scratchplot story generation
1.0.0
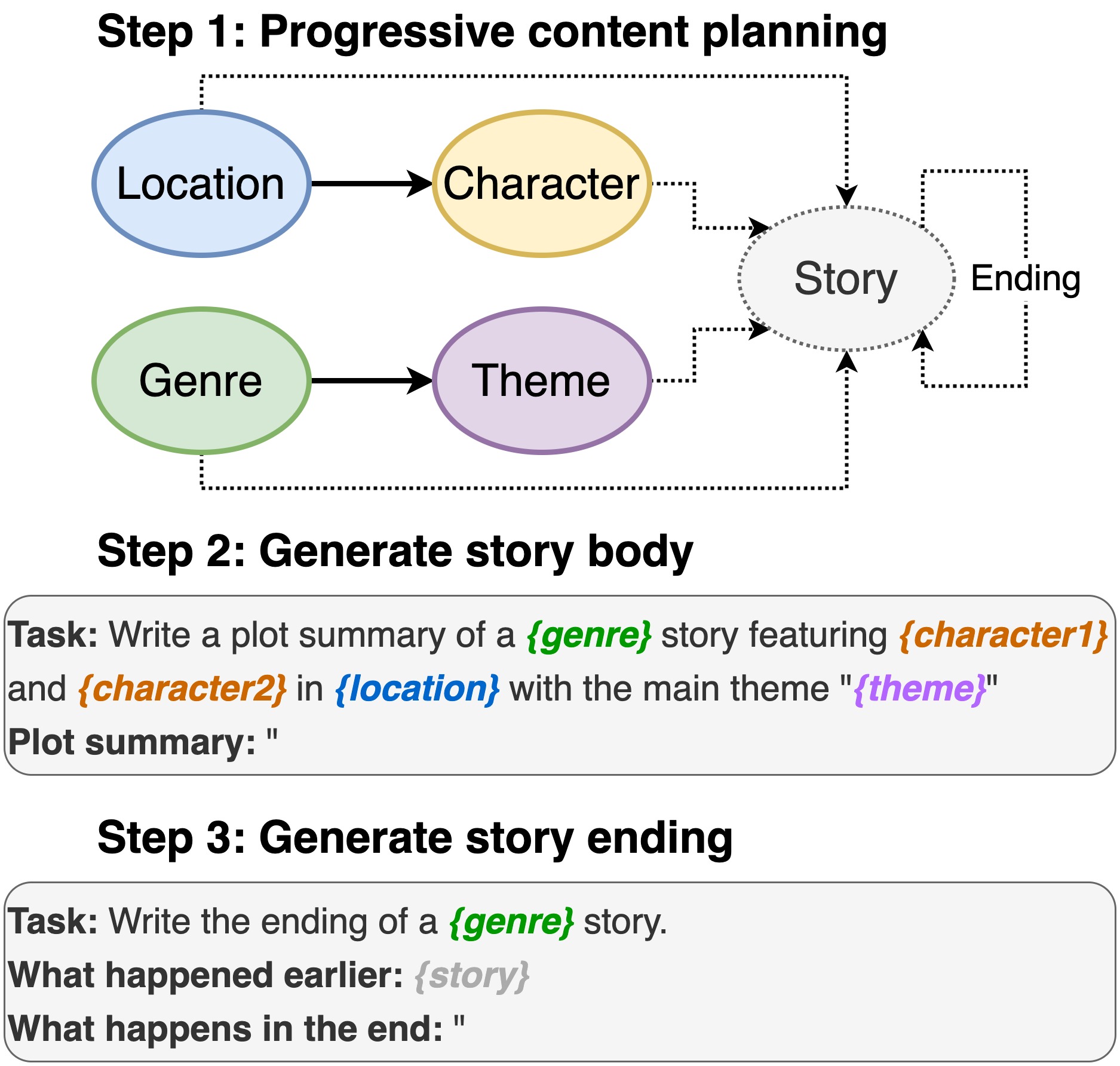
Ce référentiel contient le code d' écriture de tracé à partir de modèles de langage pré-formés , pour apparaître dans INLG 2022. Le document introduit une méthode pour d'abord invite un PLM à composer un plan de contenu. Ensuite, nous générons le corps de l'histoire et nous terminons conditionnés sur le plan de contenu. De plus, nous adoptons une approche de génération et de rang en utilisant des PLM supplémentaires pour classer les paires générées (histoire, fin).
Ce repo s'appuie fortement sur Dino. Puisque nous avons apporté des modifications mineures, nous incluons le code complet pour faciliter l'utilisation.
Y compris l'emplacement, le casting, le genre et le thème.
sh run_plot_static_gpu.shLes éléments du plan de contenu sont générés une fois et stockés. Lors de la génération des histoires, le système échantillonne à partir des éléments de l'intrigue générés hors ligne.
sh run_plot_dynamic_gpu_single.shsh run_plot_dynamic_gpu_batch.sh--no_cuda à toutes les commandes qui appellent dino.pyNécessite Python3. Testé sur Python 3.6 et 3.8.
pip3 install -r requirements.txt import nltk
nltk . download ( 'punkt' )
nltk . download ( 'stopwords' )Si vous utilisez le code dans ce référentiel, veuillez citer l'article suivant:
@inproceedings{jin-le-2022-plot,
title = "Plot Writing From Pre-Trained Language Models",
author = "Jin, Yiping and Kadam, Vishakha and Wanvarie, Dittaya",
booktitle = "Proceedings of the 15th International Natural Language Generation conference",
year = "2022",
address = "Maine, USA",
publisher = "Association for Computational Linguistics"
}
Si vous utilisez Dino pour d'autres tâches, veuillez également citer le document suivant:
@article{schick2020generating,
title={Generating Datasets with Pretrained Language Models},
author={Timo Schick and Hinrich Schütze},
journal={Computing Research Repository},
volume={arXiv:2104.07540},
url={https://arxiv.org/abs/2104.07540},
year={2021}
}


