video diffusion pytorch
0.7.0
ces feux d'artifice n'existent pas
Du texte à la vidéo, ça arrive ! Page officielle du projet
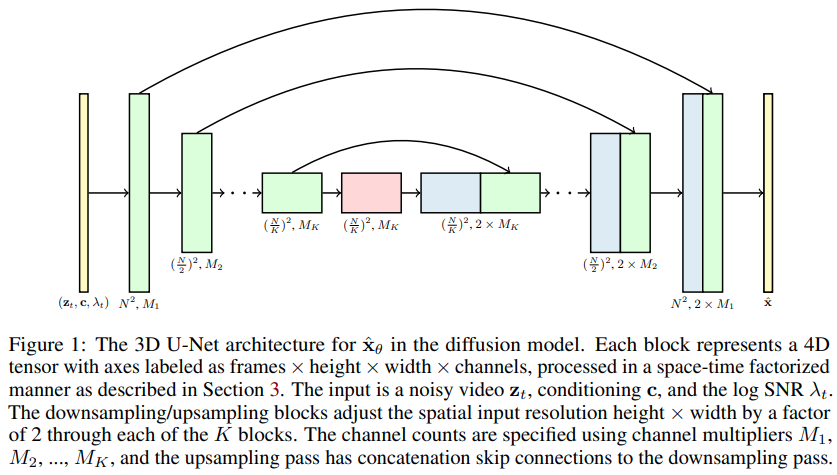
Implémentation de modèles de diffusion vidéo, le nouvel article de Jonathan Ho étendant les DDPM à la génération vidéo - dans Pytorch. Il utilise un réseau U spécial à facteur spatio-temporel, étendant la génération d'images 2D aux vidéos 3D.
14k pour les mouvements difficiles (convergence beaucoup plus rapide et meilleure que NUWA) - wip

Les expériences ci-dessus ne sont possibles que grâce aux ressources fournies par Stability.ai
Tout nouveau développement pour la synthèse texte-vidéo sera centralisé chez Imagen-pytorch
$ pip install video-diffusion-pytorch import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 1 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width) - normalized from -1 to +1
loss = diffusion ( videos )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( batch_size = 4 )
sampled_videos . shape # (4, 3, 5, 32, 32)Pour conditionner le texte, ils ont dérivé des intégrations de texte en passant d'abord le texte tokenisé via BERT-large. Ensuite, tu dois juste l'entraîner comme ça
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
cond_dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 )
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 ,
num_frames = 5 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 2 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = torch . randn ( 2 , 64 ) # assume output of BERT-large has dimension of 64
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text )
sampled_videos . shape # (2, 3, 5, 32, 32)Vous pouvez également transmettre directement les descriptions de la vidéo sous forme de chaînes, si vous prévoyez d'utiliser la base BERT pour le conditionnement de texte.
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion
model = Unet3D (
dim = 64 ,
use_bert_text_cond = True , # this must be set to True to auto-use the bert model dimensions
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 32 , # height and width of frames
num_frames = 5 , # number of video frames
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
)
videos = torch . randn ( 3 , 3 , 5 , 32 , 32 ) # video (batch, channels, frames, height, width)
text = [
'a whale breaching from afar' ,
'young girl blowing out candles on her birthday cake' ,
'fireworks with blue and green sparkles'
]
loss = diffusion ( videos , cond = text )
loss . backward ()
# after a lot of training
sampled_videos = diffusion . sample ( cond = text , cond_scale = 2 )
sampled_videos . shape # (3, 3, 5, 32, 32) Ce référentiel contient également une classe Trainer pratique pour s'entraîner sur un dossier de gifs . Chaque gif doit avoir les dimensions correctes image_size et num_frames .
import torch
from video_diffusion_pytorch import Unet3D , GaussianDiffusion , Trainer
model = Unet3D (
dim = 64 ,
dim_mults = ( 1 , 2 , 4 , 8 ),
)
diffusion = GaussianDiffusion (
model ,
image_size = 64 ,
num_frames = 10 ,
timesteps = 1000 , # number of steps
loss_type = 'l1' # L1 or L2
). cuda ()
trainer = Trainer (
diffusion ,
'./data' , # this folder path needs to contain all your training data, as .gif files, of correct image size and number of frames
train_batch_size = 32 ,
train_lr = 1e-4 ,
save_and_sample_every = 1000 ,
train_num_steps = 700000 , # total training steps
gradient_accumulate_every = 2 , # gradient accumulation steps
ema_decay = 0.995 , # exponential moving average decay
amp = True # turn on mixed precision
)
trainer . train () Des exemples de vidéos (sous forme de fichiers gif ) seront enregistrés périodiquement dans ./results , tout comme les paramètres du modèle de diffusion.
L'une des affirmations de l'article est qu'en effectuant une attention spatio-temporelle pondérée, on peut forcer le réseau à se concentrer sur le présent pour former les images et les vidéos en conjonction, ce qui conduit à de meilleurs résultats.
On ne sait pas exactement comment ils y sont parvenus, mais j'ai avancé une hypothèse.
Pour attirer l'attention sur le moment présent pour un certain pourcentage d'échantillons de vidéos par lots, transmettez simplement prob_focus_present = <prob> sur la méthode de diffusion directe
loss = diffusion ( videos , cond = text , prob_focus_present = 0.5 ) # for 50% of videos, focus on the present during training
loss . backward ()Si vous avez une meilleure idée de la façon dont cela se fait, ouvrez simplement un ticket github.
@misc { ho2022video ,
title = { Video Diffusion Models } ,
author = { Jonathan Ho and Tim Salimans and Alexey Gritsenko and William Chan and Mohammad Norouzi and David J. Fleet } ,
year = { 2022 } ,
eprint = { 2204.03458 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @misc { Saharia2022 ,
title = { Imagen: unprecedented photorealism × deep level of language understanding } ,
author = { Chitwan Saharia*, William Chan*, Saurabh Saxena†, Lala Li†, Jay Whang†, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho†, David Fleet†, Mohammad Norouzi* } ,
year = { 2022 }
}

