Le référentiel se compose d'un VQ-VAE implémenté dans Pytorch et formé sur l'ensemble de données MNIST.
VQ-VAE suit le même concept de base que derrière les autocodeurs variationnels (VAE). VQ-VAE utilise des incorporations latentes discrètes pour les encodeurs automobiles variationnels , c'est-à-dire que chaque dimension de z (vecteur latent) est un entier discret, au lieu de la distribution normale continue généralement utilisée lors de la codage des entrées.
Les VAE se composent de 3 parties:
Eh bien, vous pouvez vous poser des questions sur les différences que les VQ-Vaes apportent à la table. Liscons-les:
De nombreux objets importants du monde réel sont discrets. Par exemple, dans les images, nous pourrions avoir des catégories comme «chat», «voiture», etc. et cela pourrait ne pas être logique d'interpoler entre ces catégories. Les représentations discrètes sont également plus faciles à modéliser.
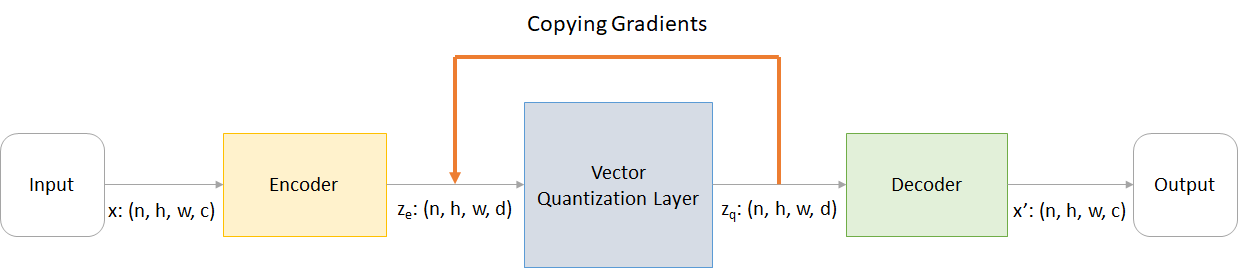
où:
n : taille du loth : hauteur de l'imagew : Largeur d'imagec : Nombre de canaux dans l'image d'entréed : Nombre de canaux à l'état caché Voici un bref aperçu du fonctionnement d'un réseau VQ-VAE:
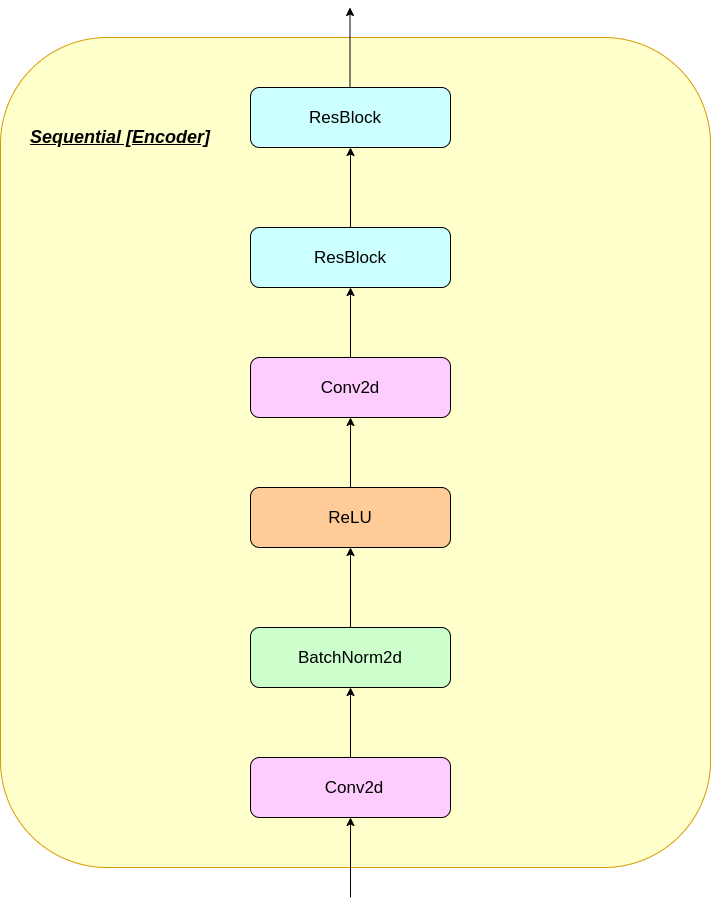
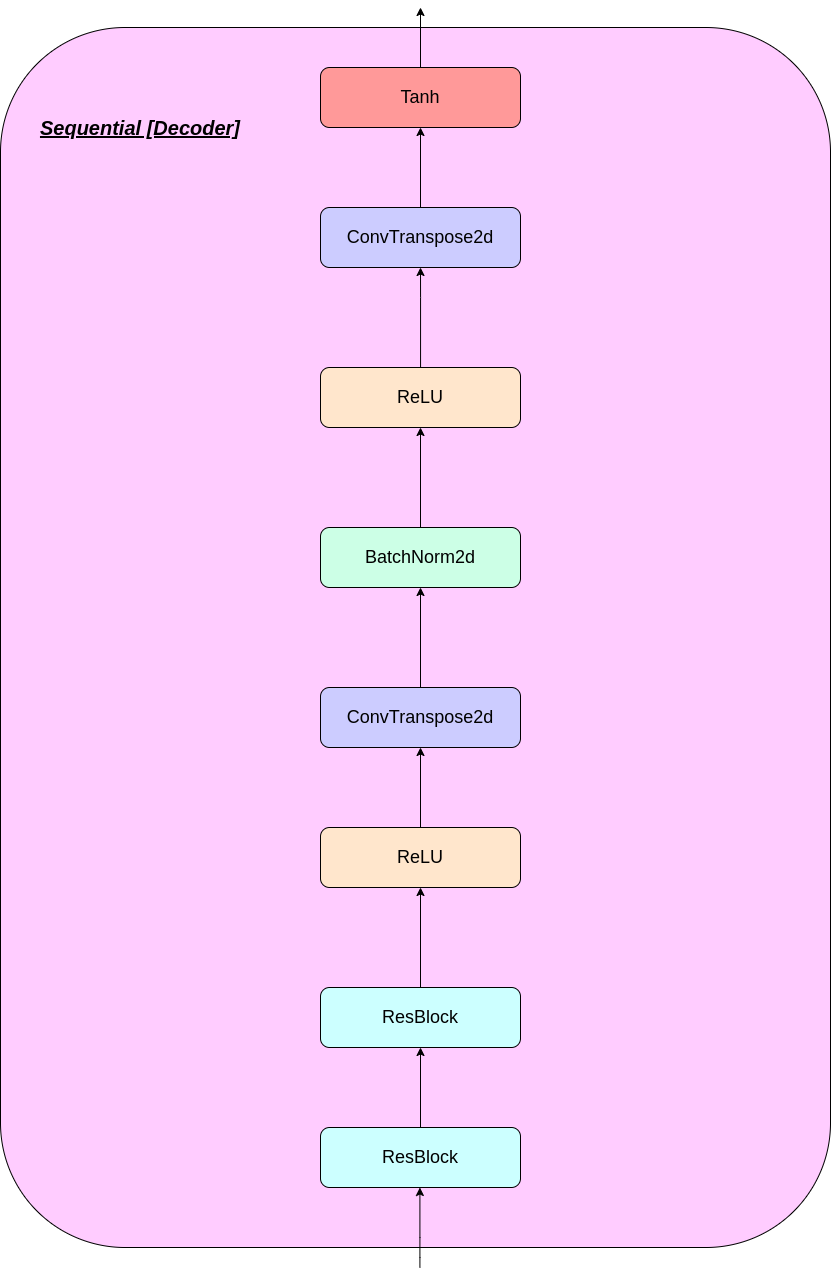
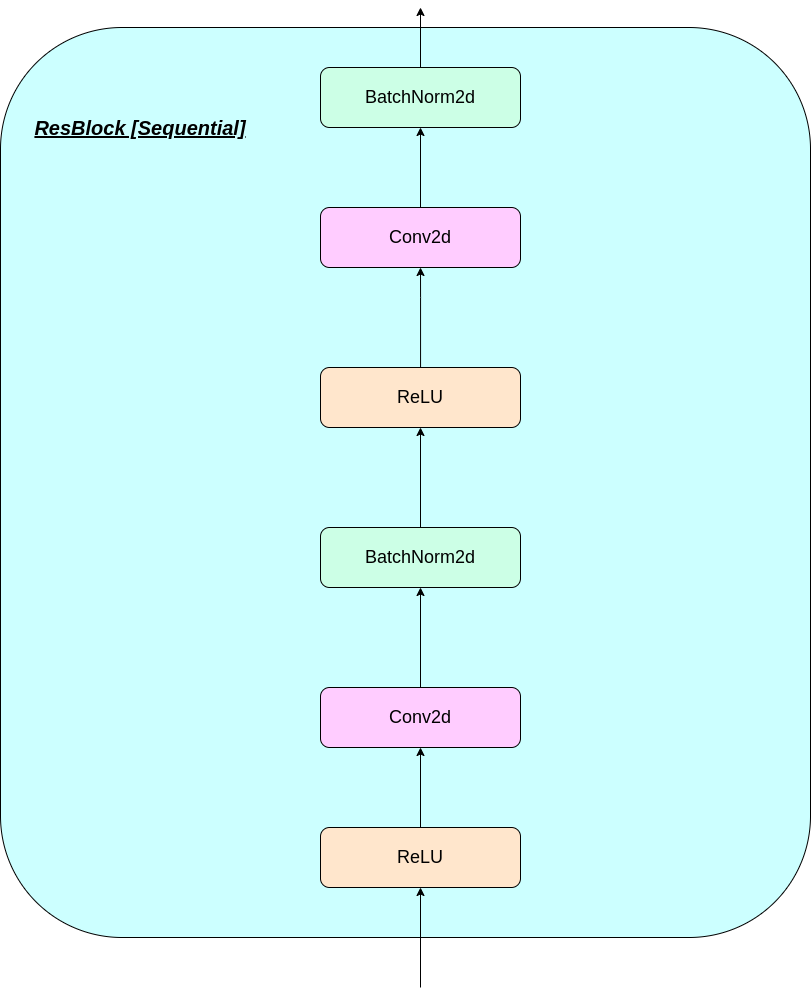
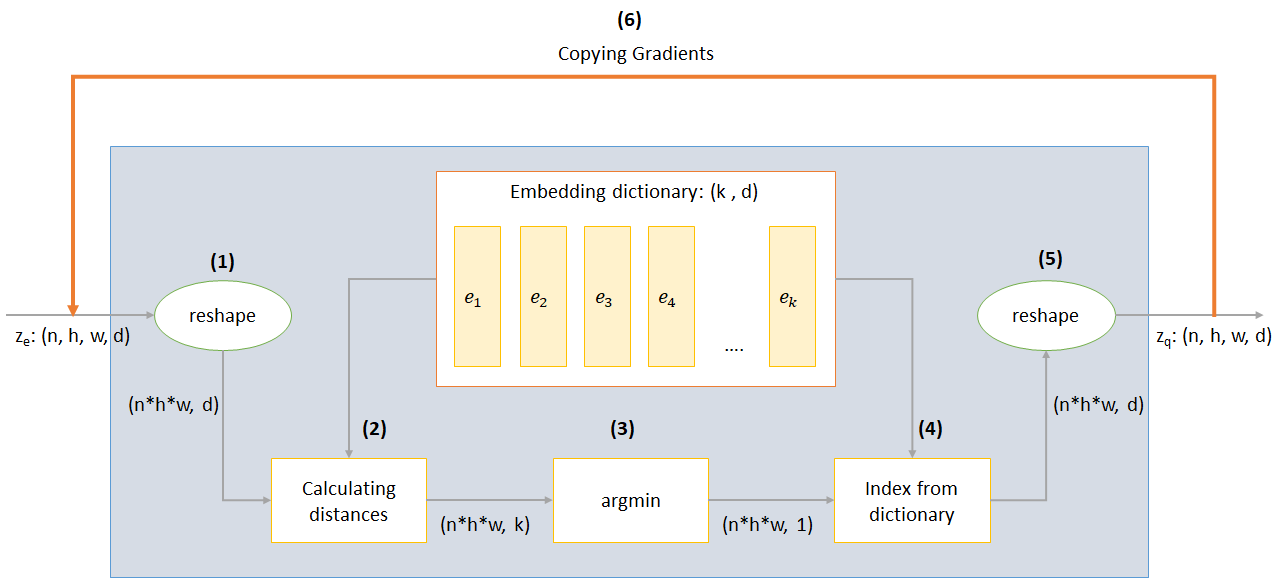
Le fonctionnement de la couche VQ peut être expliqué en six étapes comme numéroté sur la figure:
VQ-VAE utilise 3 pertes pour calculer la perte totale pendant la formation:
Perte de reconstruction: optimise le décodeur et le codeur sous forme de VAE, c'est-à-dire la différence entre l'image d'entrée et la reconstruction:
reconstruction_loss = -log( p(x|z_q) )
Perte du livre de codes: En raison du fait que les gradients contournent l'incorporation, un algorithme d'apprentissage du dictionnaire qui utilise une erreur L2 pour déplacer les vecteurs d'intégration E_I vers la sortie de l'encodeur est utilisé.
codebook_loss = ‖ sg[z_e(x)]− e ‖^2
(SG représente l'opérateur de gradient d'arrêt, ce qui signifie qu'aucun gradient s'écoule à travers tout ce qu'il est appliqué)
Perte d'engagement: Étant donné que le volume de l'espace d'incorporation est sans dimension, il peut croître arbitrairement si les intégres E_I ne s'entraînent pas aussi vite que les paramètres de l'encodeur, et donc une perte d'engagement est ajoutée pour s'assurer que le codeur s'engage à une incorporation.
commitment_loss = β‖ z_e(x)− sg[e] ‖^2
(β est un hyperparamètre qui contrôle combien nous voulons peser la perte d'engagement par rapport aux autres composants)
Vous pouvez télécharger le dépôt ou le cloner en exécutant ce qui suit dans CMD Invite
https://github.com/praeclarumjj3/VQ-VAE-on-MNIST.git
Vous pouvez former le modèle à partir de zéro par la commande suivante (dans Google Colab)
! python3 VQ-VAE.py --output-folder [NAME_OF_OUTPUT_FOLDER] --data-folder [PATH_TO_MNIST_dataset] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --batch-size [BATCH_SIZE] --num_epoch [NUMBER_OF_EPOCHS] --lr [LEARNING_RATE] --beta [VALUE] --num-workers [NUMBER_OF_WORKERS]
output-folder - Nom du dossier de donnéesdata-folder - Nom du dossier de donnéesdevice - Définissez l'appareil (CPU ou CUDA, par défaut: CPU)hidden-size - taille des vecteurs latents (par défaut: 40)k - Nombre de vecteurs latents (par défaut: 512)batch-size - Taille du lot (par défaut: 128)num-epochs - Nombre d'époches (par défaut: 10)lr - Taux d'apprentissage pour Adam Optimizer (par défaut: 2e-4)beta - Contribution de la perte d'engagement, entre 0,1 et 2,0 (par défaut: 1.0)num-workers - Nombre de travailleurs pour l'échantillonnage des trajectoires (par défaut: cpu_count () - 1) Le programme télécharge automatiquement l'ensemble de données MNIST et l'enregistre dans le dossier PATH_TO_MNIST_dataset (vous devez créer ce dossier). Cela ne se produit qu'une seule fois.
Il crée également un dossier logs et models et à l'intérieur d'eux crée un dossier avec le nom qui vous a été transmis pour enregistrer respectivement les journaux et les points de contrôle de modèle à l'intérieur.
Pour générer de nouvelles images à partir de Z échantillonnée au hasard à partir d'une unité Gaussian, exécutez la commande suivante (dans Google Colab):
! python3 generate.py --model [SAVED_MODEL_FILENAME] --input [MNIST_or_random] --device ['cpu' or 'cuda' ] --hidden-size [SIZE] --k [NUMBER] --filename [SAVING_NAME]
model - nom de fichier contenant le modèleinput - MNIST ou aléatoiredevice - Définissez l'appareil (CPU ou CUDA, par défaut: CPU)hidden-size - taille des vecteurs latents (par défaut: 40)k - Nombre de vecteurs latents (par défaut: 512)filename - nom avec lequel le fichier doit être enregistré Il génère une grille 10 * 10 d'images qui sont enregistrées dans un dossier nommé generatedImages .
Vous pouvez utiliser un modèle pré-formé en le téléchargeant à partir du lien dans model.txt .
Le référentiel contient les fichiers suivants
modules.py - contient les différents modules utilisés pour fabriquer notre modèleVQ-VAE.py - contient les fonctions et le code pour la formation de notre modèle VQ-VAEvector_quantizer.py - Les classes de quantification vectorielle sont définies dans ce fichiergenerate-py - Génére de nouvelles images à partir d'un modèle pré-formémodel.txt - contient un lien vers un modèle pré-forméREADME.md - Readme donnant un aperçu du reporeferences.txt - références utilisées lors de la création de ce reporeadme_images - a diverses images pour le ReadmeMNIST - Contient l'ensemble de données MNIST zippé (bien qu'il soit téléchargé automatiquement si nécessaire)Training track for VQ-VAE.txt - contient les valeurs de perte pendant la formation de notre modèle VQ-VAElogs_VQ-VAE - Contient les journaux Tensorboard zippés pour notre modèle VQ-VAE (créé automatiquement par le programme)testers.py - contient certaines fonctions pour tester nos modules définisCommande pour exécuter Tensorboard (dans Google Colab):
%load_ext tensorboard
%tensordboard --logdir [path_to_folder_with_logs]
Image de formation
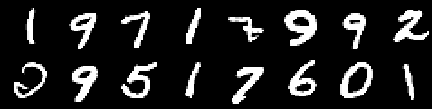
Image de la 0ème époque

Image de la 2e époque
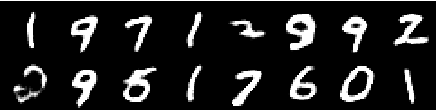
Image de la 4e époque
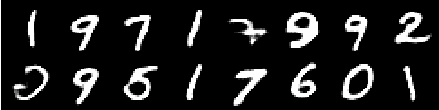
Image de la 6e époque
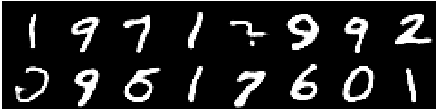
Image de la 8e époque
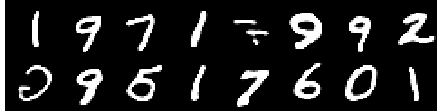
Image de la 10e époque
Les reconstructions continuent de s'améliorer et à la fin ressemblent presque aux images Training_set qui se reflètent dans les valeurs de perte (vérifiez Training track for VQ-VAE.txt ).
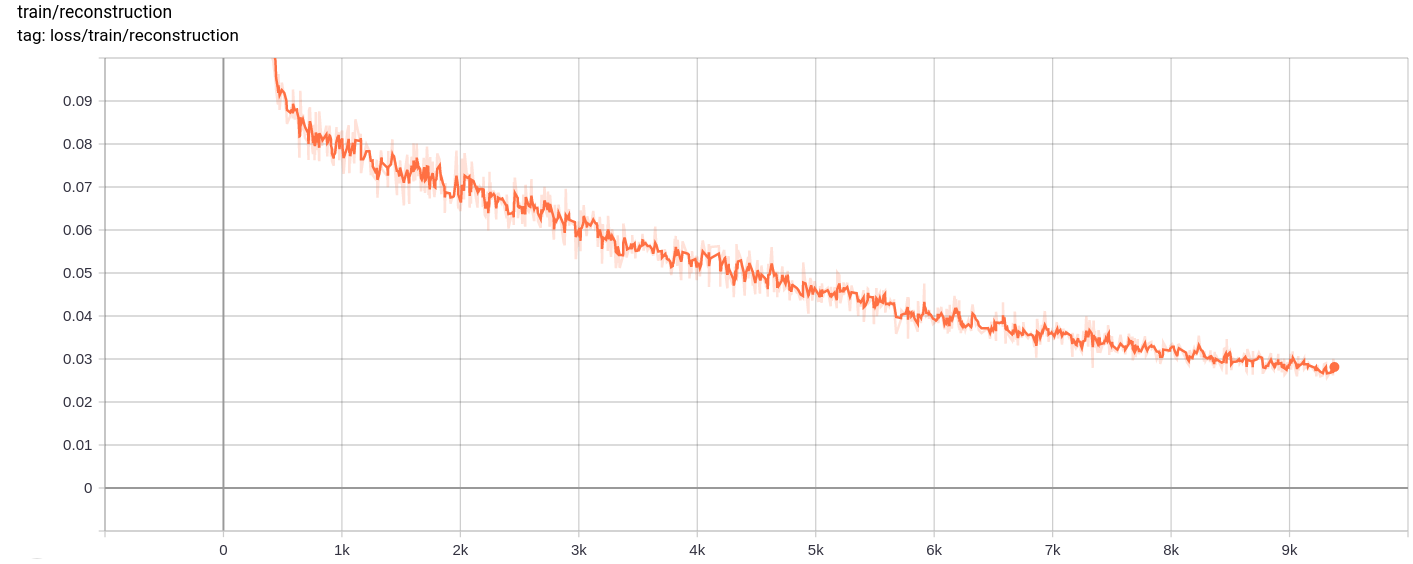
Perte de reconstruction
Perte de quantification
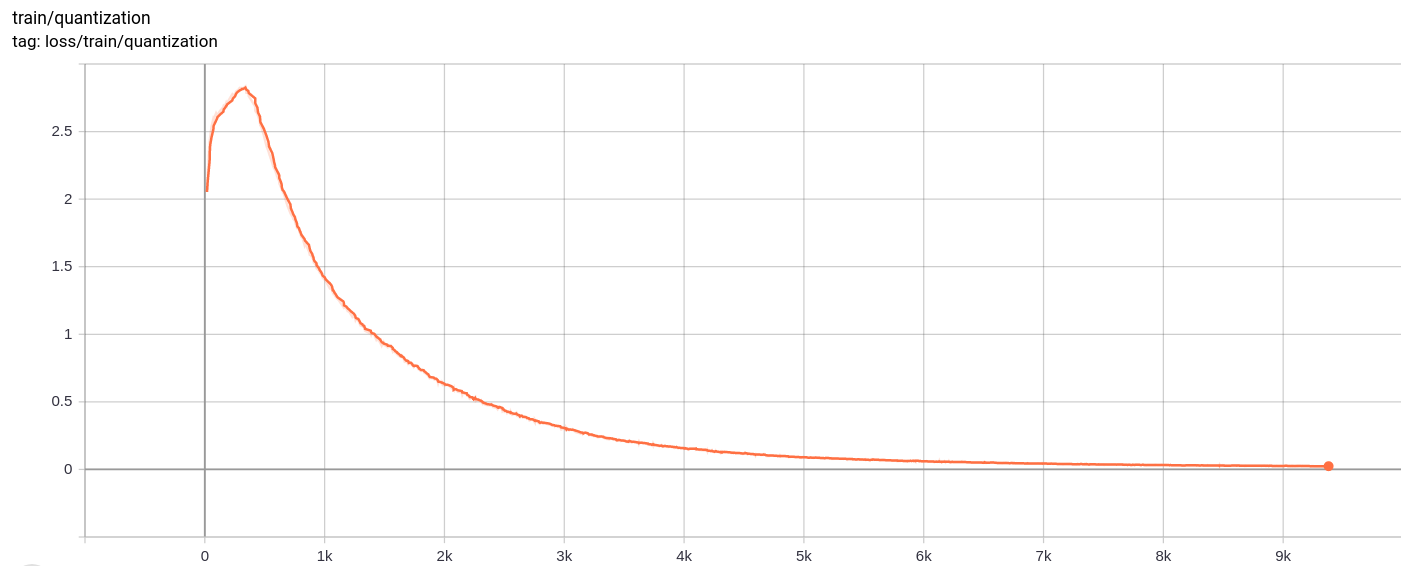
Total_loss
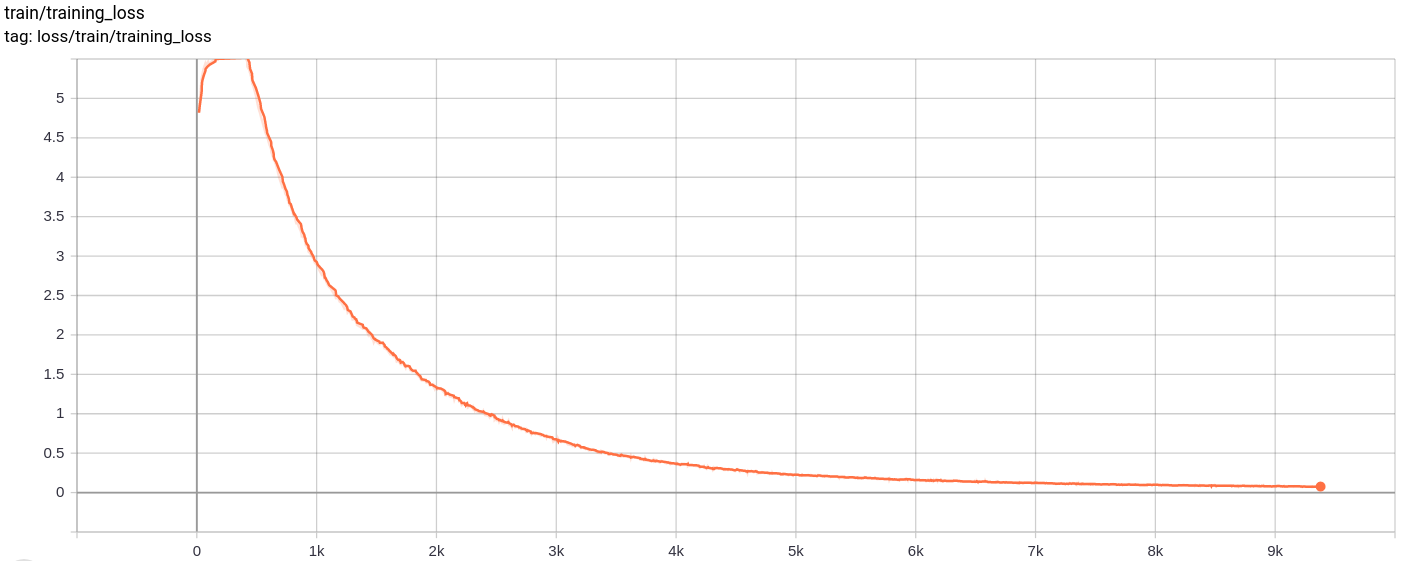
La perte totale, la perte de reconstruction et la perte de quantification diminuent uniformément comme prévu.
Test_loss
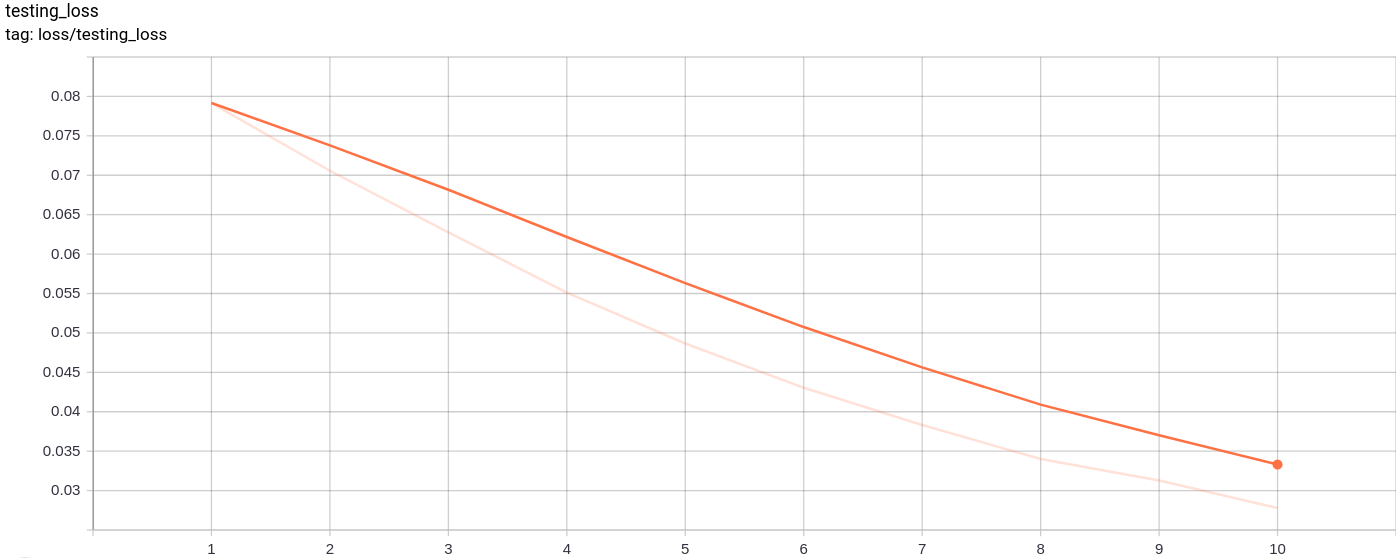
La perte de test diminue uniformément comme prévu.
La grille d'image suivante a été générée après avoir passé des images MNIST comme entrées:

La génération est plutôt bonne.
Les grilles d'image suivantes ont été générées après le passage AZ échantillonné au hasard à partir d'une unité gaussienne comme entrée au modèle, puis passée à travers le décodeur


Les images ne sont pas parfaites. Le réglage des dimensions de l'espace latent, le nombre de vecteurs d'intégration, etc. peuvent aider à générer de meilleures images aléatoires.
Le modèle a été formé sur Google Colab pour 10 époques, avec la taille du lot 128.
Après l'entraînement, le modèle a pu reconstruire les images d'entrée assez bien et a également pu générer de nouvelles images bien que les images générées ne soient pas si bonnes.
La formation ainsi que la perte de test ont également continué à diminuer presque monotone.
J'ai observé que la formation du modèle pour plus de 10 à 20 époques a produit des résultats qui suggéraient un signe probable de sur-ajustement dans le modèle. De plus, j'ai expérimenté différentes dimensions de l'espace laatennt et dans la dimension = 40 ont produit les meilleurs résultats. La meilleure gamme pour la dimension est devenue entre 16 et 42.
Les sources suivantes ont beaucoup aidé à faire ce référentiel


