PALM E
0.0.4

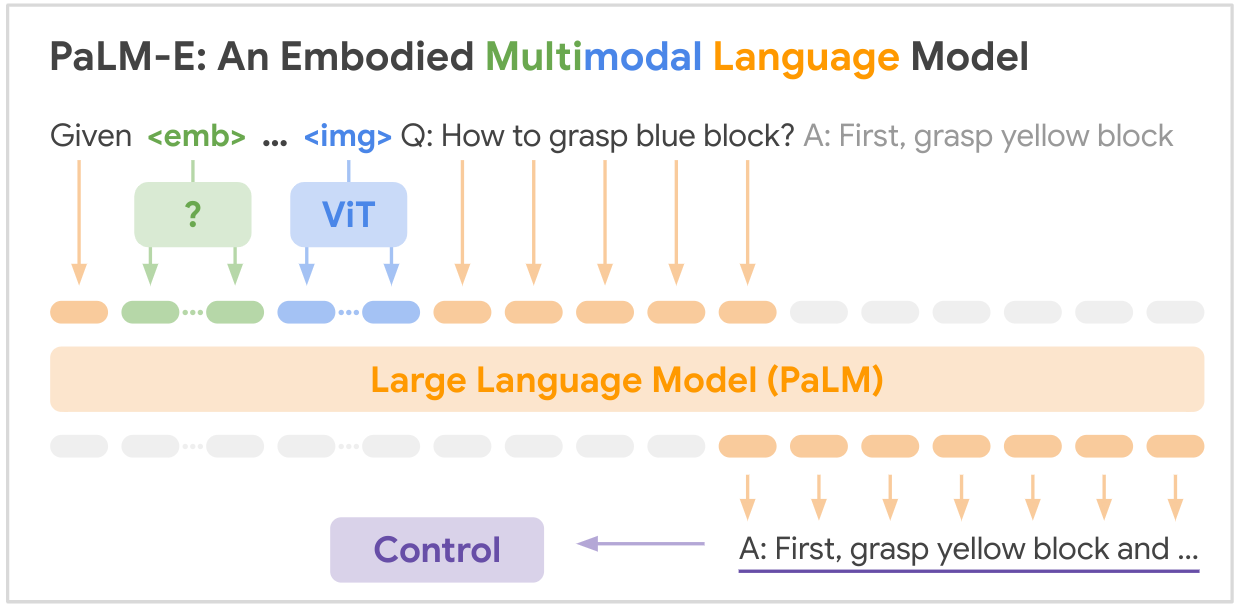
Il s'agit de l'implémentation open source du modèle de base multimodal SOTA « PALM-E : An Embodied Multimodal Language Model » de Google. PALM-E est un grand modèle multimodal incorporé unique, qui peut répondre à une variété de tâches de raisonnement incorporées, de une variété de modalités d'observation, sur de multiples modes de réalisation, et présente en outre un transfert positif : le modèle bénéficie d'une formation conjointe diversifiée dans les domaines du langage, de la vision et du langage visuel à l'échelle d'Internet.
LIEN PAPIER : PaLM-E : un modèle de langage multimodal incorporé
pip install palme import torch
from palme . model import PalmE
#usage
img = torch . randn ( 1 , 3 , 256 , 256 )
caption = torch . randint ( 0 , 20000 , ( 1 , 1024 ))
model = PalmE ()
output = model ( img , caption )
print ( output . shape ) # (1, 1024, 20000)
Voici un tableau récapitulatif des principaux ensembles de données mentionnés dans le document :
| Ensemble de données | Tâches | Taille | Lien |
|---|---|---|---|
| TASSER | Planification des manipulations robotiques, VQA | 96 000 scènes | Ensemble de données personnalisé |
| Tableau des langues | Planification de la manipulation robotique | Ensemble de données personnalisé | Lien |
| Manipulations mobiles | Planification de la navigation et des manipulations robotiques, VQA | 2912 séquences | Basé sur l'ensemble de données SayCan |
| WebLI | Récupération image-texte | 66 millions de paires image-légende | Lien |
| VQAv2 | Réponse visuelle aux questions | 1,1 million de questions sur les images COCO | Lien |
| OK-VQA | Réponse visuelle aux questions nécessitant des connaissances externes | 14 031 questions sur les images COCO | Lien |
| COCO | Légende des images | 330 000 images avec légendes | Lien |
| Wikipédia | Corpus de texte | N / A | Lien |
Les principaux ensembles de données robotiques ont été collectés spécifiquement pour ce travail, tandis que les ensembles de données de langage de vision plus vastes (WebLI, VQAv2, OK-VQA, COCO) constituent des références standard dans ce domaine. Les ensembles de données vont de dizaines de milliers d'exemples pour les domaines de la robotique à des dizaines de millions pour les données de langage de vision à l'échelle Internet.
Votre génie est nécessaire ! Rejoignez-nous et ensemble, rendons PALM-E encore plus impressionnant :
? Des correctifs, ? améliorations, documents ou idées : tous sont les bienvenus ! Façonnons l’avenir de l’IA, main dans la main.
@article{driess2023palme,
title={PALM-E: An Embodied Multimodal Language Model},
author={Driess, Danny and Xia, Fei and Sajjadi, Mehdi S. M. and Lynch, Corey and Chowdhery, Aakanksha and Ichter, Brian and Wahid, Ayzaan and Tompson, Jonathan and Vuong, Quan and Yu, Tianhe and Huang, Wenlong and Chebotar, Yevgen and Sermanet, Pierre and Duckworth, Daniel and Levine, Sergey and Vanhoucke, Vincent and Hausman, Karol and Toussaint, Marc and Greff, Klaus and Zeng, Andy and Mordatch, Igor and Florence, Pete},
journal={arXiv preprint arXiv:2303.03378},
year={2023},
url={https://doi.org/10.48550/arXiv.2303.03378}
}

