OneForAll
1.0.0
Papier: https://arxiv.org/abs/2310.00149
Auteurs: Hao Liu, Jiarui Feng, Lecheng Kong, Ningyue Liang, Dacheng Tao, Yixin Chen, Muhan Zhang
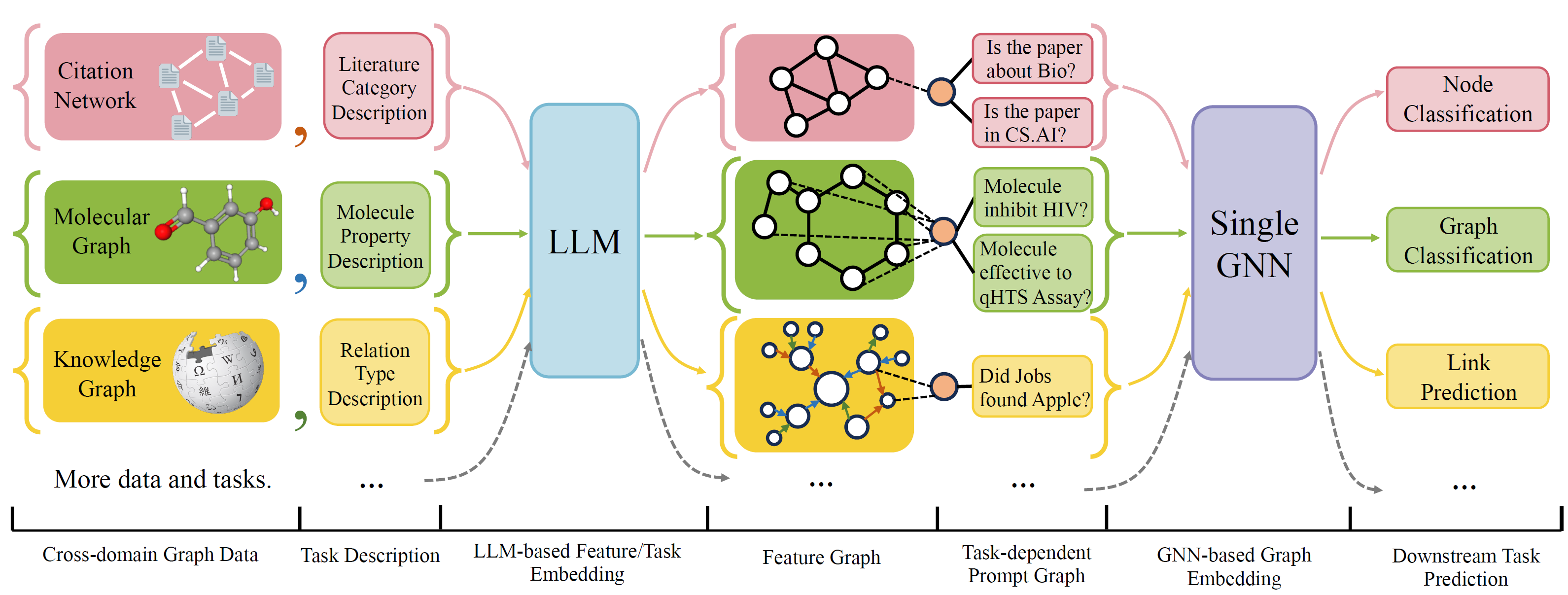
OFA est un cadre général de classification de graphiques qui peut résoudre une large gamme de tâches de classification des graphiques avec un seul modèle et un seul ensemble de paramètres. Les tâches sont dans le domaine croisé (par exemple le réseau de citation, le graphique moléculaire, ...) et les tâches croisées (par exemple, quelques coups, zéro-shot, niveau graphique, nœud-leve, ...)
OFA utilise des langues naturelles pour décrire tous les graphiques et utiliser un LLM pour intégrer toute la description dans le même espace d'incorporation, qui permettent une formation inter-domaine en utilisant un seul modèle.
OFA propose un paradiagme d'incitation que toutes les informations de tâche sont converties en graphique invite. Le modèle de sous-séquence est donc capable de lire les informations sur les tâches et de prédire la cible relative en conséquence, sans avoir à ajuster les paramètres et l'architecture du modèle. Par conséquent, un seul modèle peut être transversal.
OFA a organisé une liste d'ensembles de données de graphiques à partir de sources et de domaines différents et décrire les nœuds / bords dans les graphiques avec un protocole de décription systématique. Nous remercions les travaux précédents, notamment, OGB, Gimlet, Moleculenet, GraphllM et Villmow pour avoir fourni de merveilleuses données graphiques / texte brutes qui rendent notre travail possible.
OneForall a subi une révision majeure, où nous avons nettoyé le code et corrigé plusieurs bogues signalés. Les principales mises à jour sont:
Si vous avez déjà utilisé notre référentiel, veuillez extraire et supprimer les anciens fichiers de fonctionnalité / texte générés et régénérer. Désolé pour le dérangement.
Pour installer les besoins pour le projet à l'aide de conda:
conda env create -f environment.yml
Pour les expériences conjointes de bout en bout sur tous les ensembles de données collectés, exécutez
python run_cdm.py --override e2e_all_config.yaml
Tous les arguments peuvent être modifiés par des valeurs séparées d'espace telles que
python run_cdm.py --override e2e_all_config.yaml num_layers 7 batch_size 512 dropout 0.15 JK none
Les utilisateurs peuvent modifier la variable task_names dans ./e2e_all_config.yaml pour contrôler les ensembles de données inclus pendant la formation. La longueur de task_names , d_multiple et d_min_ratio devrait être la même. Ils peuvent également être spécifiés dans les arguments de ligne de commande par des valeurs séparées par des virgules.
par exemple
python run_cdm.py task_names cora_link,arxiv d_multiple 1,1 d_min_ratio 1,1
Ofa-ind peut être spécifié par
python run_cdm.py task_names cora_link d_multiple 1 d_min_ratio 1
Pour exécuter les expériences à quelques tirs et zéro
python run_cdm.py --override lr_all_config.yaml
Nous définissons les configurations pour chaque tâche, chaque configuration de tâche contient plusieurs configurations de jeux de données.
Les configurations de tâche sont stockées dans ./configs/task_config.yaml . Une tâche comprend généralement plusieurs divisions d'ensembles de données (pas nécessairement les mêmes ensembles de données). Par exemple, une tâche de classification de nœuds de Cora de bout en bout régulière aura la division du train de l'ensemble de données CORA comme ensemble de données de train, la répartition valide de l'ensemble de données CORA comme l'un des ensembles de données valides, et également pour la fraction de test. Vous pouvez également avoir plus de validation / test en spécifiant la répartition du train du CORA comme l'un des ensembles de données de validation / test. Plus précisément, une configuration de tâche ressemble à
arxiv :
eval_pool_mode : mean
dataset : arxiv # dataset name
eval_set_constructs :
- stage : train # a task should have one and only one train stage dataset
split_name : train
- stage : valid
split_name : valid
dataset : cora # replace the default dataset for zero-shot tasks
- stage : valid
split_name : valid
- stage : test
split_name : test
- stage : test
split_name : train # test the train split Les configurations d'ensemble de données sont stockées dans ./configs/task_config.yaml . Une configuration de l'ensemble de données définit la façon dont un ensemble de données est construit. Spécifiquement,
arxiv :
task_level : e2e_node
preprocess : null # name of the preprocess function defined in task_constructor.py
construct : ConstructNodeCls # name of the dataset construction function defined in task_constructor.py
args : # additional arguments to construct function
walk_length : null
single_prompt_edge : True
eval_metric : acc # evaluation metric
eval_func : classification_func # evaluation function that process model output and batch to input to evaluator
eval_mode : max # evaluation mode (min/max)
dataset_name : arxiv # name of the OFAPygDataset
dataset_splitter : ArxivSplitter # splitting function defined in task_constructor.py
process_label_func : process_pth_label # name of process label function that transform original label to the binary labels
num_classes : 40 Si vous implémentez un ensemble de données comme Cora / PubMed / ArXIV, nous vous recommandons d'ajouter un répertoire de vos données $ personnalisés_data $ sous Data / Single_Graph / $ personnalisé_data $ et implémenter gen_data.py sous le répertoire, vous pouvez utiliser Data / Cora / Gen_Data. py comme exemple.
Une fois les données construites, vous devez enregistrer votre nom de jeu de données ici et implémenter un séparateur comme ici. Si vous effectuez des tâches zéro-shot / à quelques coups, vous pouvez également constructeur ici.
Enfin, enregistrez une entrée de configuration dans configs / data_config.yaml. Par exemple, pour la classification des nœuds de bout en bout
$data_name$ :
<< : *E2E-node
dataset_name : $data_name$
dataset_splitter : $splitter$
process_label_func : ... # usually processs_pth_label should work
num_classes : $number of classes$Process_label_func convertit l'étiquette cible en étiquette binaire et transforme la classe d'intégration si la tâche est zéro-shot / in-shot, où le nombre de nœuds de classe n'est pas fixé. Une liste de processus Avalailable_label_func est là. Il prend en compte toutes les classes et la bonne étiquette. La sortie est un tuple: (étiquette, class_node_embedding, étiquette binaire / un hot).
Si vous voulez plus de flexibilité, l'ajout de jeux de données personnalisés nécessite l'implémentation d'une sous-classe personnalisée de l'ofapygDataset. Un modèle.
class CustomizedOFADataset ( OFAPygDataset ):
def gen_data ( self ):
"""
Returns a tuple of the following format
(data, text, extra)
data: a list of Pyg Data, if you only have a one large graph, you should still wrap it with the list.
text: a list of list of texts. e.g. [node_text, edge_text, label_text] this is will be converted to pooled vector representation.
extra: any extra data (e.g. split information) you want to save.
"""
def add_text_emb ( self , data_list , text_emb ):
"""
This function assigns generated embedding to member variables of the graph
data_list: data list returned in self.gen_data.
text_emb: list of torch text tensor corresponding to the returned text in self.gen_data. text_emb[0] = llm_encode(text[0])
"""
data_list [ 0 ]. node_text_feat = ... # corresponding node features
data_list [ 0 ]. edge_text_feat = ... # corresponding edge features
data_list [ 0 ]. class_node_text_feat = ... # class node features
data_list [ 0 ]. prompt_edge_text_feat = ... # edge features used in prompt node
data_list [ 0 ]. noi_node_text_feat = ... # noi node features, refer to the paper for the definition
return self . collate ( data_list )
def get_idx_split ( self ):
"""
Return the split information required to split the dataset, this optional, you can further split the dataset in task_constructor.py
"""
def get_task_map ( self ):
"""
Because a dataset can have multiple different tasks that requires different prompt/class text embedding. This function returns a task map that maps a task name to the desired text embedding. Specifically, a task map is of the following format.
prompt_text_map = {task_name1: {"noi_node_text_feat": ["noi_node_text_feat", [$Index in data[0].noi_node_text_feat$]],
"class_node_text_feat": ["class_node_text_feat",
[$Index in data[0].class_node_text_feat$]],
"prompt_edge_text_feat": ["prompt_edge_text_feat", [$Index in data[0].prompt_edge_text_feat$]]},
task_name2: similar to task_name 1}
Please refer to examples in data/ for details.
"""
return self . side_data [ - 1 ]
def get_edge_list ( self , mode = "e2e" ):
"""
Defines how to construct prompt graph
f2n: noi nodes to noi prompt node
n2f: noi prompt node to noi nodes
n2c: noi prompt node to class nodes
c2n: class nodes to noi prompt node
For different task/mode you might want to use different prompt graph construction, you can do so by returning a dictionary. For example
{"f2n":[1,0], "n2c":[2,0]} means you only want f2n and n2c edges, f2n edges have edge type 1, and its text embedding feature is data[0].prompt_edge_text_feat[0]
"""
if mode == "e2e_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ], "n2c" : [ 2 , 0 ], "c2n" : [ 4 , 0 ]}
elif mode == "lr_link" :
return { "f2n" : [ 1 , 0 ], "n2f" : [ 3 , 0 ]}

