
La mise en œuvre officielle de GFT, un modèle de fondation croisée croisée sur les graphiques. Le logo est généré par Dall · E 3.
Rédigé par Zehong Wang, Zheyuan Zhang, Nitesh v Chawla, Chuxu Zhang et Yanfang Ye.
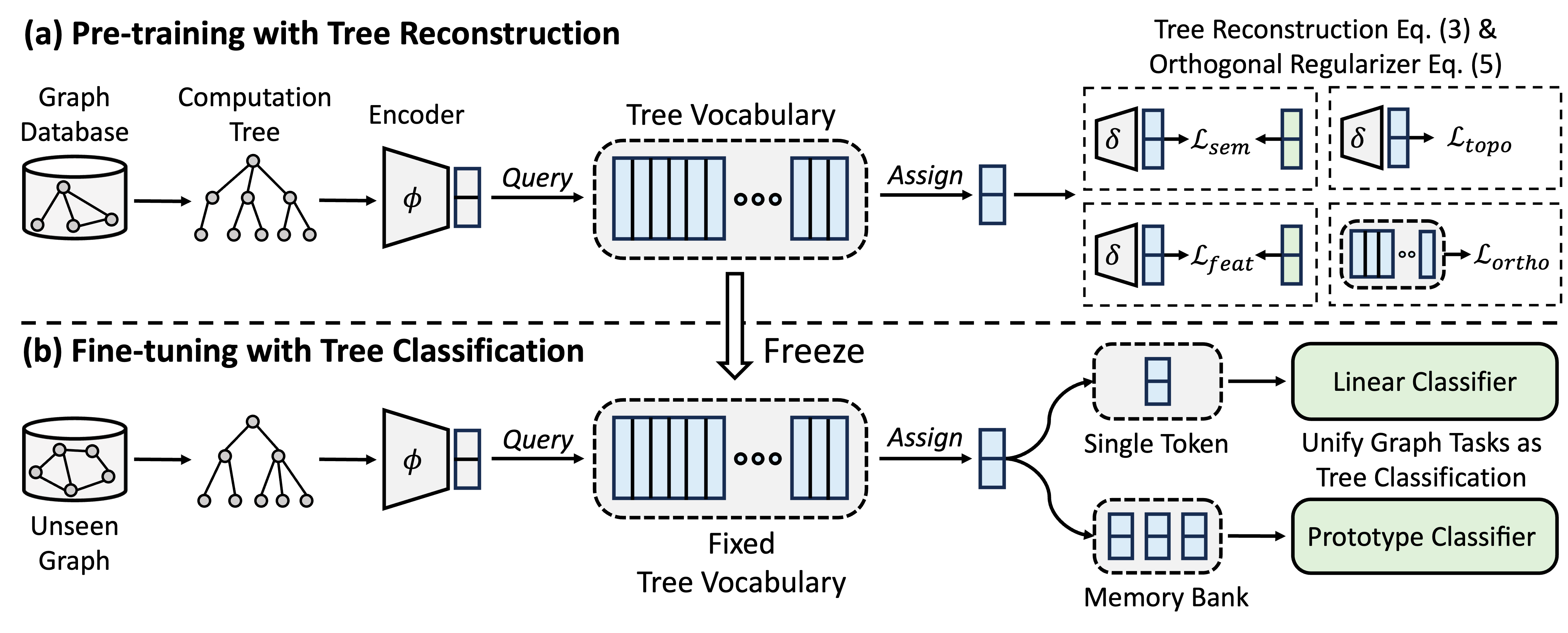
GFT est un modèle de fondation de graphe à domaine croisé et transversal, qui traite les arbres de calcul comme les modèles transférables pour obtenir un vocabulaire arborescence transférable. De plus, GFT fournit un cadre unifié pour aligner les tâches liées aux graphiques, permettant un modèle graphique unique, par exemple, GNN, pour gérer conjointement les tâches au niveau du nœud, au niveau des bords et au niveau du graphique.
Pendant la pré-formation, le modèle code les connaissances générales d'une base de données de graphiques dans un vocabulaire d'arbre à travers une tâche de reconstruction d'arbre. Dans le réglage fin, le vocabulaire des arbres savant est appliqué pour unifier les tâches liées aux graphiques en tant que tâches de classification des arbres, adaptant les connaissances générales acquises à des tâches spécifiques.
Vous pouvez utiliser Conda pour installer l'environnement. Veuillez exécuter le script suivant. Nous exécutons toutes les expériences sur un seul GPU A40 48G, mais un GPU avec une mémoire 24g est suffisant pour gérer tous les ensembles de données avec mini-lot.
conda env create -f environment.yml
conda activate GFT
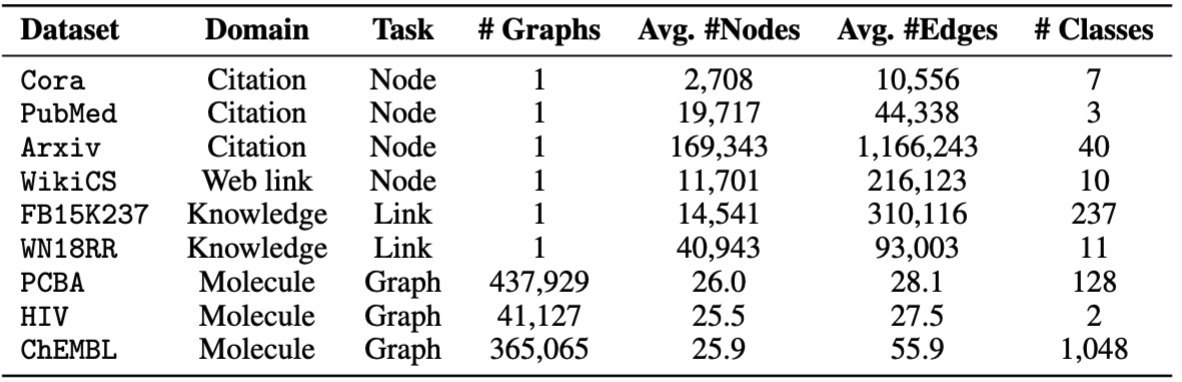
Nous utilisons des ensembles de données fournis par OFA. Vous pouvez exécuter le pretrain.py pour télécharger automatiquement les ensembles de données, qui seront téléchargés dans /data Folder par défaut. Le pipeline préparera automatiquement les ensembles de données en convertissant les descriptions textuelles en intégres textuels.
Alternativement, vous pouvez télécharger nos ensembles de données prétraités et se décompresser dans le dossier /data .
Le code de GFT est présenté dans le dossier /GFT . La structure est la suivante.
└── GFT
├── pretrain.py
├── finetune.py
├── dataset
│ ├── ...
│ └── process_datasets.py
├── model
│ ├── encoder.py
│ ├── vq.py
│ ├── pt_model.py
│ └── ft_model.py
├── task
│ ├── node.py
│ ├── link.py
│ └── graph.py
└── utils
├── args.py
├── loader.py
└── ...
Vous pouvez exécuter pretrain.py pour pré-formation sur un large éventail de graphiques et finetune.py pour l'adaptation à certaines tâches en aval avec des finetuning de base ou un apprentissage à quelques coups.
Pour reproduire les résultats, nous fournissons des hyper-paramètres détaillés pour la pré-entraînement et le finetuning, maintenus dans config/pretrain.yaml et config/finetune.yaml , respectivement. Pour tirer parti des hyper-paramètres par défaut, nous fournissons une commande --use_params pour la prétraitement et le finetune.
# Pretraining with default hyper-parameters
python GFT/pretrain.py --use_params
# Finetuning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora
# Few-shot learning on Cora with default hyper-parameters
python GFT/finetune.py --use_params --dataset cora --setting few_shot
Pour les finetuning, nous fournissons huit ensembles de données, dont cora , pubmed , wikics , arxiv , WN18RR , FB15K237 , chemhiv et chempcba .
Alternativement, vous pouvez exécuter le script pour reproduire les expériences.
# Pretraining with default hyper-parameters
sh script/pretrain.sh
# Finetuning on all datasets with default hyper-parameters
sh script/finetune.sh
# Few-shot learning on all datasets with default hyper-parameters
sh script/few_shot.sh
Remarque: Le modèle prétrainé sera stocké dans ckpts/pretrain_model/ par défaut.
# The basic command for pretraining GFT
python GFT/pretrain.py
Lorsque vous exécutez pretrain.py , vous pouvez personnaliser les ensembles de données de pré-formation et les hyper-paramètres.
Vous pouvez utiliser --pretrain_dataset (ou --pt_data ) pour définir les ensembles de données prétraités utilisés et les poids correspondants. La configuration de données prédéfinie est en config/pt_data.yaml , avec les structures suivantes.
all:
cora: 5
pubmed: 5
arxiv: 5
wikics: 5
WN18RR: 5
FB15K237: 10
chemhiv: 1
chemblpre: 0.1
chempcba: 0.1
...
Dans le cas ci-dessus, le all est le nom du paramètre, ce qui signifie que tous les ensembles de données sont utilisés pour pré-formation. Pour chaque ensemble de données, il existe une paire de valeurs de clé, où la clé est le nom de l'ensemble de données et la valeur est le poids d'échantillonnage. Par exemple, cora: 5 signifie que l'ensemble de données cora sera échantillonné 5 fois dans une seule époque. Vous pouvez concevoir votre propre combinaison d'ensemble de données pour la pré-formation de GFT.
Vous pouvez personnaliser la phase de pré-formation en modifiant les hyper-paramètres du codeur, la quantification des vecteurs, la formation des modèles.
--pretrain_dataset : indiquez l'ensemble de données de pré-formation. Identique à ce qui précède.--use_params : Utilisez les hyper-paramètres prédéfinis.--seed : la graine utilisée pour la pré-formation.--hidden_dim : la dimension dans la couche cachée de gnns.--num_layers : les couches GNN.--activation : la fonction d'activation.--backbone : Le Gnn de l'épine dorsale.--normalize : la couche de normalisation.--dropout : l'abandon de la couche GNN.--code_dim : la dimension de chaque code dans le vocabulaire.--codebook_size : le nombre de codes dans le vocabulaire.--codebook_head : le nombre de têtes de livre de codes. Si le nombre est supérieur à 1, vous utiliserez conjointement plusieurs vocabulaires.--codebook_decay : le taux de désintégration des codes.--commit_weight : le poids du terme d'engagement.--pretrain_epochs : le nombre d'époches.--pretrain_lr : le taux d'apprentissage.--pretrain_weight_decay : le poids du régularisateur L2.--pretrain_batch_size : la taille du lot.--feat_p : le taux de corruption des fonctionnalités.--edge_p : le taux de corruption Edge / Structure.--topo_recon_ratio : Le rapport des bords doit être reconstruit.--feat_lambda : le poids de la perte de fonctionnalités.--topo_lambda : Le poids de la perte de topologie.--topo_sem_lambda : Le poids de la perte de topologie dans les caractéristiques des bords de reconstruction.--sem_lambda : le poids de la perte sémantique.--sem_encoder_decay : le taux de mise à jour de la quantité de mouvement pour l'encodeur sémantique. # The basic command for adapting GFT on downstream tasks via finetuning.
python GFT/finetune.py
Vous pouvez définir --dataset pour indiquer l'ensemble de données en aval, et --use_params pour utiliser les hyper-paramètres prédéfinis pour chaque ensemble de données. Les autres hyper-paramètres que vous pouvez indiquer sont présentés comme suit.
Pour les graphiques avec 1 fractionnement prédéfini, vous pouvez définir --repeat pour mener plusieurs expériences.
--hidden_dim : la dimension dans la couche cachée de gnns.--num_layers : les couches GNN.--activation : la fonction d'activation.--backbone : Le Gnn de l'épine dorsale.--normalize : la couche de normalisation.--dropout : l'abandon de la couche GNN.--code_dim : la dimension de chaque code dans le vocabulaire.--codebook_size : le nombre de codes dans le vocabulaire.--codebook_head : le nombre de têtes de livre de codes. Si le nombre est supérieur à 1, vous utiliserez conjointement plusieurs vocabulaires.--codebook_decay : le taux de désintégration des codes.--commit_weight : le poids du terme d'engagement.--finetune_epochs : le nombre d'époches.--finetune_lr : le taux d'apprentissage.--early_stop : l'époque maximale à arrêts précoces.--batch_size : Si défini sur 0, effectuez une formation complète sur le graphique. --lambda_proto : le poids du classificateur de prototype dans Finetuning.
--lambda_act : Le poids du classificateur linéaire en finetuning.
--trade_off : le compromis entre l'utilisation de prototype Classier ou l'utilisation du classificateur linéaire dans l'inférence.
Vous pouvez ajouter --no_lin_clf ou --no_proto_clf pour éviter d'utiliser le classificateur linéaire ou le classificateur de prototype, respectivement. Notez que ces deux termes sont des conflits, car vous devez utiliser au moins un classificateur.
# The basic command for adaptation GFT on downstream tasks via few-shot learning.
python GFT/finetune.py --setting few_shot
Vous pouvez définir --dataset pour indiquer l'ensemble de données en aval, et --use_params pour utiliser les hyper-paramètres prédéfinis pour chaque ensemble de données. Les autres hyper-paramètres que vous pouvez indiquer sont présentés comme suit.
Les hyper-paramètres dédiés à un apprentissage à quelques tirs sont
--n_train : Le nombre d'instances de formation par classe pour les finening du modèle. Notez que le petit n_train atteint des performances souhaitables --n_task : le nombre de tâches échantillonnées.--n_way : le nombre de façons.--n_query : la taille de la requête définie par voie.--n_shot : la taille de l'ensemble de support par voie.--hidden_dim : la dimension dans la couche cachée de gnns.--num_layers : les couches GNN.--activation : la fonction d'activation.--backbone : Le Gnn de l'épine dorsale.--normalize : la couche de normalisation.--dropout : l'abandon de la couche GNN.--code_dim : la dimension de chaque code dans le vocabulaire.--codebook_size : le nombre de codes dans le vocabulaire.--codebook_head : le nombre de têtes de livre de codes. Si le nombre est supérieur à 1, vous utiliserez conjointement plusieurs vocabulaires.--codebook_decay : le taux de désintégration des codes.--commit_weight : le poids du terme d'engagement.--finetune_epochs : le nombre d'époches.--finetune_lr : le taux d'apprentissage.--early_stop : l'époque maximale à arrêts précoces.--batch_size : Si défini sur 0, effectuez une formation complète sur le graphique. --lambda_proto : le poids du classificateur de prototype dans Finetuning.
--lambda_act : Le poids du classificateur linéaire en finetuning.
--trade_off : le compromis entre l'utilisation de prototype Classier ou l'utilisation du classificateur linéaire dans l'inférence.
Vous pouvez ajouter --no_lin_clf ou --no_proto_clf pour éviter d'utiliser le classificateur linéaire ou le classificateur de prototype, respectivement. Notez que ces deux termes sont des conflits, car vous devez utiliser au moins un classificateur.
Les résultats expérimentaux peuvent varier en raison de l'initialisation randomisée pendant la pré-entraînement. Nous fournissons les résultats expérimentaux en utilisant différentes graines aléatoires (c.-à-d. 1-5) en pré-formation pour montrer l'impact potentiel de l'initialisation aléatoire.
| Cora | Pubment | Wiki-cs | Arxiv | Wn18rr | FB15K237 | VIH | PCBA | Moyenne | |
|---|---|---|---|---|---|---|---|---|---|
| Graine = 1 | 78,58 ± 0,90 | 77,55 ± 1,54 | 79,38 ± 0,57 | 72,24 ± 0,16 | 91,56 ± 0,33 | 89,67 ± 0,35 | 72,69 ± 1,93 | 78,24 ± 0,23 | 79,99 |
| Graine = 2 | 78,27 ± 1,26 | 76,41 ± 1,36 | 79,36 ± 0,62 | 72,13 ± 0,24 | 91,72 ± 0,19 | 89,66 ± 0,31 | 71,62 ± 2,45 | 78,20 ± 0,33 | 79.67 |
| Graine = 3 | 78,16 ± 1,62 | 76,28 ± 1,37 | 79,32 ± 0,65 | 72,13 ± 0,30 | 91,57 ± 0,44 | 89,78 ± 0,23 | 71,58 ± 2,28 | 78,12 ± 0,37 | 79.62 |
| Graine = 4 | 78,42 ± 1,37 | 75,76 ± 1,58 | 79,44 ± 0,62 | 72,36 ± 0,34 | 91,70 ± 0,24 | 89,73 ± 0,21 | 72,57 ± 2,46 | 78,34 ± 0,27 | 79.79 |
| Graine = 5 | 78,56 ± 1,62 | 76,49 ± 2,00 | 79,27 ± 0,55 | 72,18 ± 0,26 | 91,47 ± 0,39 | 89,80 ± 0,19 | 72,27 ± 0,93 | 78,31 ± 0,34 | 79.79 |
| Signalé | 78,62 ± 1,21 | 77,19 ± 1,99 | 79,39 ± 0,42 | 71,93 ± 0,12 | 91,91 ± 0,34 | 89,72 ± 0,20 | 72,67 ± 1,38 | 77,90 ± 0,64 | 79.92 |
Pour mieux assurer la reproductibilité, nous fournissons les points de contrôle de la semence = 1 dans ce lien. Nous sélectionnons cela en raison de ses meilleures performances moyennes. Vous pouvez décompresser le fichier téléchargé dans le chemin ckpts/pretrain_model/ , et définir le --pt_seed 1 lors de l'utilisation finetune.py pour tirer parti de nos points de contrôle fournis.
Veuillez contacter [email protected] ou ouvrir un problème si vous avez des questions.
Si vous trouvez que le dépôt est utile pour vos recherches, veuillez citer correctement le papier d'origine.
@inproceedings { wang2024gft ,
title = { GFT: Graph Foundation Model with Transferable Tree Vocabulary } ,
author = { Wang, Zehong and Zhang, Zheyuan and Chawla, Nitesh V and Zhang, Chuxu and Ye, Yanfang } ,
booktitle = { The Thirty-eighth Annual Conference on Neural Information Processing Systems } ,
year = { 2024 } ,
url = { https://openreview.net/forum?id=0MXzbAv8xy }
}Ce référentiel est basé sur la base de code OFA, PYG, OGB et VQ. Merci pour leur partage!


