text embeddings inference
v1.5.1
Une solution d'inférence rapide flamboyante pour les modèles d'intégration de texte.
Benchmark pour Baai / BGE-Base-en-V1.5 sur un NVIDIA A10 avec une longueur de séquence de 512 jetons:
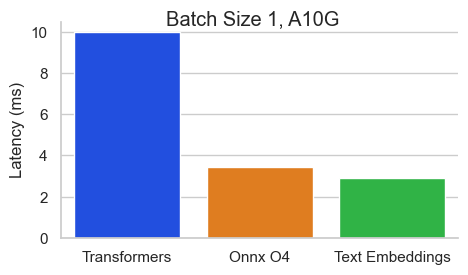
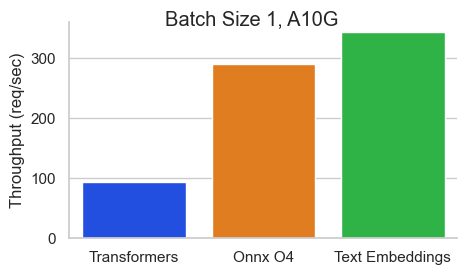
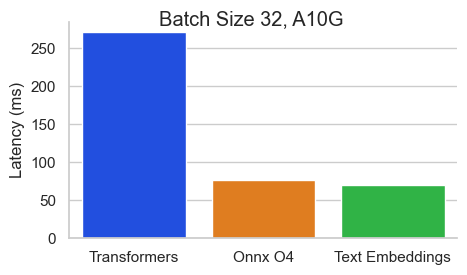
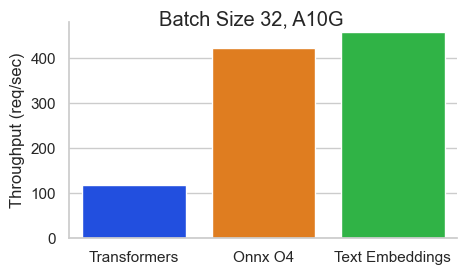
Le texte Incorpore Inférence (TEI) est une boîte à outils pour le déploiement et le service de modèles de classification de texte et de séquence open source. TEI permet une extraction à haute performance pour les modèles les plus populaires, notamment Flakemedding, Ember, GTE et E5. TEI implémente de nombreuses fonctionnalités telles que:
L'inférence des intérêts de texte prend actuellement en charge les modèles nomiques, Bert, Camembert, XLM-Roberta avec des positions absolues, un modèle Jinabert avec des positions Alibi et Mistral, Alibaba GTE et QWEN2 modèles avec des positions de corde.
Voici quelques exemples des modèles actuellement pris en charge:
| Rang MTEB | Taille du modèle | Type de modèle | ID de modèle |
|---|---|---|---|
| 1 | 7b (très cher) | Mistral | Salesforce / SFR-Embedding-2_R |
| 2 | 7b (très cher) | Qwen2 | Alibaba-NLP / GTE-QWEN2-7B-INSTRUCT |
| 9 | 1,5b (cher) | Qwen2 | Alibaba-NLP / GTE-QWEN2-1.5B-INSTRUCT |
| 15 | 0,4b | Alibaba GTE | Alibaba-NLP / GTE-LARGE-EN-V1.5 |
| 20 | 0,3b | Bert | Where Isai / UAE-Large-V1 |
| 24 | 0,5b | Xlm-roberta | intfloat / multilingue-e5-gren |
| N / A | 0.1b | Nomicbert | Nomic-ai / Nomic-Embed-Text-V1 |
| N / A | 0.1b | Nomicbert | Nomic-ai / Nomic-Embed-Text-V1.5 |
| N / A | 0.1b | Jinabert | Jinaai / Jina-Embeddings-V2-Base-en |
| N / A | 0.1b | Jinabert | Jinaai / Jina-Embeddings-V2-Base-Code |
Pour explorer la liste des modèles d'incorporation de texte les mieux performants, visitez le classement massif du texte intégré (MTEB).
L'inférence des intérêts du texte prend actuellement en charge les modèles de classification de séquence de séquences XLM-Roberta avec des positions absolues.
Voici quelques exemples des modèles actuellement pris en charge:
| Tâche | Type de modèle | ID de modèle |
|---|---|---|
| Recommandation | Xlm-roberta | Baai / bge-reranker-large |
| Recommandation | Xlm-roberta | Baai / BGE-RERANKER-base |
| Recommandation | Goer | Alibaba-NLP / GTE-multitilingual-Reranker-Base |
| Analyse des sentiments | Roberta | Samlowe / Roberta-Base-Go_emotions |
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelEt puis vous pouvez faire des demandes comme
curl 127.0.0.1:8080/embed
-X POST
-d ' {"inputs":"What is Deep Learning?"} '
-H ' Content-Type: application/json 'Remarque: Pour utiliser les GPU, vous devez installer la boîte à outils NVIDIA Container. Les pilotes NVIDIA sur votre machine doivent être compatibles avec CUDA version 12.2 ou plus.
Pour voir toutes les options pour servir vos modèles:
text-embeddings-router --help Usage: text-embeddings-router [OPTIONS]
Options:
--model-id <MODEL_ID>
The name of the model to load. Can be a MODEL_ID as listed on <https://hf.co/models> like `thenlper/gte-base`.
Or it can be a local directory containing the necessary files as saved by `save_pretrained(...)` methods of
transformers
[env: MODEL_ID=]
[default: thenlper/gte-base]
--revision <REVISION>
The actual revision of the model if you're referring to a model on the hub. You can use a specific commit id
or a branch like `refs/pr/2`
[env: REVISION=]
--tokenization-workers <TOKENIZATION_WORKERS>
Optionally control the number of tokenizer workers used for payload tokenization, validation and truncation.
Default to the number of CPU cores on the machine
[env: TOKENIZATION_WORKERS=]
--dtype <DTYPE>
The dtype to be forced upon the model
[env: DTYPE=]
[possible values: float16, float32]
--pooling <POOLING>
Optionally control the pooling method for embedding models.
If `pooling` is not set, the pooling configuration will be parsed from the model `1_Pooling/config.json` configuration.
If `pooling` is set, it will override the model pooling configuration
[env: POOLING=]
Possible values:
- cls: Select the CLS token as embedding
- mean: Apply Mean pooling to the model embeddings
- splade: Apply SPLADE (Sparse Lexical and Expansion) to the model embeddings. This option is only
available if the loaded model is a `ForMaskedLM` Transformer model
- last-token: Select the last token as embedding
--max-concurrent-requests <MAX_CONCURRENT_REQUESTS>
The maximum amount of concurrent requests for this particular deployment.
Having a low limit will refuse clients requests instead of having them wait for too long and is usually good
to handle backpressure correctly
[env: MAX_CONCURRENT_REQUESTS=]
[default: 512]
--max-batch-tokens <MAX_BATCH_TOKENS>
**IMPORTANT** This is one critical control to allow maximum usage of the available hardware.
This represents the total amount of potential tokens within a batch.
For `max_batch_tokens=1000`, you could fit `10` queries of `total_tokens=100` or a single query of `1000` tokens.
Overall this number should be the largest possible until the model is compute bound. Since the actual memory
overhead depends on the model implementation, text-embeddings-inference cannot infer this number automatically.
[env: MAX_BATCH_TOKENS=]
[default: 16384]
--max-batch-requests <MAX_BATCH_REQUESTS>
Optionally control the maximum number of individual requests in a batch
[env: MAX_BATCH_REQUESTS=]
--max-client-batch-size <MAX_CLIENT_BATCH_SIZE>
Control the maximum number of inputs that a client can send in a single request
[env: MAX_CLIENT_BATCH_SIZE=]
[default: 32]
--auto-truncate
Automatically truncate inputs that are longer than the maximum supported size
Unused for gRPC servers
[env: AUTO_TRUNCATE=]
--default-prompt-name <DEFAULT_PROMPT_NAME>
The name of the prompt that should be used by default for encoding. If not set, no prompt will be applied.
Must be a key in the `sentence-transformers` configuration `prompts` dictionary.
For example if ``default_prompt_name`` is "query" and the ``prompts`` is {"query": "query: ", ...}, then the
sentence "What is the capital of France?" will be encoded as "query: What is the capital of France?" because
the prompt text will be prepended before any text to encode.
The argument '--default-prompt-name <DEFAULT_PROMPT_NAME>' cannot be used with '--default-prompt <DEFAULT_PROMPT>`
[env: DEFAULT_PROMPT_NAME=]
--default-prompt <DEFAULT_PROMPT>
The prompt that should be used by default for encoding. If not set, no prompt will be applied.
For example if ``default_prompt`` is "query: " then the sentence "What is the capital of France?" will be
encoded as "query: What is the capital of France?" because the prompt text will be prepended before any text
to encode.
The argument '--default-prompt <DEFAULT_PROMPT>' cannot be used with '--default-prompt-name <DEFAULT_PROMPT_NAME>`
[env: DEFAULT_PROMPT=]
--hf-api-token <HF_API_TOKEN>
Your HuggingFace hub token
[env: HF_API_TOKEN=]
--hostname <HOSTNAME>
The IP address to listen on
[env: HOSTNAME=]
[default: 0.0.0.0]
-p, --port <PORT>
The port to listen on
[env: PORT=]
[default: 3000]
--uds-path <UDS_PATH>
The name of the unix socket some text-embeddings-inference backends will use as they communicate internally
with gRPC
[env: UDS_PATH=]
[default: /tmp/text-embeddings-inference-server]
--huggingface-hub-cache <HUGGINGFACE_HUB_CACHE>
The location of the huggingface hub cache. Used to override the location if you want to provide a mounted disk
for instance
[env: HUGGINGFACE_HUB_CACHE=]
--payload-limit <PAYLOAD_LIMIT>
Payload size limit in bytes
Default is 2MB
[env: PAYLOAD_LIMIT=]
[default: 2000000]
--api-key <API_KEY>
Set an api key for request authorization.
By default the server responds to every request. With an api key set, the requests must have the Authorization
header set with the api key as Bearer token.
[env: API_KEY=]
--json-output
Outputs the logs in JSON format (useful for telemetry)
[env: JSON_OUTPUT=]
--otlp-endpoint <OTLP_ENDPOINT>
The grpc endpoint for opentelemetry. Telemetry is sent to this endpoint as OTLP over gRPC. e.g. `http://localhost:4317`
[env: OTLP_ENDPOINT=]
--otlp-service-name <OTLP_SERVICE_NAME>
The service name for opentelemetry. e.g. `text-embeddings-inference.server`
[env: OTLP_SERVICE_NAME=]
[default: text-embeddings-inference.server]
--cors-allow-origin <CORS_ALLOW_ORIGIN>
Unused for gRPC servers
[env: CORS_ALLOW_ORIGIN=]
Les intérêts de texte en inférence sont expédiés avec plusieurs images Docker que vous pouvez utiliser pour cibler un backend spécifique:
| Architecture | Image |
|---|---|
| Processeur | ghcr.io/huggingface/text-embeddings-inference:cpu-1.5 |
| Volta | Non pris en charge |
| Turing (T4, RTX 2000 Series, ...) | ghcr.io/huggingface/text-embeddings-inference: turain-1.5 (expérimental) |
| Ampère 80 (A100, A30) | ghcr.io/huggingface/text-embeddings-inference:1.5 |
| Ampère 86 (A10, A40, ...) | ghcr.io/huggingface/text-embeddings-inference:86-1.5 |
| Ada Lovelace (série RTX 4000, ...) | ghcr.io/huggingface/text-embeddings-inference:89-1.5 |
| Hopper (H100) | ghcr.io/huggingface/text-embeddings-inference:hopper-1.5 (expérimental) |
Avertissement : l'attention du flash est désactivée par défaut pour l'image Turing car elle souffre de problèmes de précision. Vous pouvez activer l'attention du flash v1 en utilisant la variable USE_FLASH_ATTENTION=True Environment.
Vous pouvez consulter la documentation OpenAPI de l'API REST text-embeddings-inference à l'aide de l'itinéraire /docs . L'interface utilisateur de Swagger est également disponible sur: https://huggingface.github.io/text-embeddings-inférence.
Vous avez la possibilité d'utiliser la variable d'environnement HF_API_TOKEN pour configurer le jeton utilisé par text-embeddings-inference . Cela vous permet d'accéder aux ressources protégées.
Par exemple:
HF_API_TOKEN=<your cli READ token>ou avec Docker:
model= < your private model >
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
token= < your cli READ token >
docker run --gpus all -e HF_API_TOKEN= $token -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelPour déployer l'inférence des incorporations de texte dans un environnement à air, téléchargez d'abord les poids, puis montez-les à l'intérieur du conteneur à l'aide d'un volume.
Par exemple:
# (Optional) create a `models` directory
mkdir models
cd models
# Make sure you have git-lfs installed (https://git-lfs.com)
git lfs install
git clone https://huggingface.co/Alibaba-NLP/gte-base-en-v1.5
# Set the models directory as the volume path
volume= $PWD
# Mount the models directory inside the container with a volume and set the model ID
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id /data/gte-base-en-v1.5 text-embeddings-inference V0.4.0 Ajout de la prise en charge des modèles de classification des séquences Camembert, Roberta, XLM-Roberta et GTE. Les modèles de Reckankers sont des modèles de co-codeurs de classification de séquence avec une seule classe qui marque la similitude entre une requête et un texte.
Consultez ce blog par l'équipe Llamaindex pour comprendre comment vous pouvez utiliser des modèles RE-RANKERS dans votre pipeline de chiffons pour améliorer les performances en aval.
model=BAAI/bge-reranker-large
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $modelEt puis vous pouvez classer la similitude entre une requête et une liste de textes avec:
curl 127.0.0.1:8080/rerank
-X POST
-d ' {"query": "What is Deep Learning?", "texts": ["Deep Learning is not...", "Deep learning is..."]} '
-H ' Content-Type: application/json ' Vous pouvez également utiliser des modèles classiques de classification de séquence comme SamLowe/roberta-base-go_emotions :
model=SamLowe/roberta-base-go_emotions
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model Une fois que vous avez déployé le modèle, vous pouvez utiliser le point de terminaison predict pour obtenir les émotions les plus associées à une entrée:
curl 127.0.0.1:8080/predict
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json 'Vous pouvez choisir d'activer la regroupement des défilés pour les architectures de Bert et Distilbert Maskedlm:
model=naver/efficient-splade-VI-BT-large-query
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5 --model-id $model --pooling splade Une fois que vous avez déployé le modèle, vous pouvez utiliser le point de terminaison /embed_sparse pour obtenir l'intégration clairsemée:
curl 127.0.0.1:8080/embed_sparse
-X POST
-d ' {"inputs":"I like you."} '
-H ' Content-Type: application/json ' text-embeddings-inference est instrumenté avec un traçage distribué en utilisant l'opentélémétrie. Vous pouvez utiliser cette fonctionnalité en définissant l'adresse sur un collectionneur OTLP avec l'argument --otlp-endpoint .
text-embeddings-inference propose une API GRPC comme alternative à l'API HTTP par défaut pour les déploiements haute performance. La définition de l'API Protobuf peut être trouvée ici.
Vous pouvez utiliser l'API GRPC en ajoutant la balise -grpc à n'importe quelle image Docker TEI. Par exemple:
model=BAAI/bge-large-en-v1.5
volume= $PWD /data # share a volume with the Docker container to avoid downloading weights every run
docker run --gpus all -p 8080:80 -v $volume :/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.5-grpc --model-id $model grpcurl -d ' {"inputs": "What is Deep Learning"} ' -plaintext 0.0.0.0:8080 tei.v1.Embed/Embed Vous pouvez également choisir d'installer localement text-embeddings-inference .
Installez d'abord la rouille:
curl --proto ' =https ' --tlsv1.2 -sSf https://sh.rustup.rs | shPuis courez:
# On x86
cargo install --path router -F mkl
# On M1 or M2
cargo install --path router -F metalVous pouvez désormais lancer une inférence d'intégration de texte sur CPU avec:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Remarque: Sur certaines machines, vous pouvez également avoir besoin des bibliothèques OpenSSL et du GCC. Sur les machines Linux, exécutez:
sudo apt-get install libssl-dev gcc -yLes GPU avec les capacités de calcul CUDA <7,5 ne sont pas pris en charge (V100, Titan V, GTX 1000, ...).
Assurez-vous que CUDA et les pilotes Nvidia sont installés. Les pilotes NVIDIA sur votre appareil doivent être compatibles avec CUDA version 12.2 ou plus. Vous devez également ajouter les binaires Nvidia à votre chemin:
export PATH= $PATH :/usr/local/cuda/binPuis courez:
# This can take a while as we need to compile a lot of cuda kernels
# On Turing GPUs (T4, RTX 2000 series ... )
cargo install --path router -F candle-cuda-turing -F http --no-default-features
# On Ampere and Hopper
cargo install --path router -F candle-cuda -F http --no-default-featuresVous pouvez désormais lancer une inférence d'intégration de texte sur GPU avec:
model=BAAI/bge-large-en-v1.5
text-embeddings-router --model-id $model --port 8080Vous pouvez construire le conteneur CPU avec:
docker build .Pour construire les conteneurs CUDA, vous devez connaître le plafond de calcul du GPU que vous utiliserez au moment de l'exécution.
Ensuite, vous pouvez construire le conteneur avec:
# Example for Turing (T4, RTX 2000 series, ...)
runtime_compute_cap=75
# Example for A100
runtime_compute_cap=80
# Example for A10
runtime_compute_cap=86
# Example for Ada Lovelace (RTX 4000 series, ...)
runtime_compute_cap=89
# Example for H100
runtime_compute_cap=90
docker build . -f Dockerfile-cuda --build-arg CUDA_COMPUTE_CAP= $runtime_compute_capComme expliqué ici, prêt pour MPS, ARM64 Docker Image, Metal / MPS n'est pas pris en charge via Docker. En tant que telle, l'inférence sera liée au processeur et probablement assez lente lors de l'utilisation de cette image Docker sur un processeur M1 / M2 ARM.
docker build . -f Dockerfile --platform=linux/arm64


