pandas ta
v0.3.14b
Pandas Technical Analysis ( PANDAS TA ) est une bibliothèque facile à utiliser qui exploite le package Pandas avec plus de 130 indicateurs et fonctions utilitaires et plus de 60 modèles de chandelles Ta Lib. De nombreux indicateurs couramment utilisés sont inclus, tels que: Modèle de bougie ( CDL_PATTERN ), moyenne mobile simple ( SMA ) Divergence de convergence moyenne ( MACD ), moyenne mobile exponentielle de coque ( HMA ), bandes de Bollinger ( BBAND ), volume à l'équilibre ( obv (obv) ), L'oscillateur Aroon & Aroon ( Aroon ), Squeeze ( Squeeze ) et bien d'autres .
Remarque: TA LIB doit être installé pour utiliser tous les modèles de chandeliers. pip install TA-Lib . Si Ta Lib n'est pas installé, seuls les modèles de chandeliers intégrés seront disponibles.
talib=False .ta.stdev(df["close"], length=30, talib=False) .import_dir sous /pandas_ta/custom.py .ta.tsignals de Pandas TA.lookahead=False à désactiver.Pandas TA vérifie si l'utilisateur a des packages de trading communs installés, y compris, mais sans s'y limiter: TA lib , vector bt , yfinance ... dont une grande partie est expérimentale et susceptible de se casser jusqu'à ce qu'elle se stabilise davantage.
help(ta.ticker) et help(ta.yf) et les exemples ci-dessous. La version pip est la dernière version stable. Version: 0.3.14b
$ pip install pandas_taMeilleur choix! Version: 0.3.14b
$ pip install -U git+https://github.com/twopirllc/pandas-taIl s'agit de la version de développement qui pourrait avoir des bogues et d'autres effets secondaires indésirables. Utilisez à ses propres risques!
$ pip install -U git+https://github.com/twopirllc/pandas-ta.git@development import pandas as pd
import pandas_ta as ta
df = pd . DataFrame () # Empty DataFrame
# Load data
df = pd . read_csv ( "path/to/symbol.csv" , sep = "," )
# OR if you have yfinance installed
df = df . ta . ticker ( "aapl" )
# VWAP requires the DataFrame index to be a DatetimeIndex.
# Replace "datetime" with the appropriate column from your DataFrame
df . set_index ( pd . DatetimeIndex ( df [ "datetime" ]), inplace = True )
# Calculate Returns and append to the df DataFrame
df . ta . log_return ( cumulative = True , append = True )
df . ta . percent_return ( cumulative = True , append = True )
# New Columns with results
df . columns
# Take a peek
df . tail ()
# vv Continue Post Processing vv Certains arguments indicateurs ont été réorganisés pour la cohérence. Utilisez help(ta.indicator_name) pour plus d'informations ou faites une demande de traction pour améliorer la documentation.
import pandas as pd
import pandas_ta as ta
# Create a DataFrame so 'ta' can be used.
df = pd . DataFrame ()
# Help about this, 'ta', extension
help ( df . ta )
# List of all indicators
df . ta . indicators ()
# Help about an indicator such as bbands
help ( ta . bbands ) Merci d'utiliser Pandas TA !
$ pip install -U git+https://github.com/twopirllc/pandas-taMerci pour vos contributions!
Pandas TA possède trois «styles» principaux de traitement des indicateurs techniques pour votre cas d'utilisation et / ou les exigences. Ce sont: standard , extension de dataframe et stratégie Pandas TA . Chacun avec des niveaux croissants d'abstraction pour la facilité d'utilisation. Au fur et à mesure que vous vous familiarisez avec Pandas TA , la simplicité et la vitesse de l'utilisation d'une stratégie Pandas TA peuvent devenir plus apparentes. De plus, vous pouvez créer vos propres indicateurs par le chaînage ou la composition. Enfin, chaque indicateur renvoie une série ou un dataframe au format de soulignement majuscule quel que soit le style.
Vous définissez explicitement les colonnes d'entrée et prenez soin de la sortie.
sma10 = ta.sma(df["Close"], length=10)SMA_10donchiandf = ta.donchian(df["HIGH"], df["low"], lower_length=10, upper_length=15)DC_10_15 et des noms de colonne: DCL_10_15, DCM_10_15, DCU_10_15ema10_ohlc4 = ta.ema(ta.ohlc4(df["Open"], df["High"], df["Low"], df["Close"]), length=10)EMA_10 . Si nécessaire, vous devrez peut-être le nommer de manière unique. L'appel df.ta sera automatiquement minuscule ohlcva vers OHLCVA : ouvert, haut, bas, ferme, volume , adj_close . Par défaut, df.ta utilisera l' OHLCVA pour les arguments d'indicateur supprimant directement la nécessité de spécifier les colonnes d'entrée directement.
sma10 = df.ta.sma(length=10)SMA_10ema10_ohlc4 = df.ta.ema(close=df.ta.ohlc4(), length=10, suffix="OHLC4")EMA_10_OHLC4close=df.ta.ohlc4() .donchiandf = df.ta.donchian(lower_length=10, upper_length=15)DC_10_15 et des noms de colonne: DCL_10_15, DCM_10_15, DCU_10_15 Identique aux trois derniers exemples, mais en ajoutant les résultats directement au DATHFrame df .
df.ta.sma(length=10, append=True)df : SMA_10 .df.ta.ema(close=df.ta.ohlc4(append=True), length=10, suffix="OHLC4", append=True)close=df.ta.ohlc4() .df.ta.donchian(lower_length=10, upper_length=15, append=True)df avec des noms de colonne: DCL_10_15, DCM_10_15, DCU_10_15 . Une stratégie Pandas TA est un groupe nommé d'indicateurs à gérer par la méthode de stratégie . Toutes les stratégies utilisent le procédure mulit, sauf lors de l'utilisation du paramètre col_names (voir ci-dessous). Il existe différents types de stratégies répertoriées dans la section suivante.
# (1) Create the Strategy
MyStrategy = ta . Strategy (
name = "DCSMA10" ,
ta = [
{ "kind" : "ohlc4" },
{ "kind" : "sma" , "length" : 10 },
{ "kind" : "donchian" , "lower_length" : 10 , "upper_length" : 15 },
{ "kind" : "ema" , "close" : "OHLC4" , "length" : 10 , "suffix" : "OHLC4" },
]
)
# (2) Run the Strategy
df . ta . strategy ( MyStrategy , ** kwargs )La classe de stratégie est un moyen simple de nommer et de regrouper vos indicateurs TA préférés en utilisant une classe de données . Pandas TA est livré avec deux stratégies de base prédéfinies pour vous aider à démarrer: Allstrategy et Commonstrategy . Une stratégie peut être aussi simple que la commontgie ou aussi complexe que nécessaire en utilisant la composition / le chaînage.
df .Voir le cahier des exemples de stratégie Pandas TA pour des exemples comprenant la composition / chaînage des indicateurs .
{"kind": "indicator name"} . N'oubliez pas de vérifier votre orthographe. # Running the Builtin CommonStrategy as mentioned above
df . ta . strategy ( ta . CommonStrategy )
# The Default Strategy is the ta.AllStrategy. The following are equivalent:
df . ta . strategy ()
df . ta . strategy ( "All" )
df . ta . strategy ( ta . AllStrategy ) # List of indicator categories
df . ta . categories
# Running a Categorical Strategy only requires the Category name
df . ta . strategy ( "Momentum" ) # Default values for all Momentum indicators
df . ta . strategy ( "overlap" , length = 42 ) # Override all Overlap 'length' attributes # Create your own Custom Strategy
CustomStrategy = ta . Strategy (
name = "Momo and Volatility" ,
description = "SMA 50,200, BBANDS, RSI, MACD and Volume SMA 20" ,
ta = [
{ "kind" : "sma" , "length" : 50 },
{ "kind" : "sma" , "length" : 200 },
{ "kind" : "bbands" , "length" : 20 },
{ "kind" : "rsi" },
{ "kind" : "macd" , "fast" : 8 , "slow" : 21 },
{ "kind" : "sma" , "close" : "volume" , "length" : 20 , "prefix" : "VOLUME" },
]
)
# To run your "Custom Strategy"
df . ta . strategy ( CustomStrategy ) La méthode de stratégie Pandas TA utilise le multiprocessement pour le traitement des indicateurs en vrac de tous les types de stratégie à une exception! Lorsque vous utilisez le paramètre col_names pour renommer les colonnes résultant, les indicateurs du tableau ta seront exécutés dans l'ordre.
# VWAP requires the DataFrame index to be a DatetimeIndex.
# * Replace "datetime" with the appropriate column from your DataFrame
df . set_index ( pd . DatetimeIndex ( df [ "datetime" ]), inplace = True )
# Runs and appends all indicators to the current DataFrame by default
# The resultant DataFrame will be large.
df . ta . strategy ()
# Or the string "all"
df . ta . strategy ( "all" )
# Or the ta.AllStrategy
df . ta . strategy ( ta . AllStrategy )
# Use verbose if you want to make sure it is running.
df . ta . strategy ( verbose = True )
# Use timed if you want to see how long it takes to run.
df . ta . strategy ( timed = True )
# Choose the number of cores to use. Default is all available cores.
# For no multiprocessing, set this value to 0.
df . ta . cores = 4
# Maybe you do not want certain indicators.
# Just exclude (a list of) them.
df . ta . strategy ( exclude = [ "bop" , "mom" , "percent_return" , "wcp" , "pvi" ], verbose = True )
# Perhaps you want to use different values for indicators.
# This will run ALL indicators that have fast or slow as parameters.
# Check your results and exclude as necessary.
df . ta . strategy ( fast = 10 , slow = 50 , verbose = True )
# Sanity check. Make sure all the columns are there
df . columns N'oubliez pas que ceux-ci n'utiliseront pas le multiprocessement
NonMPStrategy = ta . Strategy (
name = "EMAs, BBs, and MACD" ,
description = "Non Multiprocessing Strategy by rename Columns" ,
ta = [
{ "kind" : "ema" , "length" : 8 },
{ "kind" : "ema" , "length" : 21 },
{ "kind" : "bbands" , "length" : 20 , "col_names" : ( "BBL" , "BBM" , "BBU" )},
{ "kind" : "macd" , "fast" : 8 , "slow" : 21 , "col_names" : ( "MACD" , "MACD_H" , "MACD_S" )}
]
)
# Run it
df . ta . strategy ( NonMPStrategy ) # Set ta to default to an adjusted column, 'adj_close', overriding default 'close'.
df . ta . adjusted = "adj_close"
df . ta . sma ( length = 10 , append = True )
# To reset back to 'close', set adjusted back to None.
df . ta . adjusted = None # List of Pandas TA categories.
df . ta . categories # Set the number of cores to use for strategy multiprocessing
# Defaults to the number of cpus you have.
df . ta . cores = 4
# Set the number of cores to 0 for no multiprocessing.
df . ta . cores = 0
# Returns the number of cores you set or your default number of cpus.
df . ta . cores # The 'datetime_ordered' property returns True if the DataFrame
# index is of Pandas datetime64 and df.index[0] < df.index[-1].
# Otherwise it returns False.
df . ta . datetime_ordered # Sets the Exchange to use when calculating the last_run property. Default: "NYSE"
df . ta . exchange
# Set the Exchange to use.
# Available Exchanges: "ASX", "BMF", "DIFX", "FWB", "HKE", "JSE", "LSE", "NSE", "NYSE", "NZSX", "RTS", "SGX", "SSE", "TSE", "TSX"
df . ta . exchange = "LSE" # Returns the time Pandas TA was last run as a string.
df . ta . last_run # The 'reverse' is a helper property that returns the DataFrame
# in reverse order.
df . ta . reverse # Applying a prefix to the name of an indicator.
prehl2 = df . ta . hl2 ( prefix = "pre" )
print ( prehl2 . name ) # "pre_HL2"
# Applying a suffix to the name of an indicator.
endhl2 = df . ta . hl2 ( suffix = "post" )
print ( endhl2 . name ) # "HL2_post"
# Applying a prefix and suffix to the name of an indicator.
bothhl2 = df . ta . hl2 ( prefix = "pre" , suffix = "post" )
print ( bothhl2 . name ) # "pre_HL2_post" # Returns the time range of the DataFrame as a float.
# By default, it returns the time in "years"
df . ta . time_range
# Available time_ranges include: "years", "months", "weeks", "days", "hours", "minutes". "seconds"
df . ta . time_range = "days"
df . ta . time_range # prints DataFrame time in "days" as float # Sets the DataFrame index to UTC format.
df . ta . to_utc import numpy as np
# Add constant '1' to the DataFrame
df . ta . constants ( True , [ 1 ])
# Remove constant '1' to the DataFrame
df . ta . constants ( False , [ 1 ])
# Adding constants for charting
import numpy as np
chart_lines = np . append ( np . arange ( - 4 , 5 , 1 ), np . arange ( - 100 , 110 , 10 ))
df . ta . constants ( True , chart_lines )
# Removing some constants from the DataFrame
df . ta . constants ( False , np . array ([ - 60 , - 40 , 40 , 60 ])) # Prints the indicators and utility functions
df . ta . indicators ()
# Returns a list of indicators and utility functions
ind_list = df . ta . indicators ( as_list = True )
# Prints the indicators and utility functions that are not in the excluded list
df . ta . indicators ( exclude = [ "cg" , "pgo" , "ui" ])
# Returns a list of the indicators and utility functions that are not in the excluded list
smaller_list = df . ta . indicators ( exclude = [ "cg" , "pgo" , "ui" ], as_list = True ) # Download Chart history using yfinance. (pip install yfinance) https://github.com/ranaroussi/yfinance
# It uses the same keyword arguments as yfinance (excluding start and end)
df = df . ta . ticker ( "aapl" ) # Default ticker is "SPY"
# Period is used instead of start/end
# Valid periods: 1d,5d,1mo,3mo,6mo,1y,2y,5y,10y,ytd,max
# Default: "max"
df = df . ta . ticker ( "aapl" , period = "1y" ) # Gets this past year
# History by Interval by interval (including intraday if period < 60 days)
# Valid intervals: 1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo
# Default: "1d"
df = df . ta . ticker ( "aapl" , period = "1y" , interval = "1wk" ) # Gets this past year in weeks
df = df . ta . ticker ( "aapl" , period = "1mo" , interval = "1h" ) # Gets this past month in hours
# BUT WAIT!! THERE'S MORE!!
help ( ta . yf ) Modèles qui ne sont pas audacieux , nécessitent l'installation de Ta-Lib: pip install TA-Lib
# Get all candle patterns (This is the default behaviour)
df = df . ta . cdl_pattern ( name = "all" )
# Get only one pattern
df = df . ta . cdl_pattern ( name = "doji" )
# Get some patterns
df = df . ta . cdl_pattern ( name = [ "doji" , "inside" ])ta.linreg(series, r=True)lazybear=Truedf.ta.strategy() .| Divergence de convergence moyenne mobile (MACD) |
|---|
 |
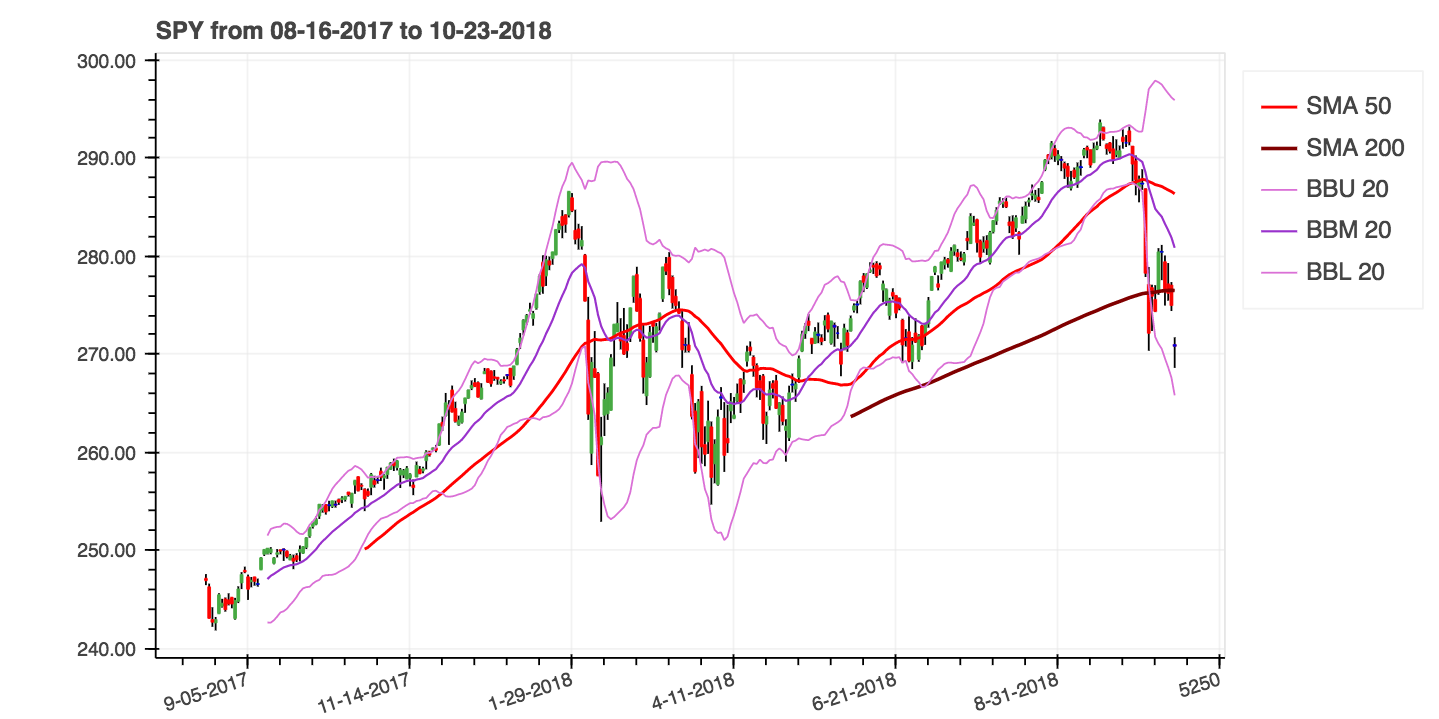
help(ta.ichimoku) .lookahead=False laisse tomber la colonne de span Chikou pour éviter une fuite de données potentielle.| Moyennes mobiles simples (SMA) et Bollinger Bands (BBBands) |
|---|
|
Utiliser le paramètre: cumulatif = vrai pour les résultats cumulatifs.
| Pourcentage de rendement (cumulatif) avec une moyenne mobile simple (SMA) |
|---|
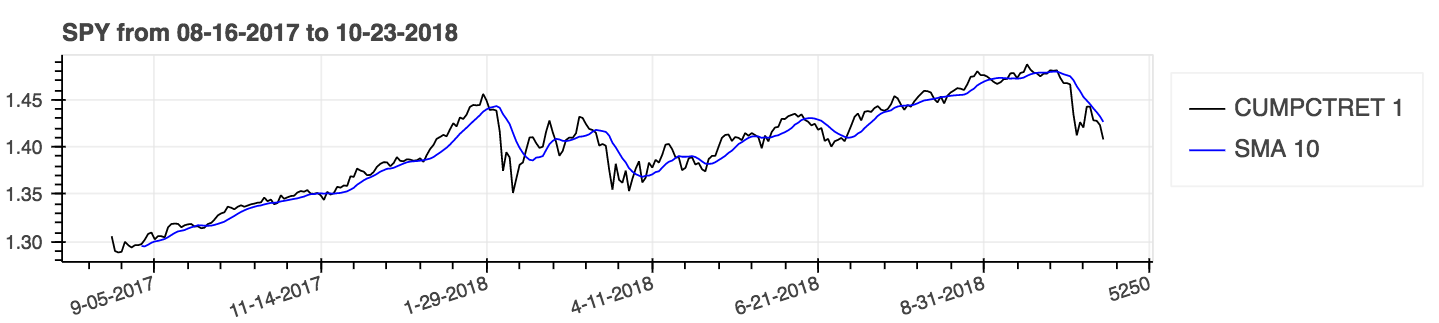 |
| Score z |
|---|
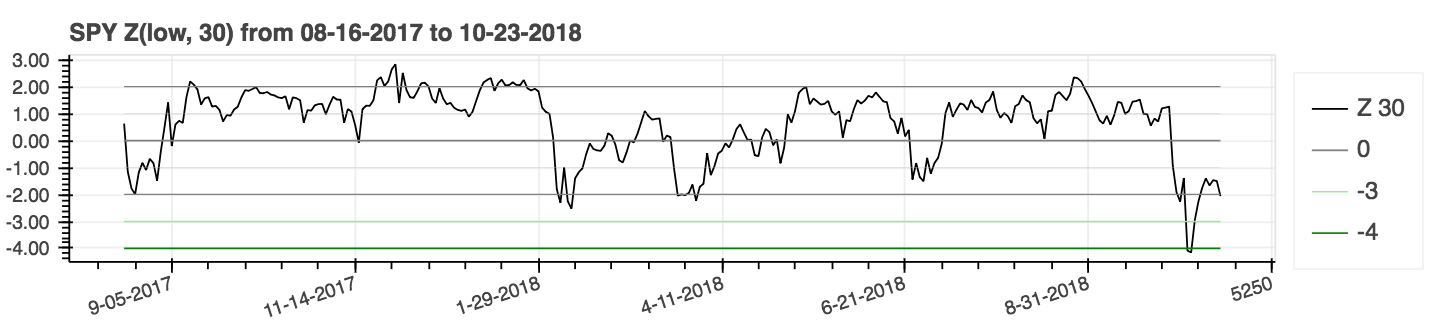 |
lookahead=False pour désactiver le centrage et supprimer la fuite de données potentielles.| Indice de mouvement directionnel moyen (ADX) |
|---|
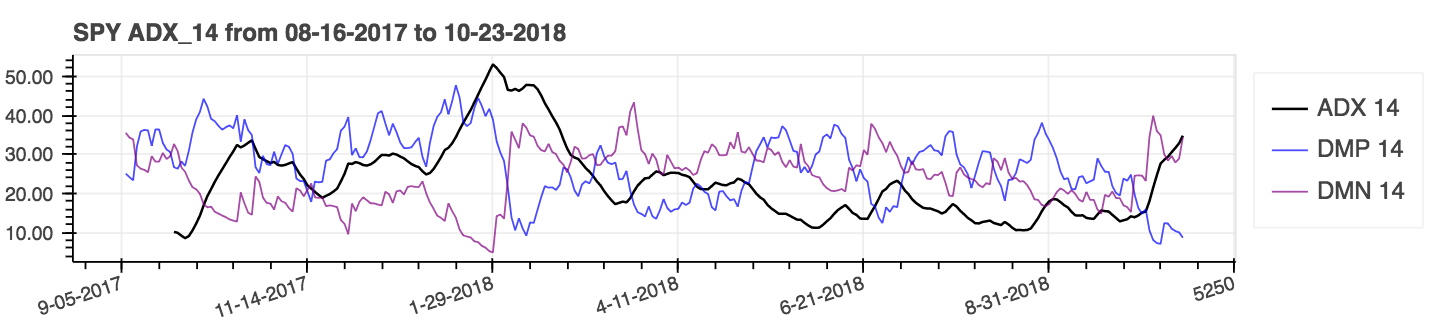 |
| Vraie moyenne moyenne (ATR) |
|---|
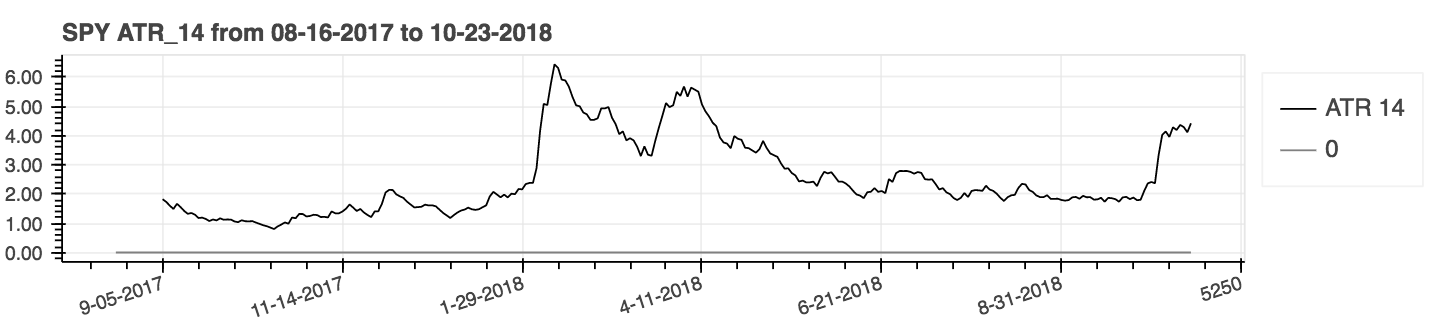 |
| Volume sur le bilan (obv) |
|---|
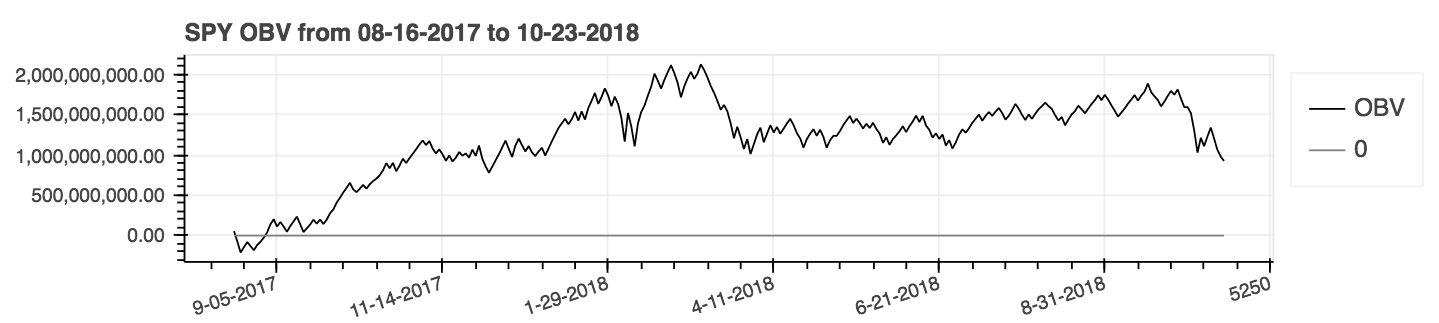 |
Les métriques de performance sont un nouvel ajout au package et, par conséquent, ne sont probablement pas fiables. Utiliser à vos risques et périls. Ces mesures renvoient un flotteur et ne font pas partie de l'extension DataFrame . Ils sont appelés la manière standard. Par exemple:
import pandas_ta as ta
result = ta . cagr ( df . close ) Pour une intégration plus facile avec la méthode du portefeuille de Vectorbt from_signals , la méthode ta.trend_return a été remplacée par la méthode ta.tsignals pour simplifier la génération de signaux de trading. Pour un exemple complet, consultez l'exemple Jupyter Notebook VectorBt Backtest avec Pandas TA dans le répertoire des exemples.
import pandas as pd
import pandas_ta as ta
import vectorbt as vbt
df = pd . DataFrame (). ta . ticker ( "AAPL" ) # requires 'yfinance' installed
# Create the "Golden Cross"
df [ "GC" ] = df . ta . sma ( 50 , append = True ) > df . ta . sma ( 200 , append = True )
# Create boolean Signals(TS_Entries, TS_Exits) for vectorbt
golden = df . ta . tsignals ( df . GC , asbool = True , append = True )
# Sanity Check (Ensure data exists)
print ( df )
# Create the Signals Portfolio
pf = vbt . Portfolio . from_signals ( df . close , entries = golden . TS_Entries , exits = golden . TS_Exits , freq = "D" , init_cash = 100_000 , fees = 0.0025 , slippage = 0.0025 )
# Print Portfolio Stats and Return Stats
print ( pf . stats ())
print ( pf . returns_stats ())mamode à jour avec plus de choix moyens mobiles avec la fonction d'utilité moyenne mobile ta.ma() . Pour plus de simplicité, tous les choix sont des moyennes mobiles d'une seule source. Il s'agit principalement d'un utilitaire interne utilisé par des indicateurs qui ont un kwarg mamode . Cela comprend les indicateurs: Accbands , Amat , AOBV , ATR , BBBAND , BAS , EFI , HILO , KC , NATR , QQE , RVI et Thermo ; Les paramètres mamode par défaut n'ont pas changé. Cependant, ta.ma() peut également être utilisé par l'utilisateur si nécessaire. Pour plus d'informations: help(ta.ma)to_utc , pour convertir l'index de dataframe en UTC. Voir: help(ta.to_utc) maintenant en tant que propriété PANDAS TA DataFrame pour convertir facilement l'index DataFrame en UTC. close > sma(close, 50) il renvoie la tendance, les entrées commerciales et les sorties commerciales de cette tendance à la rendre compatible avec Vectorbt en établissant asbool=True pour obtenir des entrées et des sorties booléennes commerciales. Voir help(ta.tsignals) help(ta.alma) Commerce Compte ou Fund. Voir help(ta.drawdown)help(ta.cdl_pattern)help(ta.cdl_z)help(ta.cti)help(ta.xsignals)help(ta.dm)help(ta.ebsw)help(ta.jma)help(ta.kvo)help(ta.stc)help(ta.squeeze_pro)df.ta.strategy() pour des raisons de performance. Voir help(ta.td_seq)help(ta.tos_stdevall)help(ta.vhf) mamode renommé en mode . Voir help(ta.accbands) .mamode avec " RMA " par défaut et avec les mêmes options mamode que TradingView. Nouvel argument lensig pour qu'il se comporte comme l'indicateur ADX intégré de TradingView. Voir help(ta.adx) .drift et des noms de colonne plus descriptifs.mamode par défaut est désormais " RMA " et avec les mêmes options mamode que TradingView. Voir help(ta.atr) .ddoff pour contrôler les degrés de liberté. Également inclus BB pourcentage (BBP) comme colonne finale. La valeur par défaut est 0. Voir help(ta.bbands) .ln pour utiliser le logarithme naturel (vrai) au lieu du logarithme standard (faux). La valeur par défaut est fausse. Voir help(ta.chop) .tvmode avec Par défaut True . Lorsque tvmode=False , CKSP implémente «le nouveau trader technique» avec des valeurs par défaut. Voir help(ta.cksp) .talib utilisera la version de Ta Lib et si Ta Lib est installé. La valeur par défaut est vraie. Voir help(ta.cmo) .strict vérifie si la série diminue continuellement sur length de la période avec un calcul plus rapide. Par défaut: False . L'argument percent a également été ajouté sans défaut. Voir help(ta.decreasing) .strict vérifie si la série augmente en permanence sur length de la période avec un calcul plus rapide. Par défaut: False . L'argument percent a également été ajouté sans défaut. Voir help(ta.increasing) .help(ta.kvo) .as_strided ou la méthode plus récente sliding_window_view . Cela devrait résoudre les problèmes avec Google Colab et ses mises à jour retardées de dépendance ainsi que les dépendances de TensorFlow, comme discuté dans les questions n ° 285 et # 329.asmode active comme version de MACD. La valeur par défaut est fausse. Voir help(ta.macd) .sar de TradingView. Nouvel argument af0 pour initialiser le facteur d'accélération. Voir help(ta.psar) .mamode en option. La valeur par défaut est SMA pour correspondre à Ta Lib. Voir help(ta.ppo) .signal ajouté avec par défaut 13 et MADE mamode MA SIGNAL avec EMA par défaut comme arguments. Voir help(ta.tsi) .help(ta.vp) .help(ta.vwma) .anchor . Par défaut: "D" pour "quotidien". Voir les alias de compensation de tirales pour des options supplémentaires. Nécessite que l'index DataFrame est un DateTimeIndex. Voir help(ta.vwap) .help(ta.vwma) .Z_length à ZS_length . Voir help(ta.zscore) .Ta-Lib d'origine | TradingView | Sierra Chart | MQL5 | FM Labs | Pro vrai code | Utilisateur 42
Vous vous sentez généreux, comme le package ou que vous voulez le voir devenir plus un package mature?


