Marketing Attribution Models
1.0.10
Classe Python créée pour résoudre les problèmes concernant l'attribution du marketing numérique.
Lors de la navigation en ligne, un utilisateur a plusieurs points de contact avant la conversion, ce qui pourrait conduire à des voyages toujours plus longs et plus complexes.
Comment les conversions dûtes et optmiser les investissements sur les médias?
Pour l'adresser, nous appliquons des modèles d'attribution .
Modèles heuristiques :
Dernière interaction :
Attribution par défaut dans GOGLE Analytics et autres plateformes multimédias telles que Google Ads et Facebook Business Manager;
Seul le dernier point de contact est crédité pour la conversion.
Dernier clic non direct :
Tous les trafics directs sont ignorés et donc 100% du résultat passe au dernier canal par lequel le client est arrivé sur le site Web avant de se convertir.
Première interaction :
Le résultat est entièrement attribué au premier point de contact.
Linéaire :
Chaque point de contact est également crédité.
DÉCHETTE DE TIME :
Plus un point de contact est récent, plus il est de crédit.
Position basée :
Dans ce modèle, 40% du résultat est attribué au dernier point de contact, 40% supplémentaires au premier et les 20% restants sont également répartis entre les canaux à mi-chemin.
Modèles algotithmiques
Valeur de Shapley
Utilisé dans la théorie des jeux, cette valeur est une estimation de la contribution de chaque joueur individuel dans un jeu coopératif.
Les conversions sont créditées sur les canaux par un processus de permutation des voyages. Dans chaque permutation, un canal est distribué pour estimer à quel point il est global.
Par exemple , regardons le voyage hypotherical suivant:
Recherche organique> Facebook> Direct> 19 $ (en tant que revenus)
Pour obtenir la valeur de Shapley de chaque canal, nous devons d'abord prendre en compte toutes les valeurs de conversion pour les permutations des composants de ce voyage donné.
Recherche organique> 7 $
Facebook> 6 $
Direct> 4 $
Recherche organique> Facebook> 15 $
Recherche organique> Direct> 7 $
Facebook> Direct> 9 $
Recherche organique> Facebook> Direct> 19 $
Le nombre de joneys composants augmente de façon exponentielle les canaux les plus distincts que vous avez: le taux est de 2 ^ n (2 à la puissance de n) pour les canaux .
En d'autres termes, avec 3 points de contact distincts, il y a 8 permutations. Avec plus de 15, par exemple, ce processus est impossible .
Par défaut, l'ordre des points de contact n'est pas pris en considération lors du calcul de la valeur de Shapley, seulement de leur présence ou de leur absence. Pour ce faire, le nombre de permutations augmente .
Dans cet esprit, notez qu'il est assez difficile d'utiliser ce modèle lors de l'examen de l'ordre des interactions. Pour les canaux n, non seulement il y a 2 ^ n permutations d'un canal donné I , mais aussi chaque permutation contenant I dans une position différente .
Certains problèmes et limites de la valeur du shapley
Markov chaîne Une chaîne de Markov est un processus stochastique particulier dans lequel la distribution de probabilité de tout état suivant ne dépend que de l'état actuel, sans tenir compte de tout état précédent et de leur séquence.
Dans l'attribution multicanal, nous pouvons utiliser les chaînes Markov pour calculer la probabilité d'interaction entre les paires de canaux multimédias avec la matrice de transition .
En ce qui concerne la contribution de chaque canal dans les conversions, l' effet de suppression est intervenu: pour chaque Jorney, un canal donné est supprimé et une probabilité de conversion est calculée.
La valeur attribuée à un canal est donc obtenue par le rapport de la différence entre la probabilité de conversion en général et la probabilité que ce canal est retirée à nouveau sur la probabilité générale.
En d'autres termes, plus l'effet d'élimination d'un canal est grand, plus leur contribution est grande.
** Lorsque vous travaillez avec les processus markoviens, il n'y a aucune restriction en raison de la quantité ou de l'ordre des canaux. Leur séquence, elle-même, est une partie fondamentale de l'algorithme.
>> pip install marketing_attribution_models from marketing_attribution_models import MAM Lors de la création d'un objet MAM, deux modèles de trame de données peuvent être utilisés comme entrée en fonction de la valeur du paramètre group_channels .
Pour cette démostration, nous utiliserons un cadre de données dans lequel les voyages ne sont pas encore regroupés , chaque ligne comme une session différente et sans ID de voyage unique.
Remarque: La classe MAM a un paramètre intégré pour la création d'ID de voyage, create_journey_id_based_on_conversion , que si vrai , un ID est créé sur la base de l'ID utilisateur, entrée dans le paramètre Group_Channels_ID_LIST , et la colonne indiquant qu'il y a une conversion ou non, dont il Le nom est défini par le paramètre JATTY_WITH_CONV_COLNAME .
Dans ce scénario, toutes les sessions de chaque utilisateur distinct seront commandées et pour chaque conversion, un nouvel ID de voyage est créé. Cependant, nous encourageons fortement que cette création d'identification de voyage soit personnalisée en fonction des connaissances spécifiques à l'entreprise en main et des conclusions exploratoires. Par exemple, si dans une entreprise donnée, il est à noter que la durée moyenne du parcours est d'environ une semaine, un nouveau critique peut être défini de sorte qu'une fois qu'un utilisateur n'a pas d'interaction pendant sept jours, le voyage se casse sous l'hypothèse, il y a eu une perte intéressant.
Quant aux paramètres maintenant, voici comment ils sont configurés pour nos canaux Group_ = True Scénario:
attributions = MAM ( df ,
group_channels = True ,
channels_colname = 'channels' ,
journey_with_conv_colname = 'has_transaction' ,
group_channels_by_id_list = [ 'user_id' ],
group_timestamp_colname = 'visitStartTime' ,
create_journey_id_based_on_conversion = True )Afin d'explorer et de comprendre les capacités de MAM, un "générateur de dataframe aléatoire" a été implémenté via l'utilisation du paramètre Random_DF lorsqu'il est défini sur true .
attributions = MAM ( random_df = True )Une fois l'objet MAM créé, nous pouvons consulter notre base de données maintenant avec l'ajout de notre Journey_id et avec des sessions regroupées en voyages en utilisant l' attriure ".dataframe" .
attributions . DataFrame| Journey_id | canaux_agg | Time_Till_conv_agg | converti_agg | Conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0.0 | Vrai | 1 | |
| 1 | ID: 0_J: 1 | Recherche Google | 0.0 | Vrai | 1 |
| 2 | ID: 0_J: 10 | Recherche Google> Organic> Marketing par e-mail | 72,0> 24,0> 0,0 | Vrai | 1 |
| 3 | ID: 0_J: 11 | Organique | 0.0 | Vrai | 1 |
| 4 | ID: 0_J: 12 | Marketing par e-mail> Facebook | 432,0> 0,0 | Vrai | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direct> Facebook | 120,0> 0,0 | Vrai | 1 |
| 20342 | ID: 9_J: 6 | Recherche Google> Recherche Google> Recherche Google | 48.0> 24,0> 0,0 | Vrai | 1 |
| 20343 | ID: 9_J: 7 | Organic> Organic> Recherche Google> Recherche Google | 480.0> 480.0> 288.0> 0,0 | Vrai | 1 |
| 20344 | ID: 9_J: 8 | Direct> organique | 168,0> 0,0 | Vrai | 1 |
| 20345 | ID: 9_J: 9 | Recherche Google> Organic> Recherche Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0,0 | Vrai | 1 |
Cet attribut est mis à jour pour chaque modèle d'attribution généré. Ce n'est que dans le cas des modèles heuristiques, une nouvelle colonne est annexée contenant la valeur d'attribution donnée par ledit modèle.
Remarque: L'attribut .DataFrame n'interfère avec aucun calcul de modèle. Si elle est modifiée par utilisation, les résultats suivants ne sont pas affectés.
attributions . attribution_last_click ()
attributions . DataFrame| Journey_id | canaux_agg | Time_Till_conv_agg | converti_agg | Conversion_value | |
|---|---|---|---|---|---|
| 0 | ID: 0_J: 0 | 0.0 | Vrai | 1 | |
| 1 | ID: 0_J: 1 | Recherche Google | 0.0 | Vrai | 1 |
| 2 | ID: 0_J: 10 | Recherche Google> Organic> Marketing par e-mail | 72,0> 24,0> 0,0 | Vrai | 1 |
| 3 | ID: 0_J: 11 | Organique | 0.0 | Vrai | 1 |
| 4 | ID: 0_J: 12 | Marketing par e-mail> Facebook | 432,0> 0,0 | Vrai | 1 |
| ... | ... | ... | ... | ... | ... |
| 20341 | ID: 9_J: 5 | Direct> Facebook | 120,0> 0,0 | Vrai | 1 |
| 20342 | ID: 9_J: 6 | Recherche Google> Recherche Google> Recherche Google | 48.0> 24,0> 0,0 | Vrai | 1 |
| 20343 | ID: 9_J: 7 | Organic> Organic> Recherche Google> Recherche Google | 480.0> 480.0> 288.0> 0,0 | Vrai | 1 |
| 20344 | ID: 9_J: 8 | Direct> organique | 168,0> 0,0 | Vrai | 1 |
| 20345 | ID: 9_J: 9 | Recherche Google> Organic> Recherche Google> Emai ... | 528.0> 528.0> 408.0> 240.0> 0,0 | Vrai | 1 |
Habituellement, le volume de données travaillé avec est étendu, il n'est donc pas pratique ou même impossible d'analyser les résultats attribués à chaque voyage avec la transaction. Avec l'attribut groupe_by_channels_models , cependant, tous les résultats peuvent être vus regroupés par canal.
Remarque : Les résultats groupés ne se remplacent pas dans le cas où le même modèle serait utilisé dans deux cas distincts. Les deux (ou même plus) d'entre eux sont indiqués dans " GROUP_BY_CHANNELS_MODELS ".
attributions . group_by_channels_models| canaux | attribution_last_click_heuristic |
|---|---|
| Direct | 2133 |
| E-mail marketing | 1033 |
| 3168 | |
| Affichage Google | 1073 |
| Recherche Google | 4255 |
| 1028 | |
| Organique | 6322 |
| Youtube | 1093 |
Comme pour l'attribut .dataframe , Group_By_Channels_Models est également mis à jour pour chaque modèle utilisé sans la limitation de ne pas afficher les résultats algorithmiques.
attributions . attribution_shapley ()
attributions . group_by_channels_models| canaux | attribution_last_click_heuristic | attribution_shapley_size4_conv_rate_algorithmique | |
|---|---|---|---|
| 0 | Direct | 109 | 74.926849 |
| 1 | E-mail marketing | 54 | 70.558428 |
| 2 | 160 | 160.628945 | |
| 3 | Affichage Google | 65 | 110.649352 |
| 4 | Recherche Google | 193 | 202.179519 |
| 5 | 64 | 72.982433 | |
| 6 | Organique | 315 | 265.768549 |
| 7 | Youtube | 58 | 60.305925 |
Tous les modèles heuristiques se comportent de la même manière lors de l'utilisation des attributs .dataframe et .group_by_channels_models , comme expliqué précédemment, et la sortie de toutes les méthodes du modèle heuristique renvoie un tuple contenant deux séries de pandas .
attribution_first_click = attributions . attribution_first_click ()La première série du tuple est les résultats d'une granularité de voyage , similaire à celle observée dans l'attribut .dataframe
attribution_first_click [ 0 ] 0 [1, 0, 0, 0, 0]
1 [1]
2 [1, 0, 0, 0, 0, 0, 0, 0, 0]
3 [1, 0]
4 [1]
...
20512 [1, 0]
20513 [1, 0, 0]
20514 [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
20515 [1, 0, 0]
20516 [1, 0, 0, 0]
Length: 20517, dtype: object
Le second contient les résultats avec une granularité du canal , comme on le voit dans l'attribut .group_by_channels_models .
attribution_first_click [ 1 ]| canaux | attribution_first_click_heuristic | |
|---|---|---|
| 0 | Direct | 2078 |
| 1 | E-mail marketing | 1095 |
| 2 | 3177 | |
| 3 | Affichage Google | 1066 |
| 4 | Recherche Google | 4259 |
| 5 | 1007 | |
| 6 | Organique | 6361 |
| 7 | Youtube | 1062 |
De tous les modèles présents dans l'objet MAM, seul le dernier clic, d'abord Click et Linear n'ont pas de paramètres personnalisables mais Group_BY_CHANNELS_MODELS , qui a une valeur booléenne qui, lorsqu'elle est définie , ne renvoie pas l'attribution gorupée par les canaux.
Créé pour reproduire l'attribution par défaut de Google Analytics ( dernier clic non direct ) dans lequel le trafic direct est écrasé dans le cas où les interations précédentes ont une source de trafic spécifique autre que directe elle-même dans un temps donné (6 mois par défaut).
S'il n'est pas spécifié, le paramètre BUS_NOT_THIS_CHANNEL est défini sur «Direct» , mais il peut être défini sur tout autre canal d'intérêt pour l'entreprise.
attributions . attribution_last_click_non ( but_not_this_channel = 'Direct' )[ 1 ]| canaux | attribution_last_click_non_direct_heuristic | |
|---|---|---|
| 0 | Direct | 11 |
| 1 | E-mail marketing | 60 |
| 2 | 172 | |
| 3 | Affichage Google | 69 |
| 4 | Recherche Google | 224 |
| 5 | 67 | |
| 6 | Organique | 350 |
| 7 | Youtube | 65 |
Ce modèle a un paramètre list_positions_first_middle_last dans lequel les poids respectifs aux positions des canaux dans chaque voyage peuvent me spécifier en fonction des décisions liées aux entreprises . La distribution par défaut du paramètre est de 40% pour le canal d'introduction , de 40% pour le canal de conversion / dernier et de 20% pour les canaux interminidés .
attributions . attribution_position_based ( list_positions_first_middle_last = [ 0.3 , 0.3 , 0.4 ])[ 1 ]| canaux | Attribution_Position_Based_0.3_0.3_0.4_Heuristic | |
|---|---|---|
| 0 | Direct | 95.685085 |
| 1 | E-mail marketing | 57.617191 |
| 2 | 145.817501 | |
| 3 | Affichage Google | 56.340693 |
| 4 | Recherche Google | 193.282305 |
| 5 | 54.678557 | |
| 6 | Organique | 288.148896 |
| 7 | Youtube | 55.629772 |
Il y a deux paramètres personnalisables: le taux de décroissance , throght le paramètre Decay_over_time * et le temps (en heures) entre chaque décrementure à travers le paramètre de fréquence .
Il convient de noter, cependant, que, dans le cas où il y a plus d'un point de contact entre les intervalles de fréquence, la valeur de conversion sera également répartie entre ces canaux.
Par exemple:
attributions . attribution_time_decay (
decay_over_time = 0.6 ,
frequency = 7 )[ 1 ]| canaux | attribution_time_decay0.6_freq7_heuristic | |
|---|---|---|
| 0 | Direct | 108.679538 |
| 1 | E-mail marketing | 54.425914 |
| 2 | 159.592216 | |
| 3 | Affichage Google | 64.350107 |
| 4 | Recherche Google | 192.838884 |
| 5 | 64.611414 | |
| 6 | Organique | 314.920082 |
| 7 | Youtube | 58.581845 |
Uppon étant appelé, ce modèle renvoie un tuple avec quatre composants. Les deux premiers (indexés 0 et 1) sont comme avec les modèles heuristiques, avec la représentation du .dataframe et .Group_by_channels_models respectivement. Quant aux troisième et quatrième composants (indexés 2 et 3), les résultats sont la matrice de transition et le tableau des effets d'élimination .
Pour commencer, il est possible d'indiquer si les mêmes transitions d'état sont considérées ou non ( par exemple directement à directement).
attribution_markov = attributions . attribution_markov ( transition_to_same_state = False )| canaux | attribution_markov_algorithmic | |
|---|---|---|
| 0 | Direct | 2305.324362 |
| 1 | E-mail marketing | 1237.400774 |
| 2 | 3273.918832 | |
| 3 | Youtube | 1231.183938 |
| 4 | Recherche Google | 4035.260685 |
| 5 | 1205.949095 | |
| 6 | Organique | 5358.270644 |
| 7 | Affichage Google | 1213.691671 |
Cette configuration n'affecte pas les résultats globaux attribués pour chaque canal, mais les valeurs observées dans la matrice de transition . Parce que nous définissons transition_to_same_state en false , la diagonale, indiquant les états qui transitent vers eux-mêmes, est annulée.
ax , fig = plt . subplots ( figsize = ( 15 , 10 ))
sns . heatmap ( attribution_markov [ 2 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )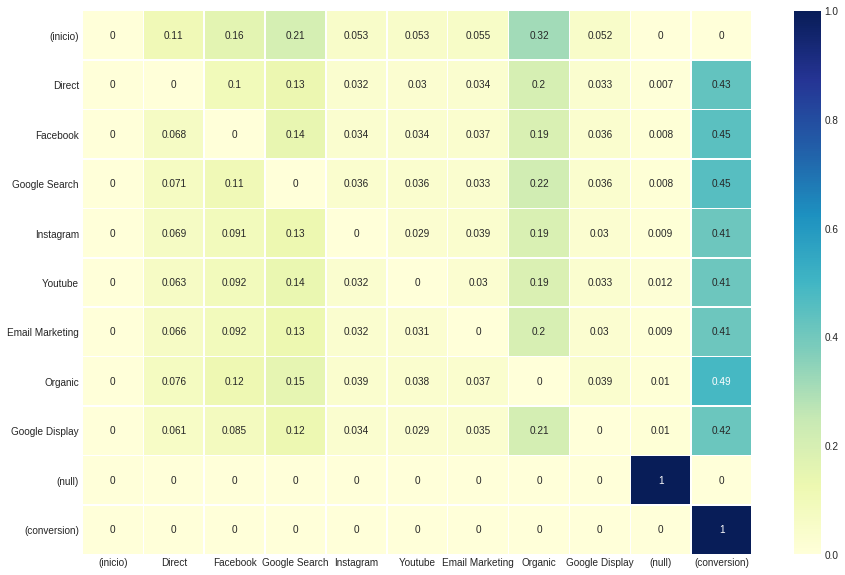
L'effet d'élimination , la quatrième sortie d'attribution_markov , est obtenu par le rapport de la différence entre la probabilité de conversion en général et la probabilité que le canal ce nom est retirée sur la probabilité générale.
ax , fig = plt . subplots ( figsize = ( 2 , 5 ))
sns . heatmap ( attribution_markov [ 3 ]. round ( 3 ), cmap = "YlGnBu" , annot = True , linewidths = .5 )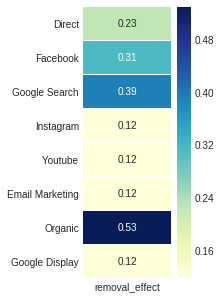
Enfin, le deuxième modèle d'algorithme de MAM dont le concept provient de la théorie des jeux . L'objectif ici est de distribuer la contribution de chaque joueur (dans notre cas, canal) dans un jeu de coopération calculé à l'aide de combinaisons de voyages avec et sans canal donné.
La taille des paramètres définit une limite de la durée d'une chaîne de canaux dans chaque voyage. Par défaut, sa valeur est définie sur 4 , ce qui signifie que seuls les quatre derniers canaux précédant une conversion sont pris en compte.
La méthode de calcul des contributions marginales de chaque canal peut varier avec le paramètre d'ordre . Par défaut, il est défini sur FALSE , ce qui signifie que la contribution est calculée sans tenir compte de l'ordre de chaque canal dans les voyages.
attributions . attribution_shapley ( size = 4 , order = True , values_col = 'conv_rate' )[ 0 ]| combinaisons | conversions | Total_ Sequences | Conversion_value | conv_rate | attribution_shapley_size4_conv_rate_order_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Direct | 909 | 926 | 909 | 0.981641 | [909.0] |
| 1 | Direct> Marketing par e-mail | 27 | 28 | 27 | 0,964286 | [13.948270234099155, 13.051729765900845] |
| 2 | Direct> Marketing par e-mail> Facebook | 5 | 5 | 5 | 1.000000 | [1.6636366232390172, 1.5835883671498818, 1.752 ... |
| 3 | Direct> Marketing par e-mail> Facebook> Google D ... | 1 | 1 | 1 | 1.000000 | [0.2563402919193473, 0,2345560799963515, 0,259 ... |
| 4 | Direct> Marketing par e-mail> Facebook> Google S ... | 1 | 1 | 1 | 1.000000 | [0,2522517802130265, 0,2401286956930936, 0,255 ... |
| ... | ... | ... | ... | ... | ... | ... |
| 1278 | YouTube> Organic> Recherche Google> Google Dis ... | 1 | 2 | 1 | 0,500000 | [0,2514214624662836, 0,24872101523605275, 0,24 ... |
| 1279 | YouTube> Organic> Recherche Google> Instagram | 1 | 1 | 1 | 1.000000 | [0.2544401477637237, 0,2541071889956603, 0,253 ... |
| 1280 | YouTube> Organic> Instagram | 4 | 4 | 4 | 1.000000 | [1.2757196742326997, 1.4712839059493295, 1.252 ... |
| 1281 | YouTube> Organic> Instagram> Facebook | 1 | 1 | 1 | 1.000000 | [0.2357631944623868, 0,2610913781266248, 0,247 ... |
| 1282 | YouTube> Organic> Instagram> Recherche Google | 3 | 3 | 3 | 1.000000 | [0.7223482210689489, 0,7769049003203142, 0,726 ... |
Enfin, le paramètre indiquant quelle métrique est utilisée pour calculer la valeur de Shapley est valeurs_col , qui par défaut est définie sur le taux de conversion . Ce faisant, les voyages sans conversions sont mis en compte.
Il est cependant possible de considérer uniquement les conversions littérales lors de l'utilisation du modèle comme indiqué ci-dessous.
attributions . attribution_shapley ( size = 3 , order = False , values_col = 'conversions' )[ 0 ]| combinaisons | conversions | Total_ Sequences | Conversion_value | conv_rate | attribution_shapley_size3_conversions_algorithmic | |
|---|---|---|---|---|---|---|
| 0 | Direct | 11 | 18 | 18 | 0,611111 | [11.0] |
| 1 | Direct> Marketing par e-mail | 4 | 5 | 5 | 0,800000 | [2.0, 2.0] |
| 2 | Direct> Marketing par e-mail> Recherche Google | 1 | 2 | 2 | 0,500000 | [-3.1666666666666665, -7.666666666666666, 11,8 ... |
| 3 | Direct> Marketing par e-mail> Organic | 4 | 6 | 6 | 0,666667 | [-7.83333333333333, -10.83333333333332, 22,6 ... |
| 4 | Direct> Facebook | 3 | 4 | 4 | 0,750000 | [-8,5, 11,5] |
| ... | ... | ... | ... | ... | ... | ... |
| 75 | Instagram> Organic> YouTube | 46 | 123 | 123 | 0,373984 | [5.833333333333332, 34.33333333333333, 5.83333 ... |
| 76 | Instagram> YouTube | 2 | 4 | 4 | 0,500000 | [2.0, 0,0] |
| 77 | Organique | 64 | 92 | 92 | 0,695652 | [64.0] |
| 78 | Organic> YouTube | 8 | 11 | 11 | 0,727273 | [30.5, -22.5] |
| 79 | Youtube | 11 | 15 | 15 | 0,733333 | [11.0] |
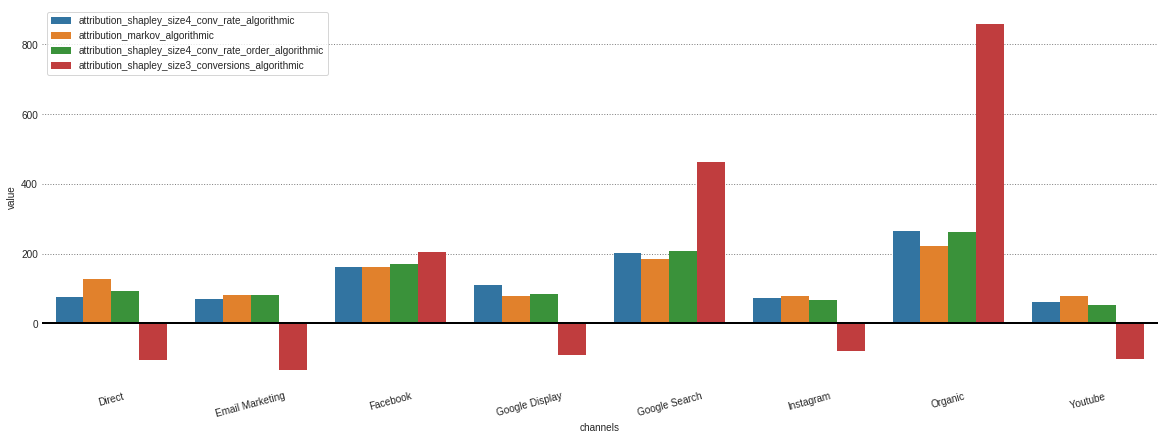
Après avoir obtenu chaque attribution à partir de différents modèles stockés dans notre objet .group_by_channels_models , il est possible de tracer et de comparer les résultats pour les informations
attributions . plot ()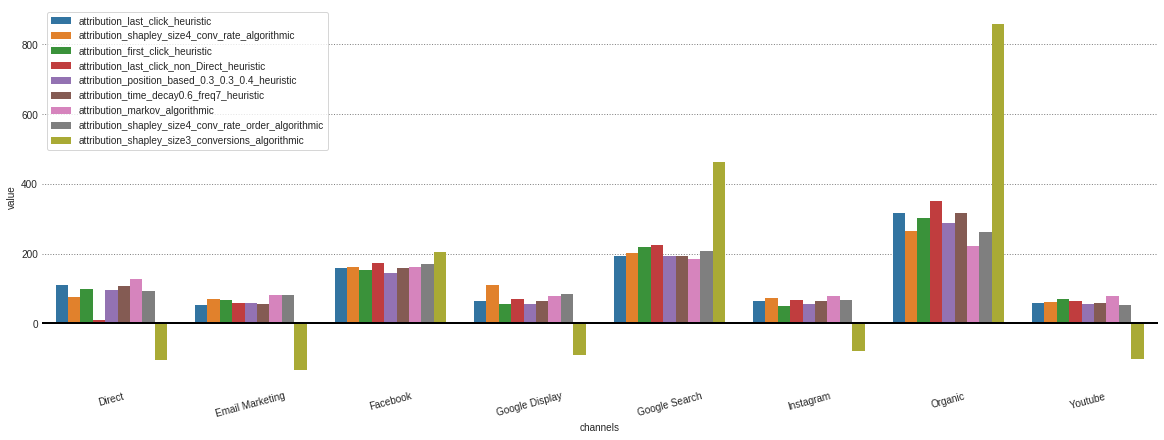
Dans le cas où vous n'êtes intéressé que par les modèles algorithmiques, cela peut moi spécifié dans le paramètre Model_Type .
attributions . plot ( model_type = 'algorithmic' )