Face Shape Classification using CNN
1.0.0

Il s'agit d'un projet de classification d'image pour identifier 5 formes de visage féminines à l'aide de réseaux neuronaux convolutionnels (CNN) . Je l'ai terminé comme mon projet Capstone pour les données de la science des données avec l'Assemblée générale (octobre 2020).
Ce projet est également déployé sous forme d'application Web à l'aide de Stremlit sur Heroku. Si vous êtes intéressé, vérifiez la forme de votre visage sur myfaceshape.herokuapp.com
Sur la base de l'examen des consommateurs de Deloitte, les consommateurs exigent une expérience plus personnalisée, mais l'essai reste faible. Dans l'industrie de la beauté et de la mode, plus de 40% des adultes âgés de 16 à 39 ans sont intéressés par l'offre personnalisée, tandis que l'essai n'est que de 10% à 14%. Parmi ceux qui sont intéressés, ~ 80% sont prêts à payer au moins 10% de prix plus élevés.
En étant en mesure de classer les formes de visage, permettra aux marques d'offrir des solutions plus personnalisées pour accroître la satisfaction des clients, tout en augmentant la marge du positionnement premium. L'exemple de cas d'utilisation est:
Pour ce projet, j'utiliserai l'approche d'apprentissage en profondeur avec des réseaux de neurones convolutionnels (CNN) pour classer 5 formes de visage femelles différentes (cœur, oblong, ovale, rond, carré). Le modèle qui était le score de précision le plus élevé sera choisi.
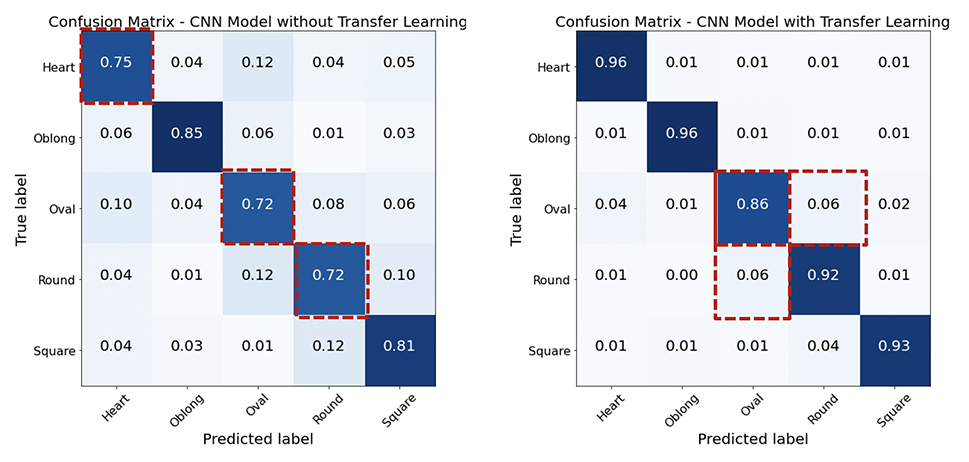
J'ai exploré 2 approches de CNN en construisant à partir de zéro par rapport à l'apprentissage du trasfer avec l'architecture VGG-16 et des poids pré-formés de VGGFACE. L'approche d'apprentissage du transfert a contribué à une précision accrue, tandis que la forme de visage la plus mal classifiée est «ovale».
Le prétraitement de l'image a également joué un rôle important dans la réduction de la sur-ajustement et de l'augmentation de la précision de validation. Les conducteurs clés sont:
L'ensemble de données de forme de visage est un ensemble de données de Kaggle par Niten Lama.
Cet ensemble de données comprend un total de 5000 images des célébrités féminines du monde entier qui sont classées en forme de visage à savoir:
Chaque catégorie se compose de 1000 images (800 pour la formation: 200 pour les tests)
Le prétraitement des images est un facteur critique pour réduire le sur-ajustement du modèle à l'ensemble de données de formation et augmenter la précision de validation. Les étapes suivantes ont été explorées:
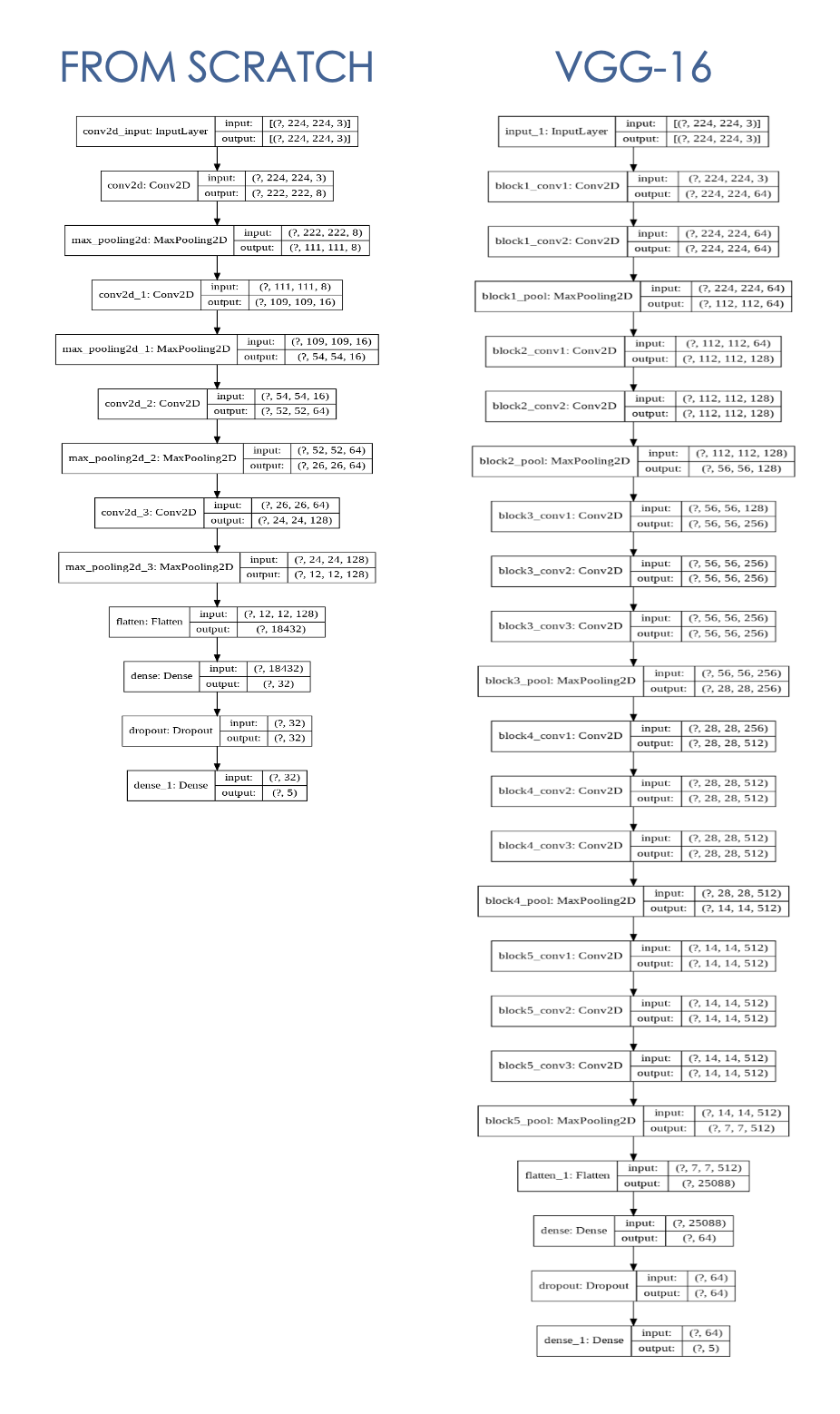
Modèle CNN construit à partir de zéro avec des données d'entraînement limitées de 4000 images (800 images x 5 classes), je construis le modèle avec 4 couches convolutionnelles + max et 2 couches denses (détails ci-dessous).
Le modèle CNN avec apprentissage par transfert me permet d'utiliser une architecture VGG-16 plus complexe, en utilisant des poids pré-formés de VGGFface qui ont été formés sur plus de 2,6 millions d'images.
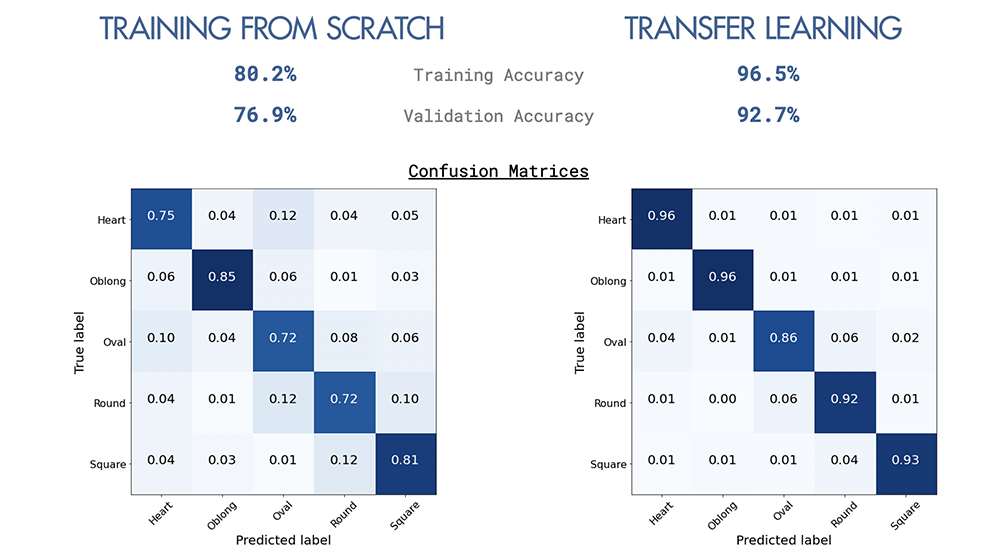
L'apprentissage du transfert a aidé à améliorer considérablement la précision, de 76,9% à 92,7%, à l'aide de poids pré-formés sur un ensemble de données plus important.
À partir des modèles construits à partir de zéro, tous les modèles ont mieux fonctionné que la ligne de base de 20% (5 classes sont équilibrées avec 20% chacune).
Résumé de tous les modèles ci-dessous.

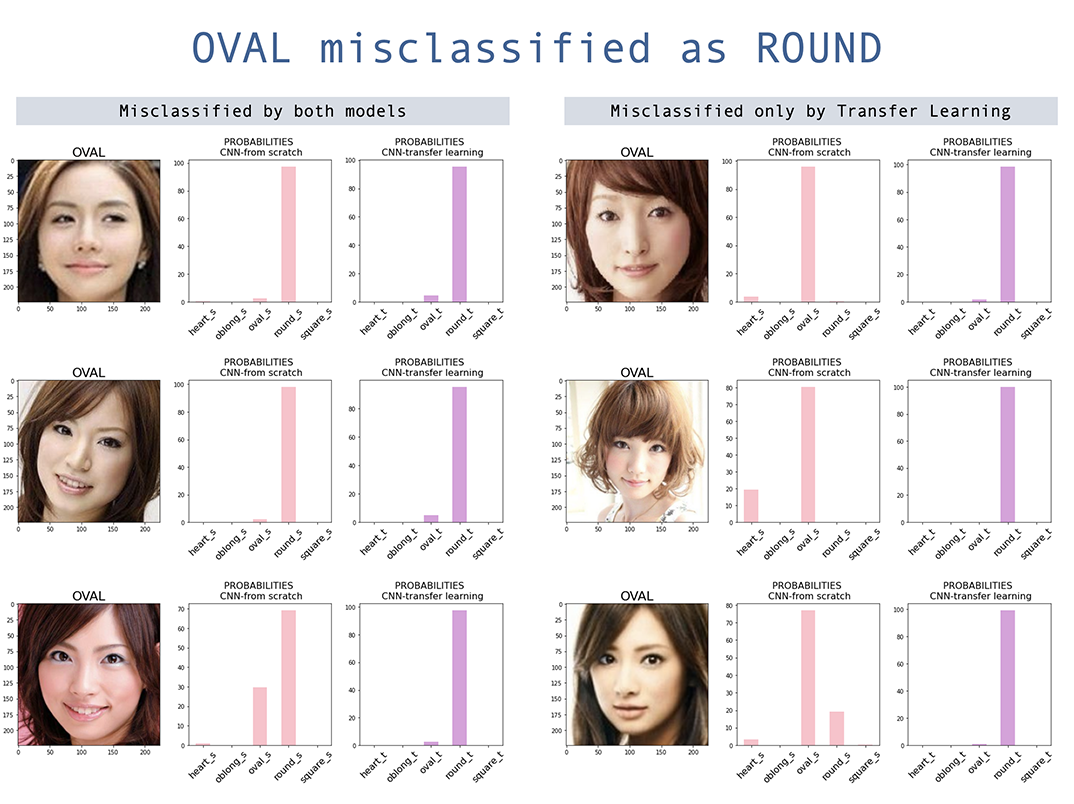
Les deux modèles ont une classification erronée la plus élevée sur la forme du visage ovale . Bien que le modèle d'apprentissage du transfert a amélioré la précision du modèle construit à partir de zéro, l'ovale est toujours le plus mal classé, la majorité étant ovale mal classée comme ronde. Fait intéressant, la face ronde est également principalement mal classée comme ovale, bien que la classification globale pour la forme du visage rond soit faible. La confusion entre ovale et rond est principalement des visages asiatiques, et plus encore avec l'apprentissage du transfert. Cela est probablement dû au fait que les poids pré-entraînés ont moins d'images asiatiques.