flash attention
v2.7.0
Ce référentiel fournit la mise en œuvre officielle de FlashAtttention et FlashAtttention-2 des articles suivants.
Flashattention: une attention exacte rapide et économe en mémoire avec Io-sensender
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, Christopher Ré
Papier: https://arxiv.org/abs/2205.14135
IEEE Spectrum Article sur notre soumission à la référence MLPerf 2.0 à l'aide de FlashAtttention. 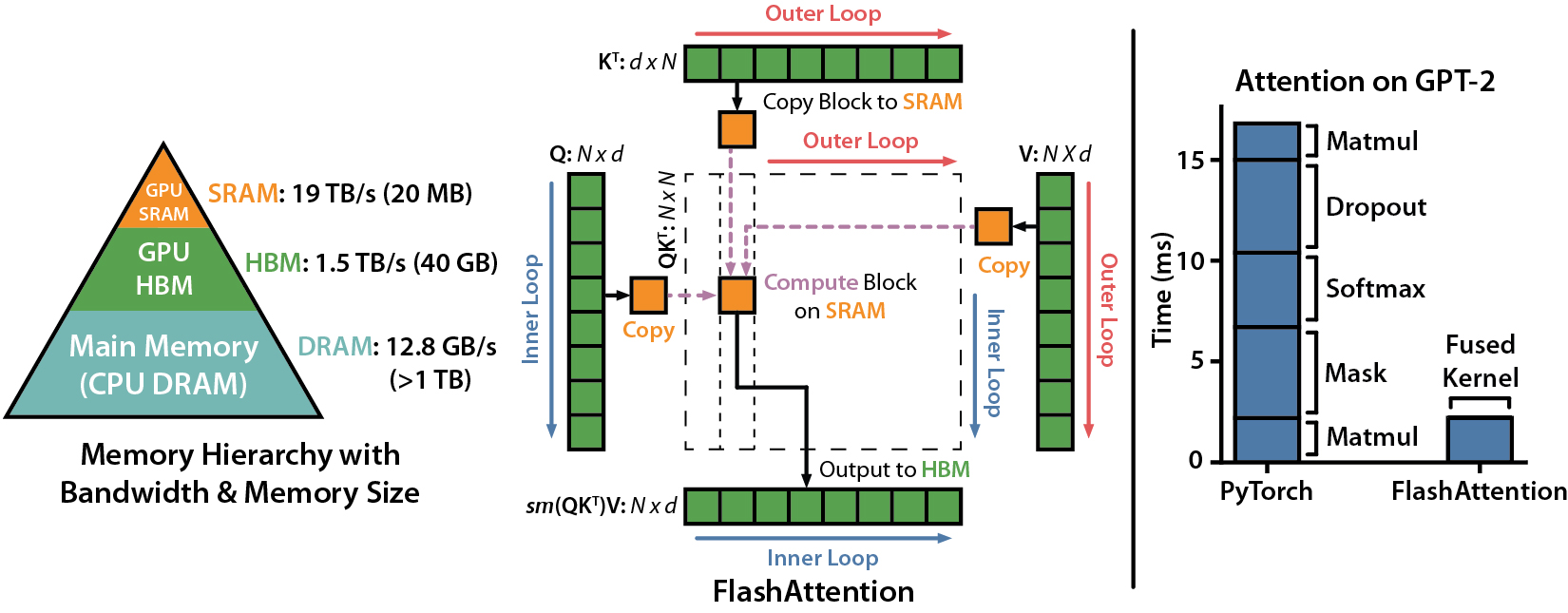
Flashattention-2: une attention plus rapide avec un meilleur parallélisme et un meilleur partitionnement de travail
Tri-dao
Papier: https://tridao.me/publications/flash2/flash2.pdf

Nous avons été très heureux de voir Flashattention largement adopté en si peu de temps après sa libération. Cette page contient une liste partielle d'endroits où Flashattention est utilisé.
FlashAtttention et FlashAttention-2 sont gratuites à utiliser et à modifier (voir la licence). Veuillez citer et créditer Flashattention si vous l'utilisez.
FlashAtttention-3 est optimisée pour les GPU de trémie (par exemple H100).
Blogpost: https://tridao.me/blog/2024/flash3/
Papier: https://tridao.me/publications/flash3/flash3.pdf
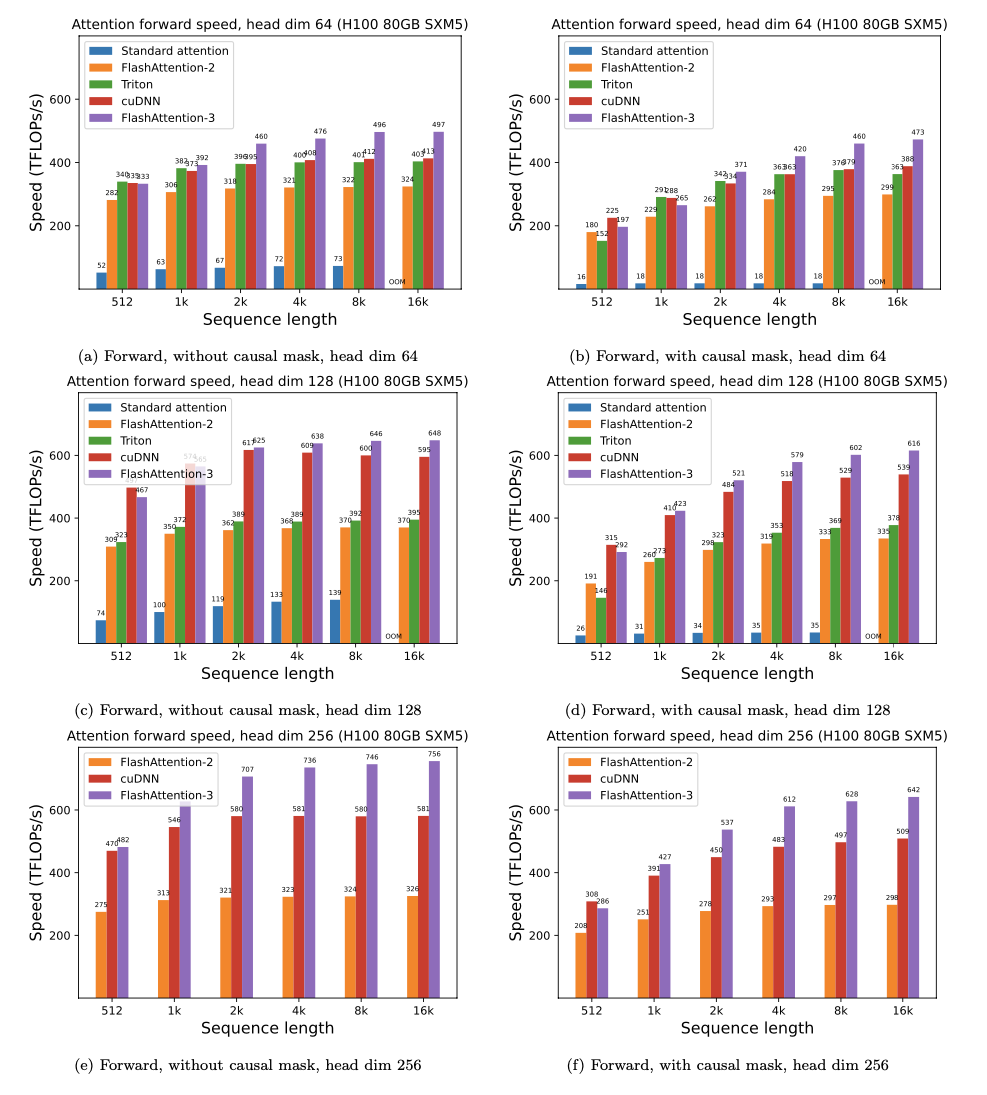
Il s'agit d'une version bêta pour les tests / analyses comparatives avant de l'intégrer avec le reste du référentiel.
Actuellement publié:
Exigences: GPU H100 / H800, CUDA> = 12,3.
Pour l'instant, nous recommandons fortement CUDA 12.3 pour les meilleures performances.
Pour installer:
cd hopper
python setup.py installPour exécuter le test:
export PYTHONPATH= $PWD
pytest -q -s test_flash_attn.pyExigences:
packaging Python Python ( pip install packaging )ninja python ( pip install ninja ) * * Assurez-vous que ninja est installé et qu'il fonctionne correctement (par exemple, ninja --version puis echo $? Devrait retourner le code de sortie 0). Sinon (parfois ninja --version , alors echo $? Renvoie un code de sortie non nul), désinstallez puis réinstallez ninja ( pip uninstall -y ninja && pip install ninja ). Sans ninja , la compilation peut prendre très longtemps (2h) car elle n'utilise pas plusieurs cœurs de processeur. Avec ninja la compilation prend 3 à 5 minutes sur une machine à 64 cœurs à l'aide de la boîte à outils CUDA.
Pour installer:
pip install flash-attn --no-build-isolationVous pouvez également compiler à partir de la source:
python setup.py install Si votre machine a moins de 96 Go de RAM et beaucoup de cœurs de processeur, ninja pourrait exécuter trop de travaux de compilation parallèle qui pourraient épuiser la quantité de RAM. Pour limiter le nombre de travaux de compilation parallèle, vous pouvez définir la variable d'environnement MAX_JOBS :
MAX_JOBS=4 pip install flash-attn --no-build-isolation Interface: src/flash_attention_interface.py
Exigences:
Nous recommandons le conteneur Pytorch de NVIDIA, qui dispose de tous les outils requis pour installer Flashattention.
Flashattention-2 avec CUDA prend actuellement en charge:
La version ROCM utilise Composable_Kernel comme backend. Il fournit la mise en œuvre de Flashattention-2.
Exigences:
Nous recommandons le conteneur Pytorch de ROCM, qui dispose de tous les outils requis pour installer Flashattention.
FlashAtttention-2 avec ROCM prend actuellement en charge:
Les fonctions principales mettent en œuvre l'attention du produit à point à l'échelle (softmax (q @ k ^ t * softmax_scale) @ v):
from flash_attn import flash_attn_qkvpacked_func , flash_attn_func flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
If Q, K, V are already stacked into 1 tensor, this function will be faster than
calling flash_attn_func on Q, K, V since the backward pass avoids explicit concatenation
of the gradients of Q, K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between [i - window_size[0], i + window_size[1]] inclusive.
Arguments:
qkv: (batch_size, seqlen, 3, nheads, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of (-alibi_slope * |i - j|) is added to
the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False ,
window_size = ( - 1 , - 1 ), alibi_slopes = None , deterministic = False ):
"""dropout_p should be set to 0.0 during evaluation
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k: (batch_size, seqlen, nheads_k, headdim)
v: (batch_size, seqlen, nheads_k, headdim)
dropout_p: float. Dropout probability.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
deterministic: bool. Whether to use the deterministic implementation of the backward pass,
which is slightly slower and uses more memory. The forward pass is always deterministic.
Return:
out: (batch_size, seqlen, nheads, headdim).
""" def flash_attn_with_kvcache (
q ,
k_cache ,
v_cache ,
k = None ,
v = None ,
rotary_cos = None ,
rotary_sin = None ,
cache_seqlens : Optional [ Union [( int , torch . Tensor )]] = None ,
cache_batch_idx : Optional [ torch . Tensor ] = None ,
block_table : Optional [ torch . Tensor ] = None ,
softmax_scale = None ,
causal = False ,
window_size = ( - 1 , - 1 ), # -1 means infinite context window
rotary_interleaved = True ,
alibi_slopes = None ,
):
"""
If k and v are not None, k_cache and v_cache will be updated *inplace* with the new values from
k and v. This is useful for incremental decoding: you can pass in the cached keys/values from
the previous step, and update them with the new keys/values from the current step, and do
attention with the updated cache, all in 1 kernel.
If you pass in k / v, you must make sure that the cache is large enough to hold the new values.
For example, the KV cache could be pre-allocated with the max sequence length, and you can use
cache_seqlens to keep track of the current sequence lengths of each sequence in the batch.
Also apply rotary embedding if rotary_cos and rotary_sin are passed in. The key @k will be
rotated by rotary_cos and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If causal or local (i.e., window_size != (-1, -1)), the query @q will be rotated by rotary_cos
and rotary_sin at indices cache_seqlens, cache_seqlens + 1, etc.
If not causal and not local, the query @q will be rotated by rotary_cos and rotary_sin at
indices cache_seqlens only (i.e. we consider all tokens in @q to be at position cache_seqlens).
See tests/test_flash_attn.py::test_flash_attn_kvcache for examples of how to use this function.
Supports multi-query and grouped-query attention (MQA/GQA) by passing in KV with fewer heads
than Q. Note that the number of heads in Q must be divisible by the number of heads in KV.
For example, if Q has 6 heads and K, V have 2 heads, head 0, 1, 2 of Q will attention to head
0 of K, V, and head 3, 4, 5 of Q will attention to head 1 of K, V.
If causal=True, the causal mask is aligned to the bottom right corner of the attention matrix.
For example, if seqlen_q = 2 and seqlen_k = 5, the causal mask (1 = keep, 0 = masked out) is:
1 1 1 1 0
1 1 1 1 1
If seqlen_q = 5 and seqlen_k = 2, the causal mask is:
0 0
0 0
0 0
1 0
1 1
If the row of the mask is all zero, the output will be zero.
If window_size != (-1, -1), implements sliding window local attention. Query at position i
will only attend to keys between
[i + seqlen_k - seqlen_q - window_size[0], i + seqlen_k - seqlen_q + window_size[1]] inclusive.
Note: Does not support backward pass.
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no block_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a block_table (i.e. paged KV cache)
k [optional]: (batch_size, seqlen_new, nheads_k, headdim). If not None, we concatenate
k with k_cache, starting at the indices specified by cache_seqlens.
v [optional]: (batch_size, seqlen_new, nheads_k, headdim). Similar to k.
rotary_cos [optional]: (seqlen_ro, rotary_dim / 2). If not None, we apply rotary embedding
to k and q. Only applicable if k and v are passed in. rotary_dim must be divisible by 16.
rotary_sin [optional]: (seqlen_ro, rotary_dim / 2). Similar to rotary_cos.
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
block_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
cache_batch_idx: (batch_size,), dtype torch.int32. The indices used to index into the KV cache.
If None, we assume that the batch indices are [0, 1, 2, ..., batch_size - 1].
If the indices are not distinct, and k and v are provided, the values updated in the cache
might come from any of the duplicate indices.
softmax_scale: float. The scaling of QK^T before applying softmax.
Default to 1 / sqrt(headdim).
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
window_size: (left, right). If not (-1, -1), implements sliding window local attention.
rotary_interleaved: bool. Only applicable if rotary_cos and rotary_sin are passed in.
If True, rotary embedding will combine dimensions 0 & 1, 2 & 3, etc. If False,
rotary embedding will combine dimensions 0 & rotary_dim / 2, 1 & rotary_dim / 2 + 1
(i.e. GPT-NeoX style).
alibi_slopes: (nheads,) or (batch_size, nheads), fp32. A bias of
(-alibi_slope * |i + seqlen_k - seqlen_q - j|)
is added to the attention score of query i and key j.
Return:
out: (batch_size, seqlen, nheads, headdim).
"""Pour voir comment ces fonctions sont utilisées dans une couche d'attention multi-tête (qui comprend la projection QKV, la projection de sortie), voir l'implémentation MHA.
Mise à niveau de Flashattention (1.x) à FlashAtttention-2
Ces fonctions ont été renommées:
flash_attn_unpadded_func -> flash_attn_varlen_funcflash_attn_unpadded_qkvpacked_func -> flash_attn_varlen_qkvpacked_funcflash_attn_unpadded_kvpacked_func -> flash_attn_varlen_kvpacked_funcSi les entrées ont les mêmes longueurs de séquence dans le même lot, il est plus simple et plus rapide d'utiliser ces fonctions:
flash_attn_qkvpacked_func ( qkv , dropout_p = 0.0 , softmax_scale = None , causal = False ) flash_attn_func ( q , k , v , dropout_p = 0.0 , softmax_scale = None , causal = False )Si seqlen_q! = Seqlen_k et causal = true, le masque causal est aligné dans le coin inférieur droit de la matrice d'attention, au lieu du coin supérieur gauche.
Par exemple, si seqlen_q = 2 et seqlen_k = 5, le masque causal (1 = keep, 0 = masqué) est:
v2.0:
1 0 0 0 0
1 1 0 0 0
v2.1:
1 1 1 1 0
1 1 1 1 1
Si seqlen_q = 5 et seqlen_k = 2, le masque causal est:
v2.0:
1 0
1 1
1 1
1 1
1 1
v2.1:
0 0
0 0
0 0
1 0
1 1
Si la ligne du masque est tout zéro, la sortie sera nulle.
Optimiser l'inférence (décodage itératif) lorsque la requête a une très petite longueur de séquence (par exemple, longueur de séquence de requête = 1). Le goulot d'étranglement ici est de charger le cache KV aussi rapidement que possible, et nous avons divisé le chargement sur différents blocs de threads, avec un noyau séparé pour combiner les résultats.
Voir la fonction flash_attn_with_kvcache avec plus de fonctionnalités pour l'inférence (effectuer une incorporation rotative, mettre à jour le cache KV en place).
Merci à l'équipe XFORMERS, et en particulier Daniel Haziza, pour cette collaboration.
Implémentez l'attention des fenêtres coulissantes (c'est-à-dire l'attention locale). Merci à Mistral AI et en particulier à Timothee Lacroix pour cette contribution. La fenêtre coulissante a été utilisée dans le modèle Mistral 7B.
Mettre en œuvre Alibi (Press et al., 2021). Merci à Sanghun Cho de Kakao Brain pour cette contribution.
Mettre en œuvre une passe arrière déterministe. Merci aux ingénieurs de Meituan pour cette contribution.
Soutenir le cache KV Paged (c.-à-d. PagedAntité). Merci à @beginlner pour cette contribution.
Soutenez l'attention avec le softcapping, comme utilisé dans les modèles Gemma-2 et Grok. Merci à @Narsil et @LucidRains pour cette contribution.
Merci à @ ANI300 pour cette contribution.
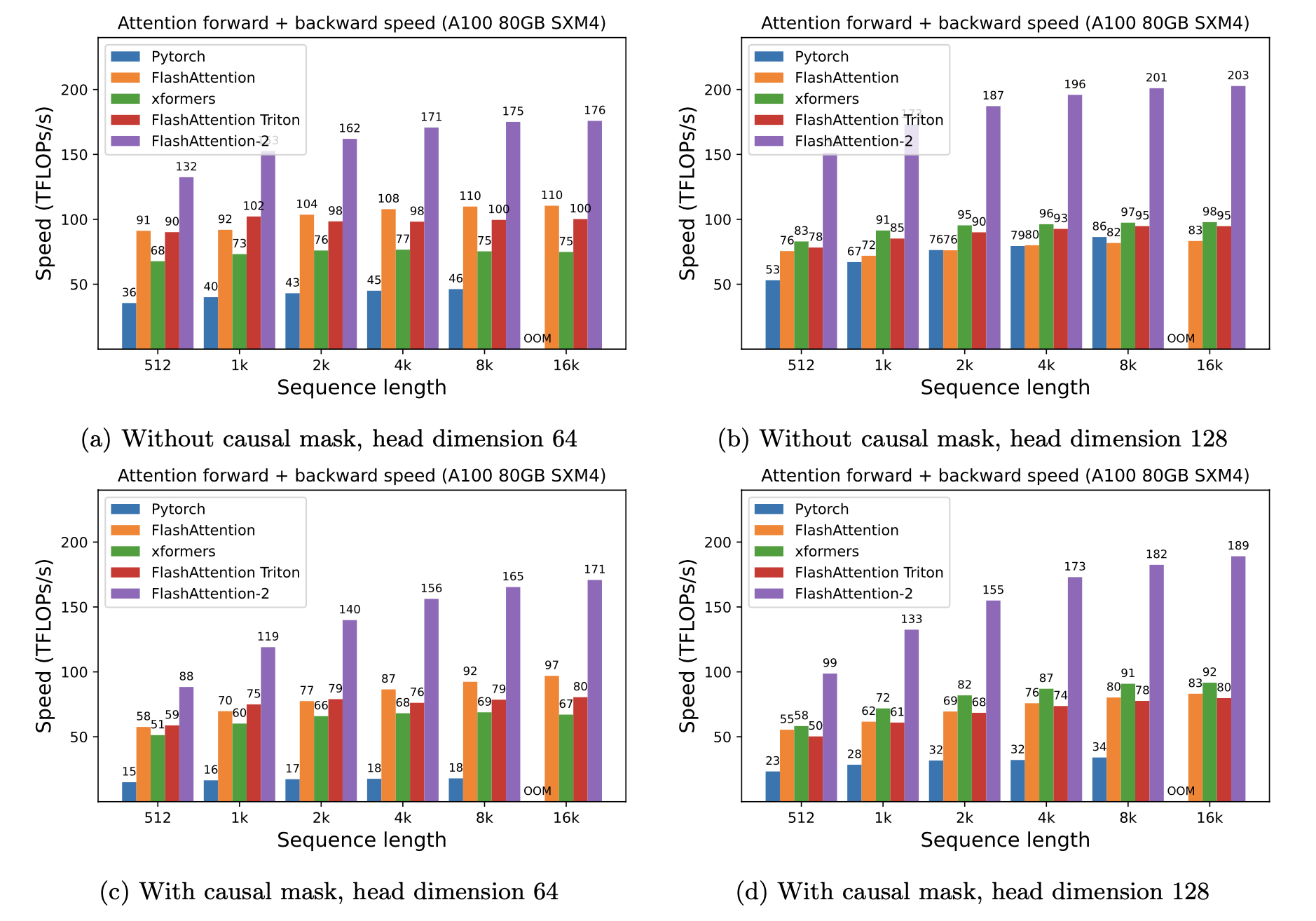
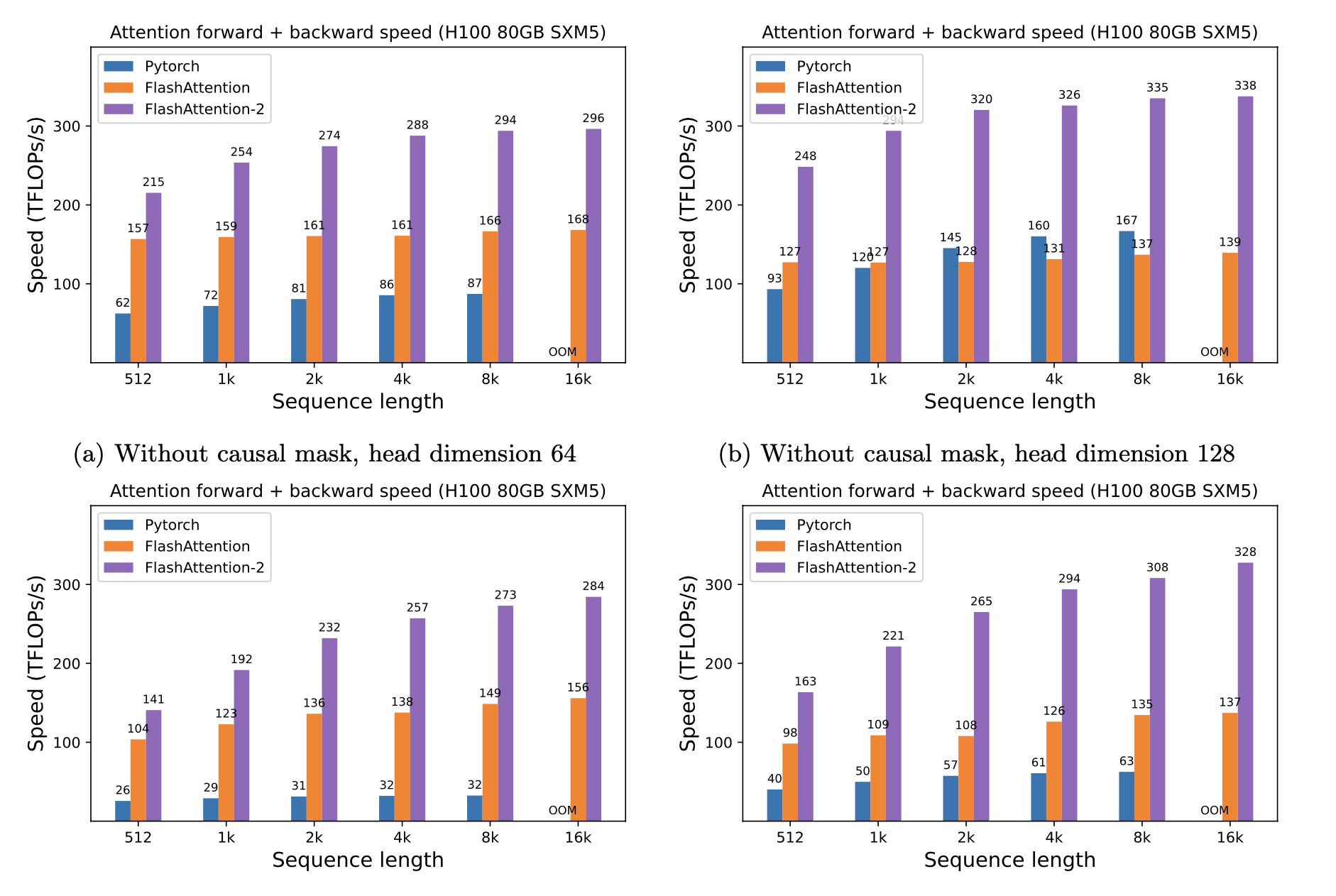
Nous présentons la vitesse attendue (combinée avant + pass arrière) et les économies de mémoire en utilisant Flashattention contre l'attention standard de Pytorch, en fonction de la longueur de séquence, de différents GPU (accélérer dépend de la bande passante de mémoire - nous voyons plus de vitesses de la mémoire GPU plus lente).
Nous avons actuellement des repères pour ces GPU:
Nous affichons une accélération de FlashAntiser en utilisant ces paramètres:
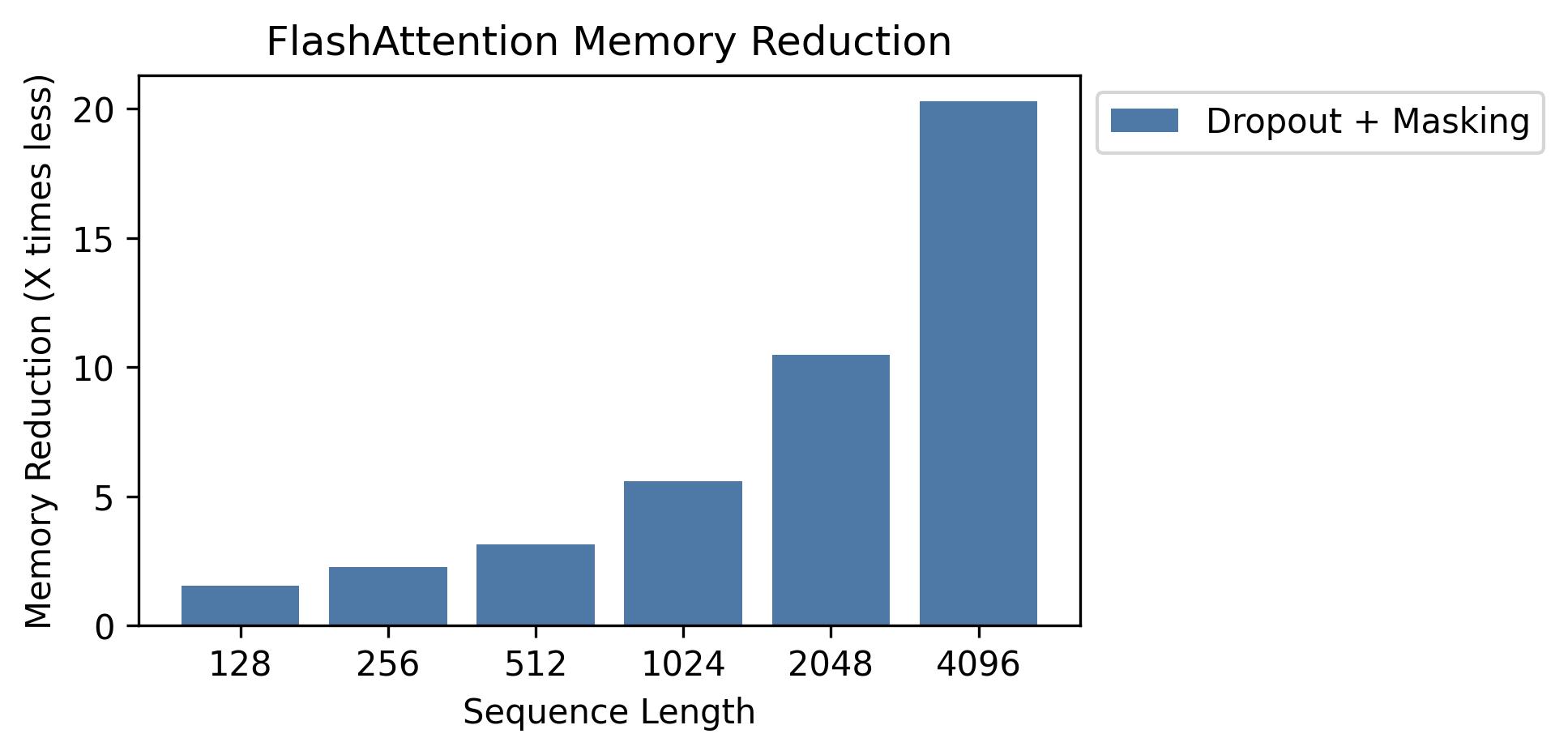
Nous montrons des économies de mémoire dans ce graphique (notez que l'empreinte de la mémoire est la même, peu importe si vous utilisez un abandon ou un masquage). Les économies de mémoire sont proportionnelles à la longueur des séquences - car l'attention standard a une longueur quadratique de la mémoire, tandis que Flashattention a une mémoire linéaire en longueur de séquence. Nous voyons 10x économies de mémoire à la longueur de séquence 2k et 20x à 4k. En conséquence, FlashAtttention peut évoluer à des longueurs de séquence beaucoup plus longues.
Nous avons publié l'implémentation complète du modèle GPT. Nous fournissons également des implémentations optimisées d'autres couches (par exemple, MLP, tempête, perte entre entropie, intégration rotative). Dans l'ensemble, cela accélère la formation de 3-5x par rapport à la mise en œuvre de base de HuggingFace, atteignant jusqu'à 225 Tflops / sec par A100, équivalent à 72% d'utilisation des flops du modèle (nous n'avons besoin d'aucun point de contrôle d'activation).
Nous incluons également un script d'entraînement pour former GPT2 sur OpenWebText et GPT3 sur la pile.
Phil Tillet (Openai) a une implémentation expérimentale de Flashattention dans Triton: https://github.com/openai/triton/blob/master/python/tutorials/06-fused-attention.py
Comme Triton est une langue de niveau supérieur que CUDA, il pourrait être plus facile de comprendre et d'expérimenter. Les notations dans la mise en œuvre de Triton sont également plus proches de ce qui est utilisé dans notre article.
Nous avons également une implémentation expérimentale dans Triton qui prend en charge le biais d'attention (par exemple Alibi): https://github.com/dao-ailab/flash-attention/blob/main/flash_attn/flash_attn_triton.py
Nous testons que Flashattention produit la même sortie et le même gradient qu'une implémentation de référence, jusqu'à une certaine tolérance numérique. En particulier, nous vérifions que l'erreur numérique maximale de Flashattention est au plus deux fois l'erreur numérique d'une implémentation de base dans Pytorch (pour différentes dimensions de la tête, DTYPE d'entrée, longueur de séquence, causal / non causal).
Pour exécuter les tests:
pytest -q -s tests/test_flash_attn.pyCette nouvelle version de Flashattention-2 a été testée sur plusieurs modèles de style GPT, principalement sur les GPU A100.
Si vous rencontrez des bogues, veuillez ouvrir un problème GitHub!
Pour exécuter les tests:
pytest tests/test_flash_attn_ck.pySi vous utilisez cette base de code, ou si vous avez trouvé notre travail précieux, veuillez citer:
@inproceedings{dao2022flashattention,
title={Flash{A}ttention: Fast and Memory-Efficient Exact Attention with {IO}-Awareness},
author={Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R{'e}, Christopher},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
@inproceedings{dao2023flashattention2,
title={Flash{A}ttention-2: Faster Attention with Better Parallelism and Work Partitioning},
author={Dao, Tri},
booktitle={International Conference on Learning Representations (ICLR)},
year={2024}
}


