue. Utilisez la fonctionnalité « Aperçu » sur GitHub dans votre éditeur de texte pour avoir un aperçu de cette section.
Le code est organisé comme suit :
bin :ensemble.py effectue l'assemblagetune.py effectue le réglage des hyperparamètresanalysis_gbdt_vs_nn.py exécute les expériencescreate_synthetic_data_plots.py construit des tracéslib contient des outils courants utilisés par les programmes dans binoutput contient des fichiers de configuration (entrées pour les programmes dans bin ) et des résultats (métriques, configurations optimisées, etc.)package contient le package Python pour cet article Installer Conda
export PROJECT_DIR= < ABSOLUTE path to the repository root >
# example: export PROJECT_DIR=/home/myusername/repositories/revisiting-models
git clone https://github.com/yandex-research/tabular-dl-revisiting-models $PROJECT_DIR
cd $PROJECT_DIR
conda create -n revisiting-models python=3.8.8
conda activate revisiting-models
conda install pytorch==1.7.1 torchvision==0.8.2 cudatoolkit=10.1.243 numpy=1.19.2 -c pytorch -y
conda install cudnn=7.6.5 -c anaconda -y
pip install -r requirements.txt
conda install nodejs -y
jupyter labextension install @jupyter-widgets/jupyterlab-manager
# if the following commands do not succeed, update conda
conda env config vars set PYTHONPATH= ${PYTHONPATH} : ${PROJECT_DIR}
conda env config vars set PROJECT_DIR= ${PROJECT_DIR}
conda env config vars set LD_LIBRARY_PATH= ${CONDA_PREFIX} /lib: ${LD_LIBRARY_PATH}
conda env config vars set CUDA_HOME= ${CONDA_PREFIX}
conda env config vars set CUDA_ROOT= ${CONDA_PREFIX}
conda deactivate
conda activate revisiting-modelsCet environnement est nécessaire uniquement pour expérimenter TabNet. Pour tous les autres cas, utilisez l'environnement PyTorch.
Les instructions sont les mêmes que pour l'environnement PyTorch (y compris l'installation de PyTorch !), mais :
python=3.7.10cudatoolkit=10.0pip install -r requirements.txt procédez comme suit :pip install tensorflow-gpu==1.14tensorboard dans requirements.txtLICENCE : en téléchargeant notre ensemble de données, vous acceptez les licences de tous ses composants. Nous n'imposons aucune nouvelle restriction en plus de ces licences. Vous pouvez trouver la liste des sources dans la section « Références » de notre article.
wget https://www.dropbox.com/s/o53umyg6mn3zhxy/data.tar.gz?dl=1 -O revisiting_models_data.tar.gzmv revisiting_models_data.tar.gz $PROJECT_DIRcd $PROJECT_DIRtar -xvf revisiting_models_data.tar.gz Cette section ne fournit que des commandes spécifiques avec quelques commentaires. Après avoir terminé le didacticiel, nous vous recommandons de consulter la section suivante pour mieux comprendre comment utiliser le référentiel. Cela aidera également à mieux comprendre le didacticiel.
Dans ce didacticiel, nous reproduirons les résultats du MLP sur l'ensemble de données California Housing. Nous couvrirons :
Notez que les chances d’obtenir exactement les mêmes résultats sont plutôt faibles, mais elles ne devraient pas beaucoup différer des nôtres. Avant d'exécuter quoi que ce soit, accédez à la racine du référentiel et définissez explicitement CUDA_VISIBLE_DEVICES (si vous prévoyez d'utiliser GPU) :
cd $PROJECT_DIR
export CUDA_VISIBLE_DEVICES=0Avant de commencer, vérifions que l'environnement est configuré avec succès. Les commandes suivantes doivent entraîner un MLP sur l'ensemble de données California Housing :
mkdir draft
cp output/california_housing/mlp/tuned/0.toml draft/check_environment.toml
python bin/mlp.py draft/check_environment.toml Le résultat doit être dans le répertoire draft/check_environment . Pour l’instant, le contenu du résultat n’a pas d’importance.
Notre configuration pour régler MLP sur l'ensemble de données California Housing se trouve dans output/california_housing/mlp/tuning/0.toml . Afin de reproduire le réglage, copiez notre config et lancez votre réglage :
# you can choose any other name instead of "reproduced.toml"; it is better to keep this
# name while completing the tutorial
cp output/california_housing/mlp/tuning/0.toml output/california_housing/mlp/tuning/reproduced.toml
# let's reduce the number of tuning iterations to make tuning fast (and ineffective)
python -c "
from pathlib import Path
p = Path('output/california_housing/mlp/tuning/reproduced.toml')
p.write_text(p.read_text().replace('n_trials = 100', 'n_trials = 5'))
"
python bin/tune.py output/california_housing/mlp/tuning/reproduced.toml Le résultat de votre réglage se trouvera dans output/california_housing/mlp/tuning/reproduced , vous pourrez le comparer avec le nôtre : output/california_housing/mlp/tuning/0 . Le fichier best.toml contient la meilleure configuration que nous évaluerons dans la section suivante.
Nous devons maintenant évaluer la configuration optimisée avec 15 graines aléatoires différentes.
# create a directory for evaluation
mkdir -p output/california_housing/mlp/tuned_reproduced
# clone the best config from the tuning stage with 15 different random seeds
python -c "
for seed in range(15):
open(f'output/california_housing/mlp/tuned_reproduced/{seed}.toml', 'w').write(
open('output/california_housing/mlp/tuning/reproduced/best.toml').read().replace('seed = 0', f'seed = {seed}')
)
"
# train MLP with all 15 configs
for seed in {0..14}
do
python bin/mlp.py output/california_housing/mlp/tuned_reproduced/ ${seed} .toml
done Notre répertoire avec les résultats de l'évaluation se trouve juste à côté du vôtre, à savoir à output/california_housing/mlp/tuned .
# just run this single command
python bin/ensemble.py mlp output/california_housing/mlp/tuned_reproduced Vos résultats se trouveront dans output/california_housing/mlp/tuned_reproduced_ensemble , vous pourrez les comparer avec les nôtres : output/california_housing/mlp/tuned_ensemble .
Utilisez l'approche décrite ici pour résumer les résultats de l'expérience menée (modifiez le filtre de chemin dans .glob(...) en conséquence : tuned -> tuned_reproduced ).
Des étapes similaires peuvent être effectuées pour tous les modèles et ensembles de données. Le processus de réglage est légèrement différent dans le cas d'une recherche sur grille : vous devez exécuter toutes les configurations souhaitées et choisir manuellement la meilleure en fonction des performances de validation . Par exemple, voir output/epsilon/ft_transformer .
Vous devez exécuter des scripts Python à partir de la racine du référentiel. La plupart des programmes attendent un fichier de configuration comme seul argument. La sortie sera un répertoire portant le même nom que la configuration, mais sans l'extension. Les configurations sont écrites en TOML. Les listes d'arguments possibles pour les programmes ne sont pas fournies et doivent être déduites des scripts (généralement, la configuration est représentée avec la variable args dans les scripts). Si vous souhaitez utiliser CUDA, vous devez définir explicitement la variable d'environnement CUDA_VISIBLE_DEVICES . Par exemple:
# The result will be at "path/to/my_experiment"
CUDA_VISIBLE_DEVICES=0 python bin/mlp.py path/to/my_experiment.toml
# The following example will run WITHOUT CUDA
python bin/mlp.py path/to/my_experiment.tomlSi vous comptez utiliser CUDA tout le temps, vous pouvez enregistrer la variable d'environnement dans l'environnement Conda :
conda env config vars set CUDA_VISIBLE_DEVICES= " 0 " L'option -f ( --force ) supprimera les résultats existants et exécutera le script à partir de zéro :
python bin/whatever.py path/to/config.toml -f # rewrites path/to/config bin/tune.py prend en charge la suite :
python bin/tune.py path/to/config.toml --continuestats.json et autres résultats Pour tous les scripts, stats.json est la partie la plus importante de la sortie. Le contenu varie d'un programme à l'autre. Il peut contenir :
Les prédictions pour les ensembles d’entraînement, de validation et de test sont généralement également enregistrées.
Vous savez désormais tout ce dont vous avez besoin pour reproduire tous les résultats et étendre ce référentiel selon vos besoins. Le tutoriel devrait également être plus clair maintenant. N'hésitez pas à ouvrir des problèmes et à poser des questions.
@inproceedings{gorishniy2021revisiting,
title={Revisiting Deep Learning Models for Tabular Data},
author={Yury Gorishniy and Ivan Rubachev and Valentin Khrulkov and Artem Babenko},
booktitle={{NeurIPS}},
year={2021},
}


