lumiere pytorch
0.0.24
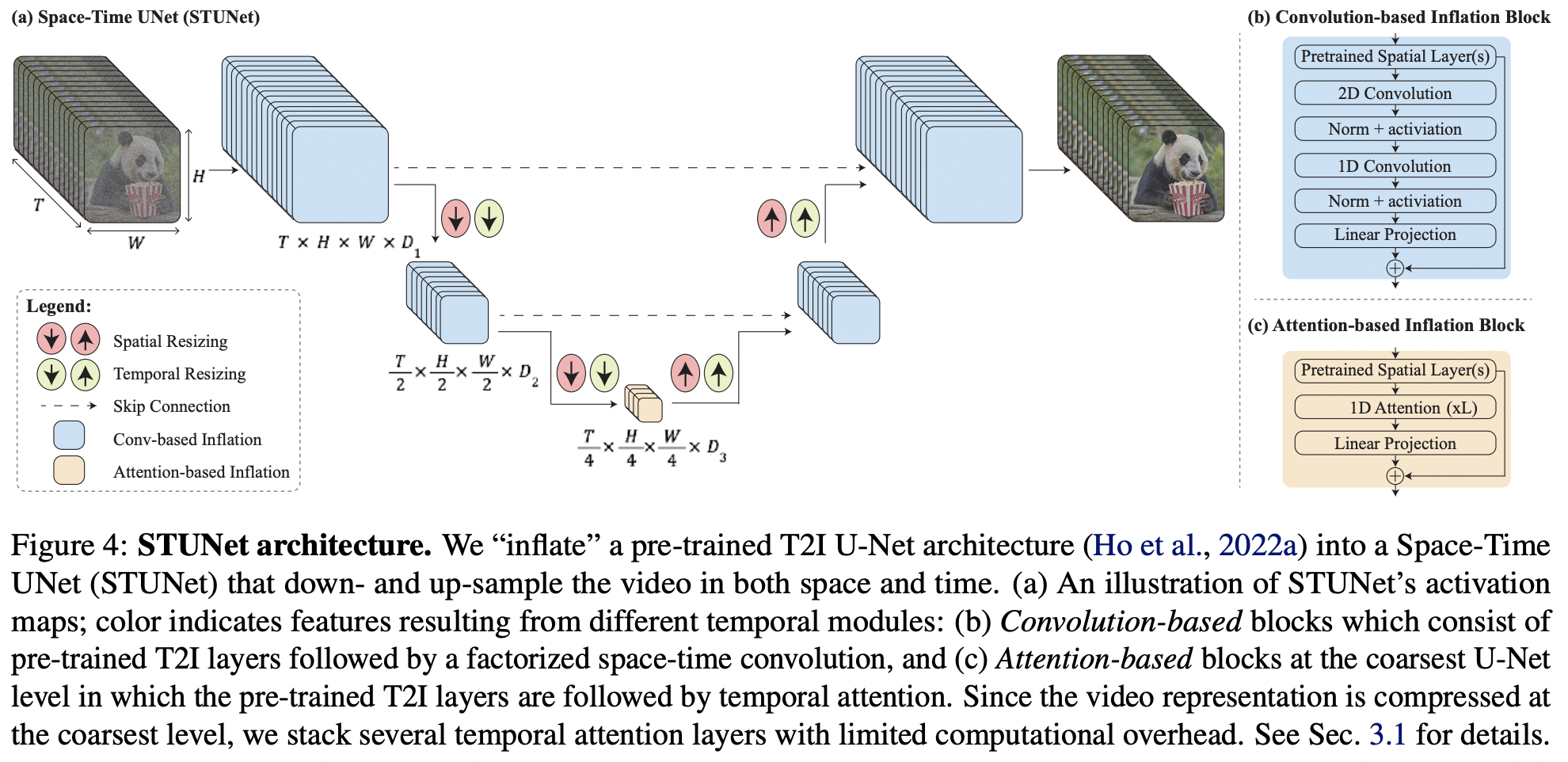
Implémentation de Lumiere, génération texte-vidéo SOTA de Google Deepmind, dans Pytorch
Revue de l'article de Yannic
Étant donné que cet article ne contient principalement que quelques idées clés en plus du modèle texte-image, nous allons aller plus loin et étendre le nouveau Karras U-net à la vidéo au sein de ce référentiel.
$ pip install lumiere-pytorch import torch
from lumiere_pytorch import MPLumiere
from denoising_diffusion_pytorch import KarrasUnet
karras_unet = KarrasUnet (
image_size = 256 ,
dim = 8 ,
channels = 3 ,
dim_max = 768 ,
)
lumiere = MPLumiere (
karras_unet ,
image_size = 256 ,
unet_time_kwarg = 'time' ,
conv_module_names = [
'downs.1' ,
'ups.1' ,
'downs.2' ,
'ups.2' ,
],
attn_module_names = [
'mids.0'
],
upsample_module_names = [
'ups.2' ,
'ups.1' ,
],
downsample_module_names = [
'downs.1' ,
'downs.2'
]
)
noised_video = torch . randn ( 2 , 3 , 8 , 256 , 256 )
time = torch . ones ( 2 ,)
denoised_video = lumiere ( noised_video , time = time )
assert noised_video . shape == denoised_video . shape ajouter toutes les couches temporelles
exposer uniquement les paramètres temporels pour l'apprentissage, geler tout le reste
trouver la meilleure façon de gérer le conditionnement temporel après le sous-échantillonnage temporel - au lieu de la transformation pytree au début, il faudra probablement se connecter à tous les modules et inspecter la taille des lots
gérer les modules intermédiaires qui peuvent avoir une forme de sortie comme (batch, seq, dim)
suite aux conclusions de Tero Karras, improviser une variante des 4 modules avec préservation de l'ampleur
tester sur imagen-pytorch
examinez la multidiffusion et voyez si elle peut se transformer en un simple emballage
@inproceedings { BarTal2024LumiereAS ,
title = { Lumiere: A Space-Time Diffusion Model for Video Generation } ,
author = { Omer Bar-Tal and Hila Chefer and Omer Tov and Charles Herrmann and Roni Paiss and Shiran Zada and Ariel Ephrat and Junhwa Hur and Yuanzhen Li and Tomer Michaeli and Oliver Wang and Deqing Sun and Tali Dekel and Inbar Mosseri } ,
year = { 2024 } ,
url = { https://api.semanticscholar.org/CorpusID:267095113 }
} @article { Karras2023AnalyzingAI ,
title = { Analyzing and Improving the Training Dynamics of Diffusion Models } ,
author = { Tero Karras and Miika Aittala and Jaakko Lehtinen and Janne Hellsten and Timo Aila and Samuli Laine } ,
journal = { ArXiv } ,
year = { 2023 } ,
volume = { abs/2312.02696 } ,
url = { https://api.semanticscholar.org/CorpusID:265659032 }
}

