Extendible Hashing for DBMS
1.0.0
Une implémentation de bas niveau du hachage extensible pour les systèmes de bases de données.
Cette méthode utilise des répertoires et des compartiments pour hacher les données et est largement connue pour sa flexibilité et son efficacité en termes de temps de calcul.
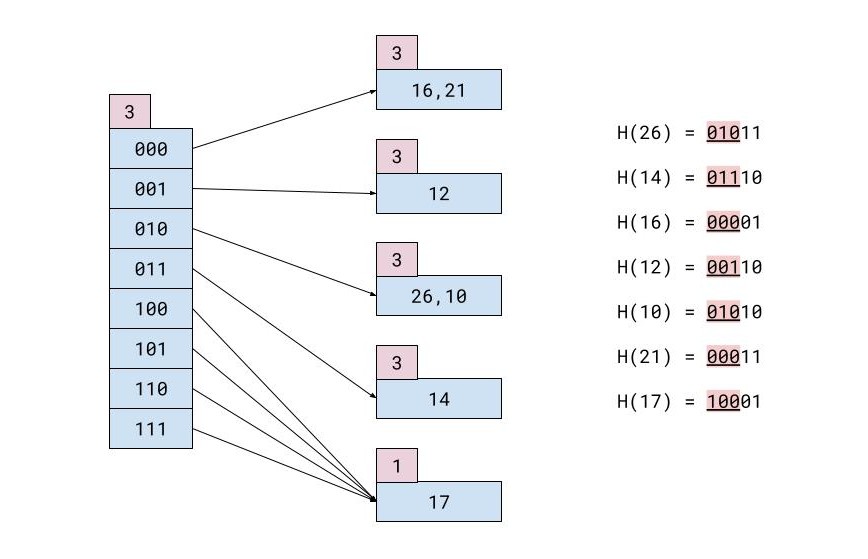
Par exemple, vous avez cette table d'enregistrements :
| IDENTIFIANT | NOM | NOM DE FAMILLE | VILLE |
|---|---|---|---|
| 26 | Marie | Koronis | Hong Kong |
| 14 | Christoforos | Gaitanis | Tokyo |
| 16 | Marianne | Karvounari | Miami |
| 12 | Théophile | Nikolopoulos | Londres |
| 10 | Joseph | Svingos | Tokyo |
| 21 | Théophile | Michas | Athènes |
| 17 | Giorgos | Halatsis | Munich |
Si chaque bloc de mémoire ne peut contenir que 2 enregistrements, le fichier de hachage après toutes les insertions ressemblera à ceci :
Le programme peut être exécuté par deux fonctions principales différentes. Ce premier insère un grand nombre d'enregistrements dans un fichier et le second crée et insère des enregistrements dans trois fichiers différents simultanément.
test_main1 :
make main1
./build/runner
test_main2 :
make main2
./build/runner