awesome RLHF
1.0.0
Il s'agit d'une collection d'articles de recherche pour l'apprentissage du renforcement avec la rétroaction humaine (RLHF). Et le référentiel sera en permanence mis à jour pour suivre la frontière de RLHF.
Bienvenue à suivre et à étoiler!
RLHF génial (RL avec rétroaction humaine)
2024
2023
2022
2021
2020 et avant
Explication détaillée
Table des matières
Aperçu de RLHF
Papiers
Bases de code
Ensemble de données
Blogs
Autre support linguistique
Contributif
Licence
L'idée de RLHF est d'utiliser des méthodes de l'apprentissage du renforcement pour optimiser directement un modèle de langue avec une rétroaction humaine. RLHF a permis aux modèles de langage de commencer à aligner un modèle formé sur un corpus général de données texte à celle des valeurs humaines complexes.
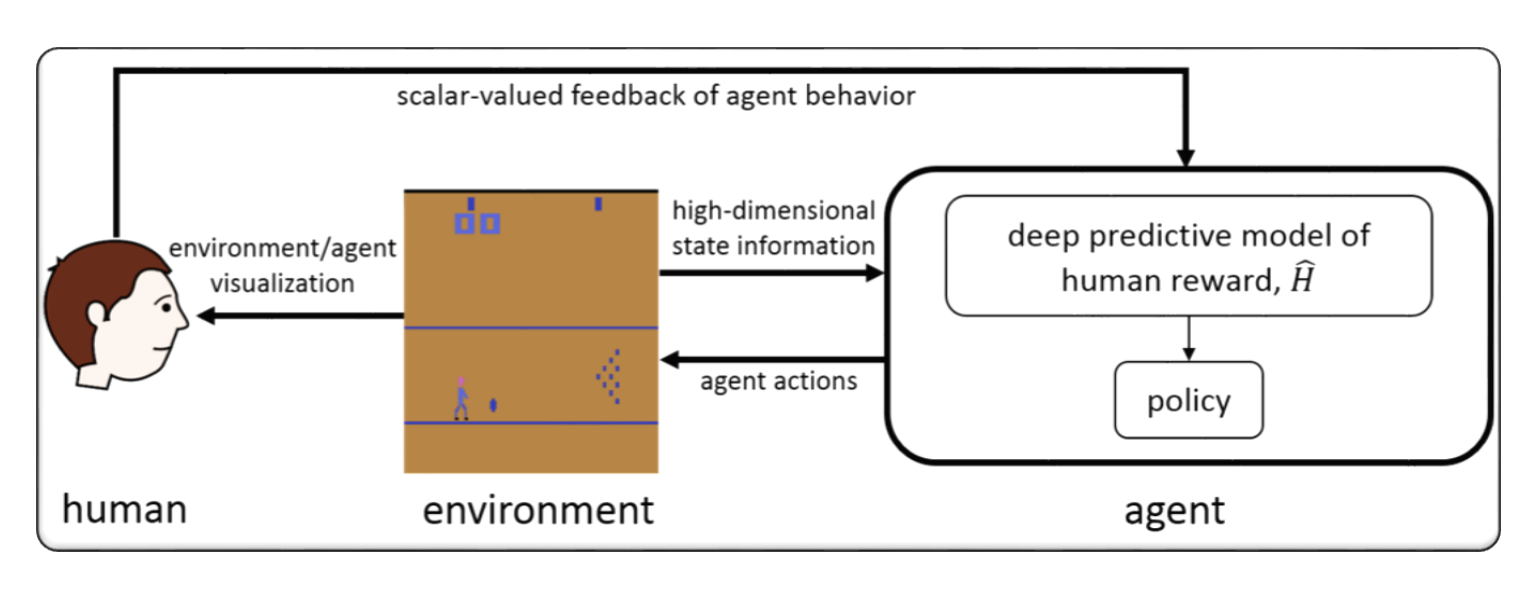
RLHF pour le modèle de grande langue (LLM)
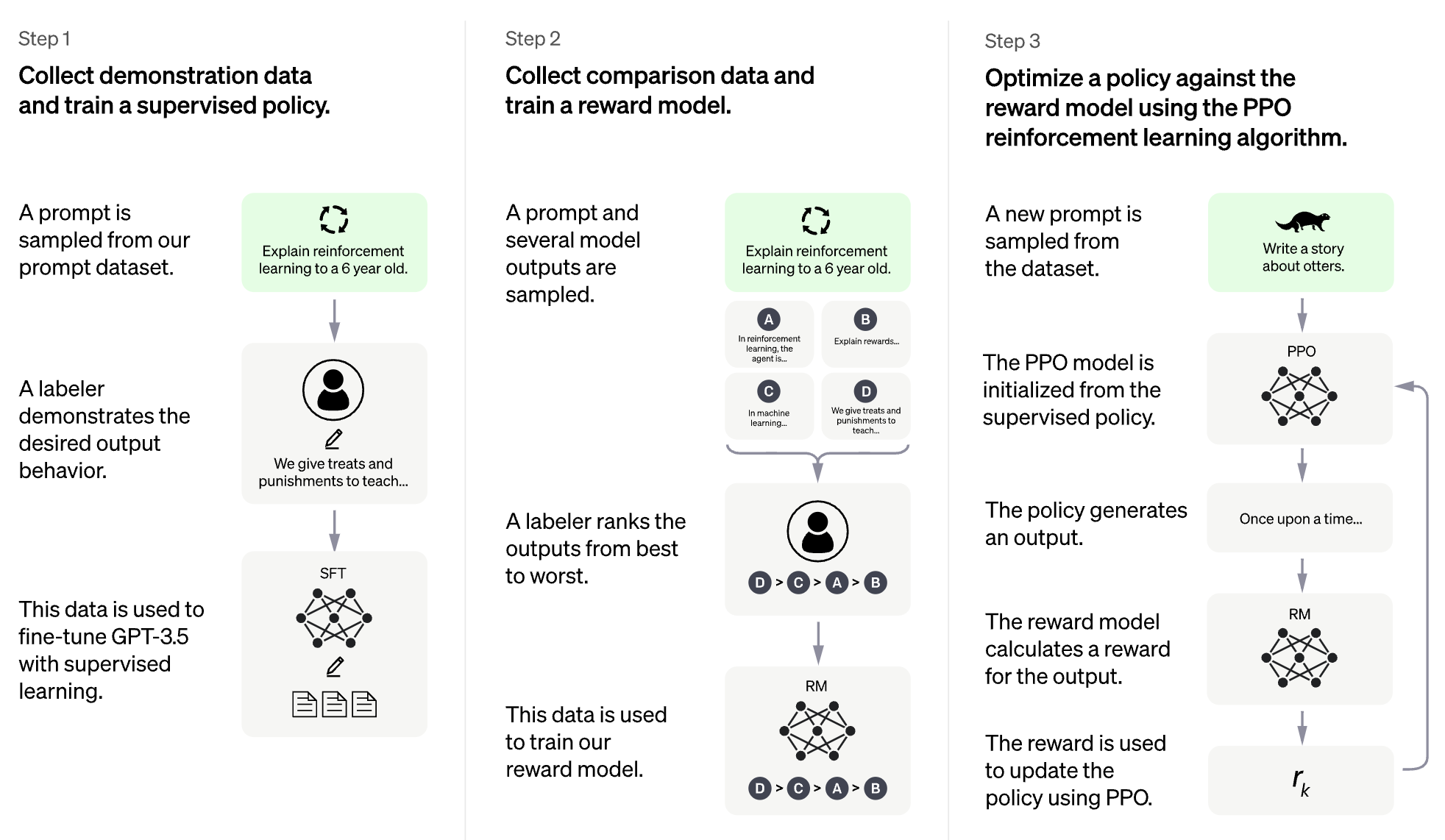
RLHF pour le jeu vidéo (par exemple Atari)
(La section suivante a été générée automatiquement par Chatgpt)
RLHF fait généralement référence à "l'apprentissage du renforcement avec la rétroaction humaine". L'apprentissage par renforcement (RL) est un type d'apprentissage automatique qui implique de former un agent pour prendre des décisions basées sur les commentaires de son environnement. Dans le RLHF, l'agent reçoit également des commentaires des humains sous forme de notes ou d'évaluations de ses actions, ce qui peut l'aider à apprendre plus rapidement et avec précision.
RLHF est un domaine de recherche actif en intelligence artificielle, avec des applications dans des domaines tels que la robotique, les jeux et les systèmes de recommandation personnalisés. Il cherche à relever les défis de la RL dans les scénarios où l'agent a un accès limité aux commentaires de l'environnement et nécessite une contribution humaine pour améliorer ses performances.
L'apprentissage du renforcement avec la rétroaction humaine (RLHF) est un domaine de recherche en développement rapide en intelligence artificielle, et il existe plusieurs techniques avancées qui ont été développées pour améliorer les performances des systèmes RLHF. Voici quelques exemples:
Inverse Reinforcement Learning (IRL) : IRL est une technique qui permet à l'agent d'apprendre une fonction de récompense de la rétroaction humaine, plutôt que de s'appuyer sur des fonctions de récompense prédéfinies. Cela permet à l'agent d'apprendre des signaux de rétroaction plus complexes, tels que des démonstrations du comportement souhaité.
Apprenticeship Learning : l'apprentissage de l'apprentissage est une technique qui combine l'IRL avec l'apprentissage supervisé pour permettre à l'agent d'apprendre à la fois des commentaires humains et des démonstrations d'experts. Cela peut aider l'agent à apprendre plus rapidement et plus efficacement, car il est capable d'apprendre à la fois des commentaires positifs et négatifs.
Interactive Machine Learning (IML) : IML est une technique qui implique une interaction active entre l'agent et l'expert humain, permettant à l'expert de fournir des commentaires sur les actions de l'agent en temps réel. Cela peut aider l'agent à apprendre plus rapidement et efficacement, car il peut recevoir des commentaires sur ses actions à chaque étape du processus d'apprentissage.
Human-in-the-Loop Reinforcement Learning (HITLRL) : HITLRL est une technique qui implique d'intégrer la rétroaction humaine dans le processus RL à plusieurs niveaux, tels que la mise en forme des récompenses, la sélection d'action et l'optimisation des politiques. Cela peut aider à améliorer l'efficacité et l'efficacité du système RLHF en profitant des forces des humains et des machines.
Voici quelques exemples d'apprentissage du renforcement avec la rétroaction humaine (RLHF):
Game Playing : Dans le jeu, les commentaires humains peuvent aider l'agent à apprendre des stratégies et des tactiques qui sont efficaces dans différents scénarios de jeu. Par exemple, dans le jeu populaire de GO, les experts humains peuvent fournir des commentaires à l'agent sur ses mouvements, l'aidant à améliorer son gameplay et sa prise de décision.
Personalized Recommendation Systems : Dans les systèmes de recommandation, les commentaires humains peuvent aider l'agent à apprendre les préférences des utilisateurs individuels, ce qui permet de fournir des recommandations personnalisées. Par exemple, l'agent pourrait utiliser les commentaires des utilisateurs sur les produits recommandés pour savoir quelles fonctionnalités sont les plus importantes pour eux.
Robotics : En robotique, les commentaires humains peuvent aider l'agent à apprendre à interagir avec l'environnement physique de manière sûre et efficace. Par exemple, un robot pourrait apprendre à naviguer plus rapidement dans un nouvel environnement avec les commentaires d'un opérateur humain sur le meilleur chemin à suivre ou quels objets à éviter.
Education : Dans l'éducation, les commentaires humains peuvent aider l'agent à apprendre à enseigner les élèves plus efficacement. Par exemple, un tuteur basé sur l'IA pourrait utiliser les commentaires des enseignants sur lesquels les stratégies d'enseignement fonctionnent mieux avec différents étudiants, aidant à personnaliser l'expérience d'apprentissage.
format: - [title](paper link) [links] - author1, author2, and author3... - publisher - keyword - code - experiment environments and datasets
Hybridflow: un cadre RLHF flexible et efficace
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Mots-clés: cadre flexible, efficace, RLHF
Code: officiel
Alarme: Aligner les modèles de langue via la modélisation des récompenses hiérarchiques
Yuhang Lai, Siyuan Wang, Shujun Liu, Xuanjing Huang, Zhongyu Wei
Mots-clés: récompense hiérarchique, tâches de génération de texte ouvertes
Code: officiel
TLCR: Récompense continue au niveau des jetons pour l'apprentissage du renforcement à grains fins de la rétroaction humaine
Eunseop Yoon, Hee Suk Yoon, Soohwan Eom, Gunsoo Han, Daniel Wintae Nam, Daejin Jo, Kyoung-Woon On, Mark A. Hasegawa-Johnson, Sungwoong Kim, Chang D. Yoo
Mots-clés: récompense continue au niveau du jeton, RLHF
Code: officiel
Alignement de grands modèles multimodaux avec RLHF augmenté factuel
Zhiqing Sun, Sheng Shen, Shengcao Cao, Haotian Liu, Chunyuan Li, Yikang Shen, Chuang Gan, Liang-Yan Gui, Yu-Xiong Wang, Yiming Yang, Kurt Keutzer, Trevor Darrell
Mots-clés: RLHF augmenté factuel, vision et langue, ensemble de données de préférence humaine
Code: officiel
Direct de l'alignement du modèle de langage à travers une distillation rapide contrastive auto-récompense
Aiwei Liu, Haoping Bai, Zhiyun Lu, Xiang Kong, Simon Wang, Jiulong Shan, Meng Cao, Lijie Wen
Mots-clés: sans données de préférence humaine, auto-récompense, DPO
Code: officiel
Contrôle arithmétique des LLM pour diverses préférences des utilisateurs: Alignement des préférences directionnelles sur les récompenses multi-objectifs
Haoxiang Wang, Yong Lin, Wei Xiong, Rui Yang, Shizhe Dioo, Shuang Qiu, Han Zhao, Tong Zhang
Mots-clés: préférence des utilisateurs, modèle de récompense multi-objectif, échantillonnage de rejet Finetuning
Code: officiel
Retour à l'essentiel: Revisiter Renforce Style Optimization pour l'apprentissage de la rétroaction humaine dans les LLM
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadadee, Julia Kreutzer, Olivier Pietquin, Ahmet üstün, Sara Hooker
Mots-clés: optimisation RL en ligne, faible coût de calcul
Code: officiel
Amélioration des modèles de gros langues via l'apprentissage du renforcement à grains fins avec une contrainte d'édition minimale
Zhipng Chen, Kun Zhou, Wayne Xin Zhao, Junchen Wan, Fuzheng Zhang, Di Zhang, Ji-Rong Wen
Mot de clé: récompense au niveau des jetons, LLM
Code: officiel
RLAIF contre RLHF: mise à l'échelle d'apprentissage du renforcement de la rétroaction humaine avec la rétroaction de l'IA
Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Ren Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, Sushant Prakash
Mots-clés: RL de la rétroaction de l'IA
Code: officiel
Méthodes fondées sur des sanctions en principe pour l'apprentissage du renforcement du Bilevel et RLHF
Han Shen, Zhuoran Yang, Tianyi Chen
Mots-clés: optimisation de Bilevel
Code: officiel
Récompense dense gratuitement dans l'apprentissage du renforcement des commentaires humains
Alex James Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Mots-clés: Forme de récompense, RLHF
Code: officiel
Une approche minilaximaliste pour le renforcement de l'apprentissage de la rétroaction humaine
Gokul Swamy, Christoph Dann, Rahul Kidambi, Steven Wu, Alekh Agarwal
Mot de clé: gagnant de Minimax, optimisation des préférences auto-play
Code: officiel
RLHF-V: Vers des MLLMs dignes de confiance via l'alignement du comportement à partir de commentaires humains correctionnels à grain fin
Tianyu Yu, Yuan Yao, Haoye Zhang, Taiwen He, Yifeng Han, Ganqu Cui, Jinyi Hu, Zhiyuan Liu, Hai-Tao Zheng, Maosong Sun, Tat-Seng Chua
Mots-clés: modèles multimodaux de grande langue, problème d'hallucination, apprentissage du renforcement de la rétroaction humaine
Code: officiel
RLHF Workflow: de la modélisation des récompenses à RLHF en ligne
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
Mots-clés: RLHF itératif en ligne, modélisation des préférences, modèles de grande langue
Code: officiel
Maxmin-RLHF: Vers l'alignement équitable des modèles de grande langue avec diverses préférences humaines
Souradip Chakraborty, Jiahao Qiu, Hui Yuan, Alec Koppel, Furong Huang, Dinesh Manocha, Amrit Singh Bedi, Mengdi Wang
Mots-clés: Mélange de distributions de préférences, objectif d'alignement maxmin
Code: officiel
Réinitialisation de l'ensemble de données Optimisation de la politique pour RLHF
Jonathan D. Chang, Wenhao Zhan, Owen Oertell, Kianti Brantley, Dipendra Misra, Jason D. Lee, Wen Sun
Mots-clés: réinitialisation de l'ensemble de données Optimisation de la stratégie
Code: officiel
Une vue de récompense dense sur l'alignement de la diffusion du texte à l'image avec la préférence
Shentao Yang, Tianqi Chen, Mingyuan Zhou
Mots-clés: RLHF pour la génération de texte à l'image, amélioration de la récompense dense du DPO, alignement efficace
Code: officiel
Le réglage fin de l'auto-play convertit les modèles de langage faibles en modèles de langue forts
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, Quanquan Gu
MOT-CLÉ: Auto-play ajusté
Code: officiel
RLHF a déchiffré: une analyse critique de l'apprentissage du renforcement de la rétroaction humaine pour les LLM
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
Mots-clés: RLHF, récompense oraculaire, analyse du modèle de récompense, enquête
Confronter une suroptimisation de récompense pour les modèles de diffusion: une perspective de biais inductifs et de primauté
Ziyi Zhang, Sen Zhang, Yibing Zhan, Yong Luo, Yonggang Wen, Dacheng Tao
Mots-clés: modèles de diffusion, alignement, apprentissage du renforcement, RLHF, suraltation de récompense, biais de primauté
Code: officiel
Sur les préférences diversifiées de l'alignement du modèle de grande langue
Dun Zeng, Yong Dai, Pengyu Cheng, Tianhao Hu, Wanshun Chen, Nan DU, Zenglin Xu
Mots-clés: alignement les préférences partagées, récompenses Metrics de modélisation, LLM
Code: officiel
Aligner la rétroaction de la foule via la modélisation de récompense de préférence distributionnelle
Dexun Li, Cong Zhang, Kuicai Dong, Derrick Goh Xin Deik, Ruiming Tang, Yong Liu
Mot-clé: RLHF, distribution de préférence, alignement, LLM
Au-delà de l'alignement des ajustements à une seule fois: optimisation de préférence directe multi-objectifs
Zhanhui Zhou, Jie Liu, Chao Yang, Jing Shao, Yu Liu, Xiangyu Yue, Wanli Ouyang, Yu Qiao
Mot-clé: RLHF multi-objectif sans modélisation de récompense, DPO
Code: officiel
Désalignement émulé: l'alignement de sécurité pour les modèles de grands langues peut se retourner contre vous!
Zhanhui Zhou, Jie Liu, Zhichen Dong, Jiaheng Liu, Chao Yang, Wanli Oulang, Yu Qiao
Mots-clés: LLM Attaque en temps de déférence, DPO, produisant des LLMs nocifs sans s'entraîner
Code: officiel
Une analyse théorique de l'apprentissage de la NASH de la rétroaction humaine sous la préférence générale de KL
Chenlu Ye, Wei Xiong, Yuheng Zhang, Nan Jiang, Tong Zhang
Mots-clés: RLHF basé sur le jeu, Nash Learning, alignement sous Oracle sans récompense-modèle
Atténuer la taxe d'alignement de RLHF
Yong Lin, Hangyu Lin, Wei Xiong, Shizhe Dioo, Jianmenng Liu, Jipeng Zhang, Rui Pan, Haoxiang Wang, Wenbin Hu, Hanning Zhang, Hanze Dong, Renjie PI, Han Zhao, Nan Jiang, Heng Ji, Yuan Yao, Tong Zhang
Mots-clés: RLHF, taxe d'alignement, oublie catastrophique
Formation de modèles de diffusion avec apprentissage de renforcement
Kevin Black, Michael Janner, Yilun DU, Ilya Kostrikov, Sergey Levine
Mots-clés: apprentissage du renforcement, RLHF, modèles de diffusion
Code: officiel
AlignDiff: Aligner diverses préférences humaines via un modèle de diffusion personnalisé pour comportement
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao MU, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhiceng Hu
Mots-clés: apprentissage du renforcement; Modèles de diffusion; Rlhf; Alignement des préférences
Code: officiel
Récompense dense gratuitement dans l'apprentissage du renforcement des commentaires humains
Alex J. Chan, Hao Sun, Samuel Holt, Mihaela van der Schaar
Mot-clé: RLHF
Code: officiel
Transformer et combiner des récompenses pour l'alignement de grands modèles de langue
Zihao Wang, Chirag Nagpal, Jonathan Berant, Jacob Eisenstein, Alex d'Amour, Sanmi Koyejo, Victor Veitch
Mots-clés: RLHF, Aligning, LLM
Paramètre Renfort efficace Apprentissage de la rétroaction humaine
Hakim Sidahmed, Samrat Phatale, Alex Hutcheson, Zhuonan Lin, Zhang Chen, Zac Yu, Jarvis Jin, Simral Chaudhary, Roman Komarytsia, Christianne Ahlheim, Yonghao Zhu, Bowen Li, Saravanan Gansh, Bill Byrne, Jessica Hoffmann, Hassan Mansan, Wai li Li, , Abhinav Rastogi, Lucas Dixon
Mots-clés: RLHF, méthode efficace des paramètres, faible coût de calcul, LLM, VLM
Améliorer l'apprentissage du renforcement de la rétroaction humaine avec un ensemble de modèles de récompense efficace
Shun Zhang, Zhenfang Chen, Sunli Chen, Yikang Shen, Zhiqing Sun, Chuang Gan
Mots-clés: RLHF, ensemble de récompense, méthode d'ensemble efficace
Un paradigme théorique général pour comprendre l'apprentissage des préférences humaines
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, Rémi Munos
Mots-clés: RLHF, préférence par paire
Les commentaires humains à grains fins donnent de meilleures récompenses pour la formation du modèle de langue
Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, Hannaneh Hajishirzi
Mot-clé: RLHF, récompense au niveau de la phrase, LLM
Code: officiel
Guide de niveau de jeton au niveau des préférences pour le modèle du modèle de langue
Shentao Yang, Shujian Zhang, Congying Xia, Yihao Feng, Caiming Xiong, Mingyuan Zhou
Mots-clés: RLHF, guidage de formation au niveau des jetons, cadre de formation alternatif / en ligne, objectifs de formation minimaliste
Code: officiel
Récompenses fantastiques et comment les apprivoiser: une étude de cas sur l'apprentissage des récompenses pour les systèmes de dialogue axés sur les tâches
Yihao Feng *, Shentao Yang *, Shujian Zhang, Jianguo Zhang, Caiming Xiong, Mingyuan Zhou, Huan Wang
Mots-clés: RLHF, apprentissage de fonction de récompense génralisée, utilisation de la fonction de récompense, système de dialogue axé sur les tâches, apprentissage
Code: officiel
Apprentissage des préférences inverses: RL basé sur les préférences sans fonction de récompense
Joey Hejna, Dorsa sadigh
Mot-clé: apprentissage des préférences inverses, sans modèle de récompense
Code: officiel
Alpacafarm: un cadre de simulation pour les méthodes qui apprennent de la rétroaction humaine
Yann Dubois, Chen Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy BA, Carlos Guestrin, Percy S. Liang, Tatsunori B. Hashimoto
Mot-clé: RLHF, cadre de simulation
Code: officiel
Optimisation de classement des préférences pour l'alignement humain
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li, Houfeng Wang
Mots-clés: optimisation de classement des préférences
Code: officiel
Optimisation des préférences adversaires
Pengyu Cheng, Yifan Yang, Jian Li, Yong Dai, Nan du
Mots-clés: RLHF, GAN, jeux adversaires
Code: officiel
Préférence itérative Apprentissage de la rétroaction humaine: pontage de la théorie et de la pratique du RLHF sous la contrainte KL
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
Mots-clés: RLHF, DPO itératif, fondation mathématique
Exemple d'apprentissage efficace de renforcement de la rétroaction humaine via une exploration active
Viraj Mehta, Vikramjeet Das, Ojash Neopane, Yijia Dai, Ilija Bogunovic, Jeff Schneider, Willie Neiswanger
Mot-clé: RLHF, échantillon d'efficacité, exploration
Renforcement d'apprentissage de la rétroaction statistique: le parcours du test AB aux tests de fourmi
Feiyang Han, Yimin Wei, Zhaofeng Liu, Yanxing Qi
Mots-clés: RLHF, AB Test, RLSF
Une analyse de référence de la capacité des modèles de récompense à analyser avec précision les modèles de fondation sous le changement de distribution
Ben Pikus, Will Levine, Tony Chen, Sean Hendryx
Mot-clé: RLHF, OOD, Shift de distribution
Alignement efficace des données de grands modèles de langue avec la rétroaction humaine à travers le langage naturel
Di Jin, Shikib Mehri, Devamanyu Hazarika, Aishwarya Padmakumar, Sungjin Lee, Yang Liu, Mahdi Namazifar
Mot-clé: RLHF, économe en données, alignement
Renforcer étape par étape
Sarah Pan, Vladislav Lialin, Sherin Muckatira, Anna Rumshisky
Mot-clé: RLHF, raisonnement
Optimisation de politique directe basée sur les préférences sans modélisation de récompense
Gaon AN, Junhyeok Lee, Xingdong Zuo, Norio Kosaka, Kyung-min Kim, Hyun Oh Song
Mots-clés: RLHF sans modélisation de récompense, apprentissage contrastif, apprentissage de raffinement hors ligne
AlignDiff: Aligner diverses préférences humaines via un modèle de diffusion personnalisé pour comportement
Zibin Dong, Yifu Yuan, Jianye Hao, Fei Ni, Yao MU, Yan Zheng, Yujing Hu, Tangjie LV, Changjie Fan, Zhiceng Hu
Mot-clé: RLHF, alignement, modèle de diffusion
Eureka: conception de récompense au niveau de l'homme via le codage de modèles de grande langue
Yecheng Jason MA, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, fan de Linxi, Anima Anandkumar
Mot-clé: conception de fonctions de récompense basée sur LLM
SAFE RLHF: Apprentissage de renforcement sûr de la rétroaction humaine
Josef Dai, Xuehai Pan, Ruiyang Sun, Jiaming Ji, Xinbo Xu, Mickel Liu, Yizhou Wang, Yaodong Yang
Mots-clés: Sale RL, LLM Fine-Tture
Diversité de qualité grâce à des commentaires humains
Li ding, Jenny Zhang, Jeff Clune, Lee Spector, Joel Lehman
Mots-clés: diversité de qualité, modèle de diffusion
Remax: une méthode d'apprentissage en renforcement simple, efficace et efficace pour aligner les modèles de langue importants
Ziniu Li, Tian Xu, Yushun Zhang, Yang Yu, Ruoyu Sun, Zhi-Quan Luo
Mots-clés: efficacité informatique, technique de réduction de la variance
Réglage des modèles de vision informatique avec récompenses de tâche
André Susano Pinto, Alexander Kolesnikov, Yuge Shi, Lucas Beyer, Xiaohua Zhai
Mots-clés: réglage de la récompense dans la vision de l'ordinateur
La sagesse du recul fait des modèles de langue de meilleurs adeptes de l'instruction
Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, Joseph E. Gonzalez
Mots-clés: Recapais du coup d'instruction, système RLHF, aucun réseau de valeur requis
Code: officiel
Langue a instruit l'apprentissage du renforcement pour la coordination humaine-AI
Hengyuan HU, Dorsa sadigh
Mots-clés: coordination humaine-ai, alignement des préférences humaines, RL conditionné à l'instruction
Alignement des modèles de langue avec l'apprentissage du renforcement hors ligne de la rétroaction humaine
Jian Hu, Li Tao, June Yang, Chandler Zhou
Mots-clés: alignement basé sur le transformateur de décision, apprentissage en renforcement hors ligne, système RLHF
Optimisation de classement des préférences pour l'alignement humain
Feifan Song, Bowen Yu, Minghao Li, Haiyang Yu, Fei Huang, Yongbin Li et Houfeng Wang
Mots-clés: alignement des préférences humaines supervisées, extension de classement des préférences
Code: officiel
Combler l'écart: une enquête sur l'intégration des commentaires (humains) pour la génération du langage naturel
Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José GC de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, André Ft Martins
Mots-clés: génération de langage naturel, intégration des commentaires humains, formalisation de rétroaction et taxonomie, rétroaction et jugements basés sur l'IA
Rapport technique GPT-4
Openai
Mots-clés: un modèle multimodal à grande échelle, modèle basé sur le transformateur, RLHF utilisé
Code: officiel
Ensemble de données: Drop, Winogrande, Hellaswag, Arc, Humaneval, GSM8K, MMLU, VOROINGQA
Radeau: récompense Finetuning classée pour l'alignement du modèle de fondation génératif
Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Dioo, Jipeng Zhang, Kashun Shum, Tong Zhang
Mots-clés: Finetuning d'échantillonnage de rejet, alternative au PPO, modèle de diffusion
Code: officiel
RRHF: classez les réponses à aligner les modèles de langue avec la rétroaction humaine sans larmes
Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, Fei Huang
Mot-clé: nouveau paradigme pour RLHF
Code: officiel
Apprentissage des préférences à quelques coups pour la RL humaine dans la boucle
Joey Hejna, Dorsa sadigh
MOT-CLÉ: Apprentissage des préférences, apprentissage interactif, apprentissage multi-tâches, élargissant le pool de données disponibles en visualisant un RL humain dans la boucle
Code: officiel
Meilleur alignement des modèles de texte à l'image avec les préférences humaines
Xiaoshi Wu, Keqiang Sun, Feng Zhu, Rui Zhao, Hongsheng Li
Mot-clé: modèle de diffusion, texte à l'image, esthétique
Code: officiel
ImageReward: Apprendre et évaluer les préférences humaines pour la génération de texte à l'image
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, Yuxiao Dong
MOT-CLÉ: Préférence humaine à l'image à usage général RM, évaluation des modèles génératifs de texte à image
Code: officiel
Ensemble de données: Coco, diffusiondb
Alignement des modèles de texte à l'image en utilisant la rétroaction humaine
Kimin Lee, Hao Liu, Moonkyung Ryu, Olivia Watkins, Yuqing du, Craig Boutilier, Pieter Abbeel, Mohammad Ghavamzadeh, Shixiang Shane Gu
Mot-clé: modèle de texte à l'image, stable, fonction de récompense qui prédit la rétroaction humaine
Visual Chatgpt: parler, dessiner et éditer avec des modèles de fondation visuelle
Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan
Mots-clés: modèles de fondation visuelle, chat visuel
Code: officiel
Modèles de langue pré-entraînement avec préférences humaines (PHF)
Tomasz Korbak, Kejian Shi, Angelica Chen, Rasika Bhalerao, Christopher L. Buckley, Jason Phang, Samuel R. Bowman, Ethan Perez
Mots-clés: pré-entraînement, RL hors ligne, transformateur de décision
Code: officiel
Alignez les modèles de langue avec les préférences grâce à la minimisation F-Divergence (F-DPG)
Dongyoung GO, Tomasz Korbak, Germán Kruszewski, Jos Rozen, Nahyeon Ryu, Marc Dymetman
Mot-clé: F-Divergence, RL avec pénalités KL
Apprentissage de renforcement de principe avec les commentaires humains des comparaisons par paire ou k-sise
BANGUA ZHU, JIANTAO JIAO, Michael I. Jordan
Mot-clé: Mle pessimiste, IRL max-entropie
La capacité d'auto-correction morale dans les modèles de grande langue
Anthropique
Mots-clés: améliorer la capacité d'auto-correction morale en augmentant la formation RLHF
Ensemble de données; Barbecue
L'apprentissage du renforcement est-il (pas) pour le traitement du langage naturel ?: Benchmarks, lignes de base et blocs de construction pour l'optimisation des politiques de langage naturel (NLPO)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianti, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Mots-clés: Optimisation des générateurs de langues avec RL, référence, algorithme RL performant
Code: officiel
Ensemble de données: IMDB, communen, CNN Daily Mail, Totto, WMT-16 (EN-DE), NarrativeQA, DailyDialog
Échelle des lois pour la suroptimisation du modèle de récompense
Leo Gao, John Schulman, Jacob Hilton
Mot de clé: modèle de récompense de récompense d'or modèle de récompense proxy, taille de l'ensemble de données, taille des paramètres de la politique, bon, PPO
Amélioration de l'alignement des agents de dialogue via des jugements humains ciblés (Sparrow)
Amelia Glaese, Nat McAleese, Maja Trębacz, et al.
Mot de clé: agent de dialogue de recherche d'informations, décompose le bon dialogue en règles de langage naturel, DPC, interagir avec le modèle pour susciter la violation d'une règle spécifique (sondage adversaire)
Ensemble de données: Questions naturelles, ELI5, Quality, Triviaqa, Winobias, BBQ
Modèles de langue en équipe rouge pour réduire les dommages: méthodes, comportements d'échelle et leçons apprises
Deep Ganguli, Liane Lovitt, Jackson Kernion, et al.
MOT-CLÉ: Modèle de langue d'équipe rouge, étudiez les comportements de mise à l'échelle, lisez un ensemble de données d'équipe
Code: officiel
Planification dynamique dans le dialogue ouvert à l'aide d'apprentissage du renforcement
Deborah Cohen, Moonkyung Ryu, Yinlam Chow, Orgad Keller, Ido Greenberg, Avinatan Hassidim, Michael Fink, Yossi Matias, Idan Szpektor, Craig Boutilier, Gal Elidan
Mot de clé: système de dialogue en temps réel et ouvert, associe l'intégration succincte de l'état de conversation par les modèles de langue, CAQL, CQL, Bert
Quark: génération de texte contrôlable avec désapprentissage renforcé
Ximing Lu, Sean Wheleck, Jack Hessel, Liwei Jiang, Lianhui Qin, Peter West, Prithviraj Ammanabrolu, Yejin Choi
Mot-clé: réglage fin du modèle linguistique sur les signaux de ce qu'il faut ne pas faire, le transformateur de décision, le réglage LLM avec PPO
Code: officiel
Ensemble de données: WritingPrompts, SST-2, Wikitext-103
Former un assistant utile et inoffensif avec apprentissage du renforcement des commentaires humains
Yuntao Bai, Andy Jones, Kamal Ndousse, et al.
Mots-clés: assistants inoffensifs, mode en ligne, robustesse de la formation RLHF, détection OOD.
Code: officiel
Ensemble de données: Triviaqa, Hellaswag, Arc, OpenBookQa, Lambada, Humaneval, MMLU, Véritude
Enseigner des modèles de langue pour soutenir les réponses avec des citations vérifiées (gophercite)
Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, Nat McAleeseese
Mot-clé: générez des réponses qui citant des preuves spécifiques, abstenez-vous de répondre à l'insuffisance
Ensemble de données: Questions naturelles, ELI5, Quality, Troilfulqa
Modèles de langue de formation pour suivre les instructions avec les commentaires humains (instructGpt)
Long Oulang, Jeff Wu, Xu Jiang, et al.
Mots-clés: modèle grand langage, alignement le modèle de langue avec l'intention humaine
Code: officiel
Ensemble de données: véritableqa, RealToxicityPrompts
IA constitutionnelle: insigne de la rétroaction de l'IAI
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, et al.
MOT-CLÉ: RL de la rétroaction de l'IA (RLAIF), formant un assistant AI inoffensif à travers l'autodiffusion, le style de la chaîne de pensées, le comportement de contrôle de l'IA plus précisément
Code: officiel
Découvrir les comportements du modèle linguistique avec des évaluations écrites par modèle
Ethan Perez, Sam Ringer, Kamilė Lukošiūtė, Karina Nguyen, Edwin Chen, et al.
Mot de clé: générer automatiquement des évaluations avec LMS, plus de RLHF aggrave le LMS, les évaluations rédigées par LM sont de haute qualité
Code: officiel
Ensemble de données: barbecue, schémas winogender
Modélisation de récompense non markovienne à partir d'étiquettes de trajectoire via un apprentissage d'instance interprétable
Joseph Early, Tom Bewley, Christine Evers, Sarvapali Ramchurn
Mots-clés: Modélisation des récompenses (RLHF), non-markovien, apprentissage par instance multiple, interprétabilité
Code: officiel
Webgpt: Assaillant de questions assisté par le navigateur avec commentaires humains (webgpt)
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, et al.
Mots-clés: Rechercher le modèle sur le Web et fournir une référence , Apprentissage d'imitation , BC, Question longue forme
Ensemble de données: Eli5, Triviaqa, véritableqa
Résumer récursivement des livres avec des commentaires humains
Jeff Wu, Long Oulang, Daniel M. Ziegler, Nisan Stiennon, Ryan Lowe, Jan Leike, Paul Christiano
Mots-clés: modèle formé sur une petite tâche pour aider l'homme à évaluer la tâche plus large, Colombie-Britannique
Ensemble de données: Booksum, narrativeqa
Revisiter les faiblesses de l'apprentissage du renforcement pour la traduction des machines neuronales
Samuel Kiegeland, Julia Kreutzer
Mots-clés: le succès du gradient de politique est dû à la récompense plutôt qu'à la forme de la distribution de sortie, de la traduction automatique, du NMT, de l'adaption du domaine
Code: officiel
Ensemble de données: WMT15, IWSLT14
Apprendre à résumer à partir des commentaires humains
Nisan Stiennon, Long Oulang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, Paul Christiano
Mots-clés: se soucier de la qualité du résumé, la perte de formation affecte le comportement du modèle, le modèle de récompense se généralise aux nouveaux ensembles de données
Code: officiel
Ensemble de données: TL; DR, CNN / DM
Modèles de langage affinés des préférences humaines
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
MOT-CLÉ: récompense l'apprentissage pour la langue, le texte continu avec un sentiment positif, tâche récapitulative, descriptif physique
Code: officiel
Ensemble de données: TL; DR, CNN / DM
Alignement de l'agent évolutif via la modélisation des récompenses: une direction de recherche
Jan Leike, David Krueger, Tom Everitt, Miljan Martic, Vishal Maini, Shane Legg
Mot de clé: Problème d'alignement de l'agent, apprenez la récompense de l'interaction, optimisez la récompense avec RL, modélisation de récompense récursive
Code: officiel
Env: Atari
Récompenser l'apprentissage des préférences humaines et des démonstrations à Atari
Borja Ibarz, Jan Leike, Tobias Pohlen, Geoffrey Irving, Shane Legg, Dario Amodei
MOT-CLÉ: Préférences de trajectoire de démonstration d'experts Problème de piratage de récompense, bruit dans l'étiquette humaine
Code: officiel
Env: Atari
Tamer profond: Façon d'agent interactif dans les espaces d'état à haute dimension
Garrett Warnell, Nicholas Waytowich, Vernon Lawhern, Peter Stone
Mot-clé: état de haute dimension, tirez parti de l'entrée de l'entraîneur humain
Code: tiers
Env: Atari
Apprentissage du renforcement profond des préférences humaines
Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei
MOT-CLÉ: Explorez l'objectif défini dans les préférences humaines entre la segmentation des paires de trajectoires, apprenez une chose plus complexe que la rétroaction humaine
Code: officiel
Env: Atari, Mujoco
Apprentissage interactif de la rétroaction humaine dépendante de la politique
James MacGlashan, Mark K HO, Robert Loftin, Bei Peng, Guan Wang, David Roberts, Matthew E. Taylor, Michael L. Littman
MOT-CLÉ: La décision est influencée par la politique actuelle plutôt que par les commentaires humains, apprendre des commentaires dépendants de la politique qui convergent vers un optimal local
format: - [title](codebase link) [links] - author1, author2, and author3... - keyword - experiment environments, datasets or tasks
Verl: Volcano Engine Renforcement Learning for LLM
Bytedance Seed Mlsys Team & hku: Guangming Sheng, Chi Zhang, Zilantfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, Chuan Wu
Mots-clés: cadre flexible, efficace, RLHF
Tâches: RLHF, tâches de raisonnement, y compris les mathématiques et le code.
Openrlhf
Openrlhf
Mot-clé: 70b, RLHF, Deeppeed, Ray, Vllm
Tâche: un cadre RLHF facile à utiliser, évolutif et haute performance (support 70B + Tuning complet & Lora & Mixtral & KTO).
PALM + RLHF - Pytorch
Phil Wang, Yachine Zahidi, Ikko Eltociar Ashimine, Eric Alcaide
Mots-clés: transformateurs, architecture de palmier
Ensemble de données: enwik8
LM-HUMAN-PRÉFÉRENCES
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, Geoffrey Irving
MOT-CLÉ: récompense l'apprentissage pour la langue, le texte continu avec un sentiment positif, tâche récapitulative, descriptif physique
Ensemble de données: TL; DR, CNN / DM
suivant-instructions-humain-feedback
Long Oulang, Jeff Wu, Xu Jiang, et al.
Mots-clés: modèle grand langage, alignement le modèle de langue avec l'intention humaine
Ensemble de données: Vériralqa RealToxicityPrompts
Apprentissage du renforcement du transformateur (TRL)
Leandro von Werra, Younes Belkada, Lewis Tunstall, et al.
Mots-clés: Train LLM avec RL, PPO, transformateur
Tâche: Sentiment IMDB
Apprentissage du renforcement du transformateur x (trlx)
Jonathan Tow, Leandro von Werra, et al.
Mots-clés: cadre de formation distribué, modèles de langage basés sur T5, Train LLM avec RL, PPO, ILQL
Tâche: Fine Tuning LLM avec RL en utilisant une fonction de récompense fournie ou un ensemble de données marqué par récompense
RL4LMS (une bibliothèque RL modulaire pour affiner les modèles de langage aux préférences humaines)
Rajkumar Ramamurthy, Prithviraj Ammanabrolu, Kianti, Brantley, Jack Hessel, Rafet Sifa, Christian Bauckhage, Hannaneh Hajishirzi, Yejin Choi
Mots-clés: Optimisation des générateurs de langues avec RL, référence, algorithme RL performant
Ensemble de données: IMDB, communen, CNN Daily Mail, Totto, WMT-16 (EN-DE), NarrativeQA, DailyDialog
Lamda-rlhf-pytorch
Phil Wang
Mots-clés: lamda, mécanisme d'attention
Tâche: implémentation pré-entraînement open source du document de recherche LAMDA de Google à Pytorch
Textrl
Eric Lam
Mots-clés: le transformateur de HuggingFace
Tâche: génération de texte
Env: PFRL, gym
minrlhf
Thomfoster
Mot-clé: PPO, bibliothèque minimale
Tâche: des fins éducatives
Chat de profondeur
Microsoft
Mots-clés: formation RLHF abordable
Dromadaire
Ibm
Mots-clés: supervision humaine minimale, auto-alignée
Tâche: modèle de langue auto-aligné formé avec une supervision humaine minimale
Fg-rlhf
Zeqiu WU, Yushi HU, Weijia Shi, et al.
Mots-clés: RLHF à grain fin, en fournissant une récompense après chaque segment, incorporant plusieurs RM associés à différents types de rétroaction
Tâche: un cadre qui permet la formation et l'apprentissage des fonctions de récompense qui sont à grain fin en densité et à plusieurs RMS -Safe-RLHF
Xuehai Pan, Ruiyang Sun, Jiaming Ji, et al.
Mots-clés: Prise en charge des modèles pré-formés populaires, de grands ensembles de données marqués par l'homme, des mesures à plusieurs échelles pour la vérification des contraintes de sécurité, des paramètres personnalisés
Tâche: LLM à base de valeur contrainte via RLHF Safe
format: - [title](dataset link) [links] - author1, author2, and author3... - keyword - experiment environments or tasks
HH-RLHF
Ben Mann, Deep Ganguli
Mot-clé: ensemble de données sur les préférences humaines, données d'équipe rouge, écrite par machine
Tâche: ensemble de données open-source pour les données de préférence humaine sur l'utilité et l'inrôme
Ensemble de données sur les préférences humaines de Stanford (SHP)
Ethayarajh, Kawin et Zhang, Heidi et Wang, Yizhong et Jurafsky, Dan
Mots-clés: ensemble de données naturel et rédigé, 18 sujets différents
Tâche: destiné à être utilisé pour la formation des modèles de récompense RLHF
Invite
Stephen H. Bach, Victor Sanh, Zheng-Xin Yong et al.
Mots-clés: ensembles de données en anglais invité, cartographier un exemple de données en langue naturelle
Tâche: boîte à outils pour créer, partager et utiliser des invites en langage naturel
Collections de ressources de mise à la terre des connaissances (SKG)
Tianbao Xie, Chen Henry Wu, Peng Shi et al.
Mots-clés: mise à la terre des connaissances structurées
Tâche: La collecte des ensembles de données est liée à la mise à la terre des connaissances structurées
La collection Flan
Longpre Shayne, Hou le, Vu Tu et al.
Tâche: Collection compile des ensembles de données de Flan 2021, P3, Instructions super-naturelles
rlhf-reward-datasets
Yiting Xie
Mot-clé: ensemble de données rédigé à la machine
webgpt_comparisons
Openai
Mots-clés: ensemble de données rédigé humain, réponse à la question longue réponse
Tâche: former un modèle de réponse à une question longue pour s'aligner sur les préférences humaines
résumer_from_feedback
Openai
Mots-clés: ensemble de données manuscrit sur l'homme, résumé
Tâche: former un modèle de résumé pour s'aligner sur les préférences humaines
Dahoas / synthétique-instruct-gptj-pairwise
Dahoas
Mot-clé: ensemble de données manuscrit, ensemble de données synthétique
Alignement stable - Apprentissage d'alignement dans les jeux sociaux
Ruibo Liu, Ruixine (Ray) Yang, Qiang Peng
Mots-clés: données d'interaction utilisées pour la formation à l'alignement, exécuter dans Sandbox
Tâche: s'entraîner sur les données d'interaction enregistrées dans les jeux sociaux simulés
Lima
Meta Ai
Mots-clés: sans aucun RLHF, quelques invites et réponses soigneusement organisées
Tâche: ensemble de données utilisé pour la formation du modèle Lima
[Openai] Chatgpt: Optimisation des modèles de langue pour le dialogue
[Face étreint] Illustrant l'apprentissage du renforcement de la rétroaction humaine (RLHF)
[Zhihu] 通向 AGI 之路 : 大型语言模型 (llm) 技术精要
[Zhihu] 大语言模型的涌现能力 : 现象与解释
[Zhihu] 中文 HH-rlHf 数据集上的 PPO 实践
[W&B entièrement connecté] Comprendre l'apprentissage du renforcement de la rétroaction humaine (RLHF)
[DeepMind] Apprentissage par la rétroaction humaine
[Notion] 深入理解语言模型的突现能力
[Notion] 拆解追溯 GPT-3,5 各项能力的起源
[GIST] Apprentissage du renforcement pour les modèles de langue
[YouTube] John Schulman - Renforcement apprenant de la rétroaction humaine: progrès et défis
[Openai / Arize] Openai sur l'apprentissage du renforcement avec des commentaires humains
[ENCORD] Guide du renforcement d'apprentissage de la rétroaction humaine (RLHF) pour la vision par ordinateur
[Weixun Wang] Aperçu de RL (HF) + LLM
turc
Notre objectif est de rendre ce repo encore meilleur. Si vous êtes intéressé à contribuer, veuillez vous référer à ici pour les instructions de contribution.
RLHF génial est publié sous la licence Apache 2.0.


