algebraic nnhw
1.0.0
Ce référentiel contient le code source des architectures matérielles ML qui nécessitent près de la moitié du nombre d'unités multiplicatrices pour obtenir les mêmes performances, en exécutant des algorithmes de produits internes alternatifs qui échangent près de la moitié des multiplications contre des ajouts bon marché de faible largeur de bit, tout en produisant une sortie identique. comme le produit intérieur conventionnel. Cela augmente les limites théoriques de débit et d’efficacité de calcul des accélérateurs ML. Voir la publication de la revue suivante pour plus de détails :
TE Pogue et N. Nicolici, « Algorithmes et architectures rapides de produits internes pour les accélérateurs de réseaux neuronaux profonds », dans IEEE Transactions on Computers, vol. 73, non. 2, pp. 495-509, février 2024, doi : 10.1109/TC.2023.3334140.
URL de l'article : https://ieeexplore.ieee.org/document/10323219
Version en libre accès : https://arxiv.org/abs/2311.12224
Résumé : Nous introduisons un nouvel algorithme appelé FFIP (Free-pipeline Fast Inner Product) et son architecture matérielle qui améliorent un algorithme de produit interne rapide (FIP) sous-exploré proposé par Winograd en 1968. Contrairement aux algorithmes de filtrage minimal sans rapport de Winograd pour couches convolutives, FIP est applicable à toutes les couches de modèle d'apprentissage automatique (ML) qui peuvent principalement se décomposer en multiplication matricielle, y compris les couches entièrement connectées, convolutives, récurrentes et d'attention/transformateur. Nous implémentons FIP pour la première fois dans un accélérateur ML, puis présentons notre algorithme FFIP et notre architecture généralisée qui améliorent intrinsèquement la fréquence d'horloge de FIP et, par conséquent, le débit pour un coût matériel similaire. Enfin, nous apportons des optimisations spécifiques au ML pour les algorithmes et architectures FIP et FFIP. Nous montrons que FFIP peut être intégré de manière transparente dans les accélérateurs ML systoliques à virgule fixe traditionnels pour atteindre le même débit avec la moitié du nombre d'unités de multiplication-accumulation (MAC), ou il peut doubler la taille maximale du réseau systolique pouvant s'adapter aux appareils avec un budget matériel fixe. Notre implémentation FFIP pour les modèles ML non clairsemés avec des entrées à virgule fixe de 8 à 16 bits atteint un débit et une efficacité de calcul plus élevés que les meilleures solutions précédentes de leur catégorie sur le même type de plate-forme de calcul.
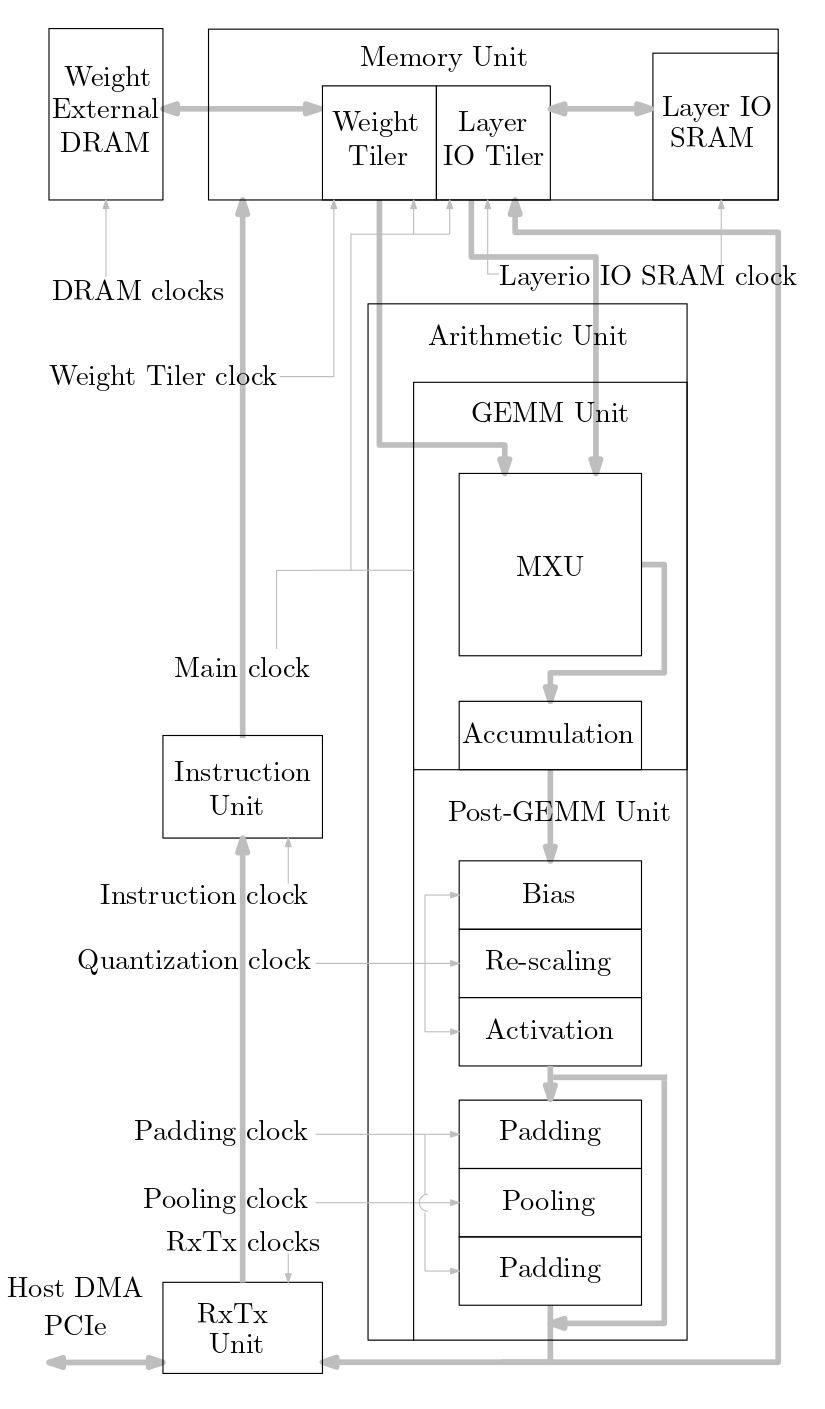
Le diagramme suivant montre un aperçu du système d'accélérateur ML implémenté dans ce code source :
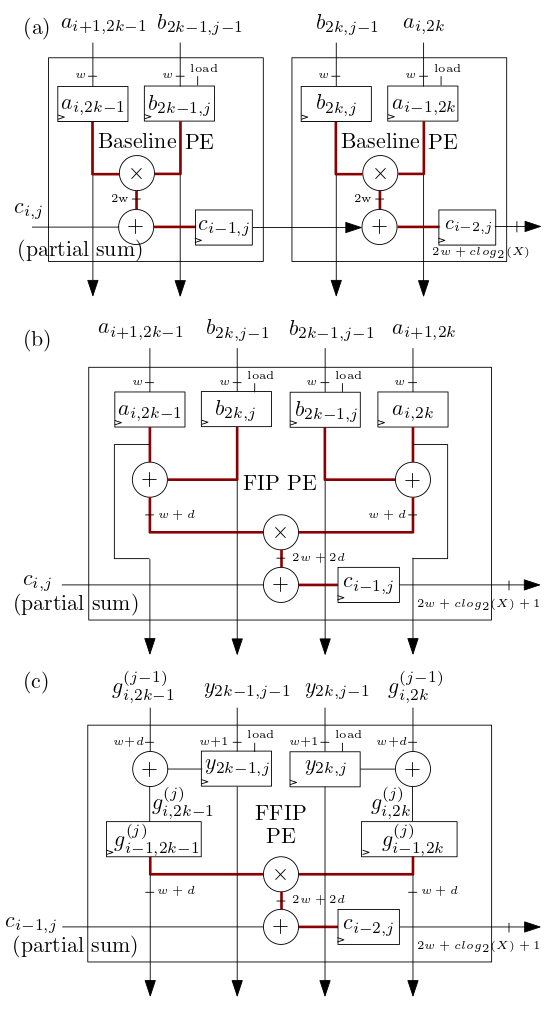
Les éléments de traitement (PE) du réseau systolique/MXU FIP et FFIP présentés ci-dessous dans (b) et (c) implémentent les algorithmes de produit interne FIP et FFIP et fournissent chacun individuellement la même puissance de calcul effective que les deux PE de base présentés dans ( a) combinés qui implémentent le produit interne de base comme dans les précédents accélérateurs ML systoliques :
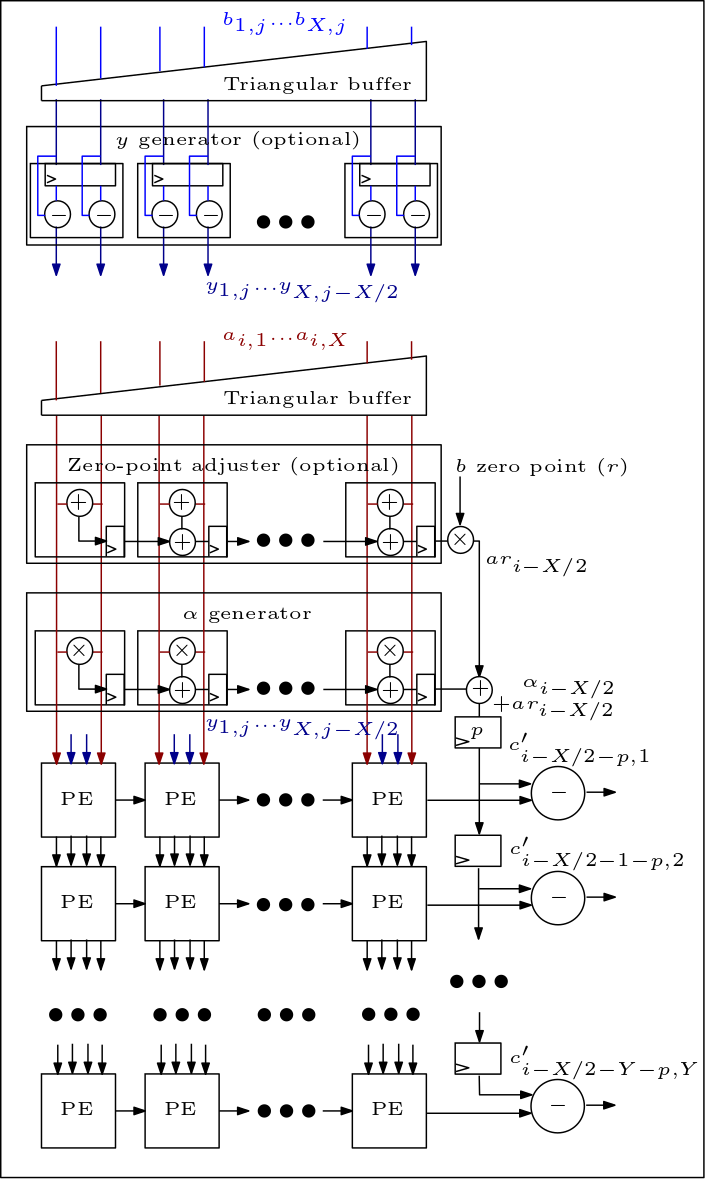
Ce qui suit est un diagramme du réseau MXU/systolique et montre comment les PE sont connectés :
L'organisation du code source est la suivante :
Les fichiers rtl/top/define.svh et rtl/top/pkg.sv contiennent un certain nombre de paramètres configurables tels que FIP_METHOD dans finish.svh qui définit le type de tableau systolique (ligne de base, FIP ou FFIP), SZI et SZJ qui définissent la hauteur/largeur du tableau systolique et LAYERIO_WIDTH/WEIGHT_WIDTH qui définissent les largeurs de bits d'entrée.
Le répertoire rtl/arith comprend mxu.sv et mac_array.sv qui contiennent le RTL pour les architectures de réseau systolique de base, FIP et FFIP (en fonction de la valeur du paramètre FIP_METHOD).


