meshgpt pytorch
1.8.1
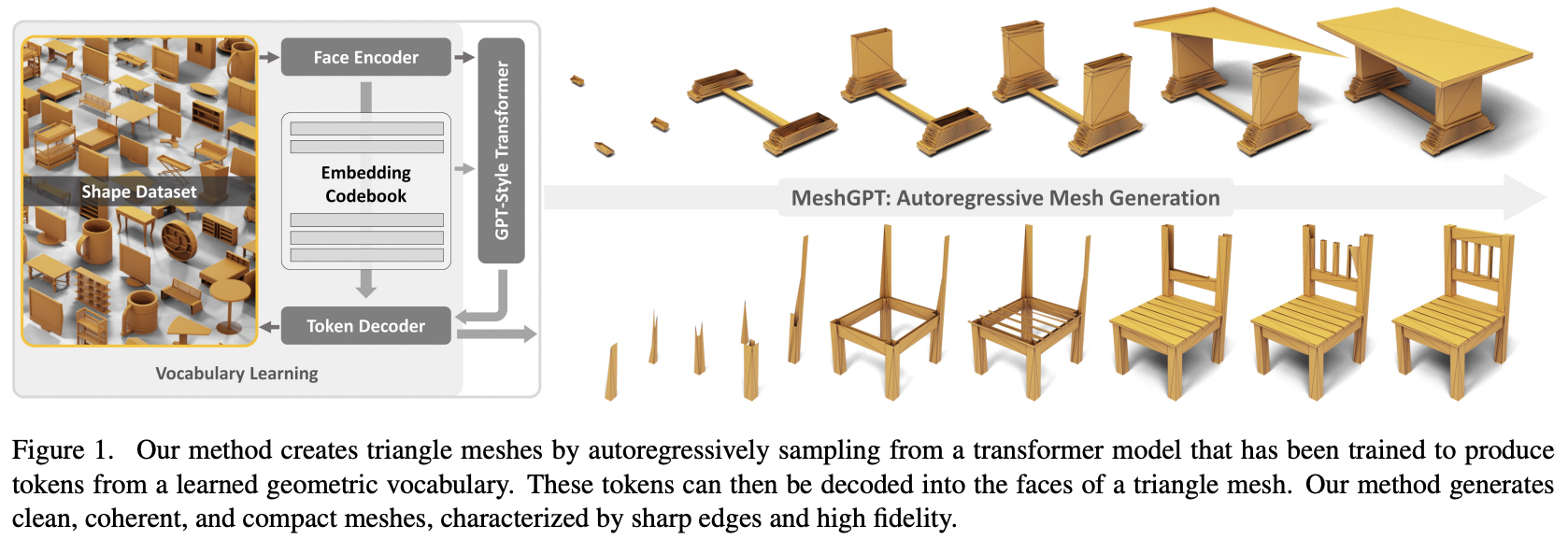
Implémentation de MeshGPT, génération SOTA Mesh à l'aide d'Attention, dans Pytorch
Ajoutera également un conditionnement de texte, pour un éventuel élément texte en 3D
Veuillez nous rejoindre si vous souhaitez collaborer avec d'autres pour reproduire ce travail
Mise à jour : Marcus a formé et téléchargé un modèle fonctionnel sur ? Visage câlin !
StabilityAI, programme de subventions d'IA Open Source A16Z et ? Huggingface pour les généreux parrainages, ainsi que mes autres sponsors, pour m'avoir donné l'indépendance nécessaire à la recherche open source actuelle sur l'intelligence artificielle.
Einops pour m'avoir rendu la vie facile
Marcus pour la révision initiale du code (en soulignant certaines fonctionnalités dérivées manquantes) ainsi que pour l'exécution des premières expériences réussies de bout en bout
Marcus pour la première formation réussie d'une collection de formes conditionnées sur des étiquettes
Quexi Ma pour avoir trouvé de nombreux bugs avec la gestion automatique d'eos
Yingtian pour avoir trouvé un bug avec le flou gaussien des positions pour le lissage spatial des étiquettes
Marcus encore une fois pour avoir mené les expériences pour valider qu'il est possible d'étendre le système des triangles aux quads
Marcus pour avoir identifié un problème avec le conditionnement du texte et pour avoir mené toutes les expériences qui ont conduit à sa résolution
$ pip install meshgpt-pytorch import torch
from meshgpt_pytorch import (
MeshAutoencoder ,
MeshTransformer
)
# autoencoder
autoencoder = MeshAutoencoder (
num_discrete_coors = 128
)
# mock inputs
vertices = torch . randn (( 2 , 121 , 3 )) # (batch, num vertices, coor (3))
faces = torch . randint ( 0 , 121 , ( 2 , 64 , 3 )) # (batch, num faces, vertices (3))
# make sure faces are padded with `-1` for variable lengthed meshes
# forward in the faces
loss = autoencoder (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training...
# you can pass in the raw face data above to train a transformer to model this sequence of face vertices
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768
)
loss = transformer (
vertices = vertices ,
faces = faces
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets
faces_coordinates , face_mask = transformer . generate ()
# (batch, num faces, vertices (3), coordinates (3)), (batch, num faces)
# now post process for the generated 3d asset Pour la synthèse de formes 3D conditionnée par le texte, définissez simplement condition_on_text = True sur votre MeshTransformer , puis transmettez votre liste de descriptions comme argument de mot-clé texts
ex.
transformer = MeshTransformer (
autoencoder ,
dim = 512 ,
max_seq_len = 768 ,
condition_on_text = True
)
loss = transformer (
vertices = vertices ,
faces = faces ,
texts = [ 'a high chair' , 'a small teapot' ],
)
loss . backward ()
# after much training of transformer, you can now sample novel 3d assets conditioned on text
faces_coordinates , face_mask = transformer . generate (
texts = [ 'a long table' ],
cond_scale = 8. , # a cond_scale > 1. will enable classifier free guidance - can be placed anywhere from 3. - 10.
remove_parallel_component = True # from https://arxiv.org/abs/2410.02416
) Si vous souhaitez tokeniser des maillages, pour les utiliser dans votre transformateur multimodal, invoquez simplement .tokenize sur votre auto-encodeur (ou la même méthode sur l'instance d'entraînement de l'auto-encodeur pour le modèle lissé exponentiellement)
mesh_token_ids = autoencoder . tokenize (
vertices = vertices ,
faces = faces
)
# (batch, num face vertices, residual quantized layer) À la racine du projet, exécutez
$ cp .env.sample .envencodeur automatique
face_edges directement à partir des faces et des sommets transformateur
emballage d'entraînement avec accélération hf
conditionnement de texte à l'aide de sa propre bibliothèque CFG
transformateurs hiérarchiques (utilisant le transformateur RQ)
correction de la mise en cache dans une simple couche gateloop dans un autre dépôt
attention locale
correction de la mise en cache kv pour le transformateur hiérarchique à deux étages - 7 fois plus rapide maintenant et plus rapide que le transformateur non hiérarchique d'origine
correction de la mise en cache pour les couches gateloop
permettre la personnalisation des dimensions du modèle du réseau d'attention fin ou grossier
déterminer si l'auto-encodeur est vraiment nécessaire - c'est nécessaire, les ablations sont dans le papier
rendre le transformateur efficace
option de décodage spéculatif
passer une journée sur la documentation
@inproceedings { Siddiqui2023MeshGPTGT ,
title = { MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers } ,
author = { Yawar Siddiqui and Antonio Alliegro and Alexey Artemov and Tatiana Tommasi and Daniele Sirigatti and Vladislav Rosov and Angela Dai and Matthias Nie{ss}ner } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265457242 }
} @inproceedings { dao2022flashattention ,
title = { Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness } ,
author = { Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher } ,
booktitle = { Advances in Neural Information Processing Systems } ,
year = { 2022 }
} @inproceedings { Leviathan2022FastIF ,
title = { Fast Inference from Transformers via Speculative Decoding } ,
author = { Yaniv Leviathan and Matan Kalman and Y. Matias } ,
booktitle = { International Conference on Machine Learning } ,
year = { 2022 } ,
url = { https://api.semanticscholar.org/CorpusID:254096365 }
} @misc { yu2023language ,
title = { Language Model Beats Diffusion -- Tokenizer is Key to Visual Generation } ,
author = { Lijun Yu and José Lezama and Nitesh B. Gundavarapu and Luca Versari and Kihyuk Sohn and David Minnen and Yong Cheng and Agrim Gupta and Xiuye Gu and Alexander G. Hauptmann and Boqing Gong and Ming-Hsuan Yang and Irfan Essa and David A. Ross and Lu Jiang } ,
year = { 2023 } ,
eprint = { 2310.05737 } ,
archivePrefix = { arXiv } ,
primaryClass = { cs.CV }
} @article { Lee2022AutoregressiveIG ,
title = { Autoregressive Image Generation using Residual Quantization } ,
author = { Doyup Lee and Chiheon Kim and Saehoon Kim and Minsu Cho and Wook-Shin Han } ,
journal = { 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) } ,
year = { 2022 } ,
pages = { 11513-11522 } ,
url = { https://api.semanticscholar.org/CorpusID:247244535 }
} @inproceedings { Katsch2023GateLoopFD ,
title = { GateLoop: Fully Data-Controlled Linear Recurrence for Sequence Modeling } ,
author = { Tobias Katsch } ,
year = { 2023 } ,
url = { https://api.semanticscholar.org/CorpusID:265018962 }
}

