experts
1.0.0

Experts.js est le moyen le plus simple de créer et de déployer les assistants d'Openai et de les relier ensemble comme outils pour créer un panneau d'experts avec une mémoire étendue et une attention aux détails.
Fabriqué via le support ❤️ par encre personnalisée | Technologie
L'API des nouvelles assistants d'OpenAI établit une nouvelle norme de l'industrie, avançant considérablement au-delà de l'API de compléments de chat largement adoptée. Il représente un saut majeur dans la convivialité des agents de l'IA et la façon dont les ingénieurs interagissent avec les LLM. Associés au mini modèle GPT-4O de pointe, les assistants peuvent désormais référencer les fichiers et images joints en tant que sources de connaissances dans une fenêtre de contexte gérée appelée thread. Contrairement aux GPT personnalisés, les assistants prennent en charge les instructions jusqu'à 256 000 caractères, s'intègrent à 128 outils et utilisent l'API innovant du magasin vectoriel pour une recherche de fichiers efficace sur 10 000 fichiers par assistant.
Experts.js vise à simplifier l'utilisation de cette nouvelle API en supprimant la complexité de la gestion des objets RUN et en permettant aux assistants d'être liés entre eux comme outils.
import { Assistant , Thread } from "experts" ;
const thread = await Thread . create ( ) ;
const assistant = await Assistant . create ( ) ;
const output = await assistant . ask ( "Say hello." , thread . id ) ;
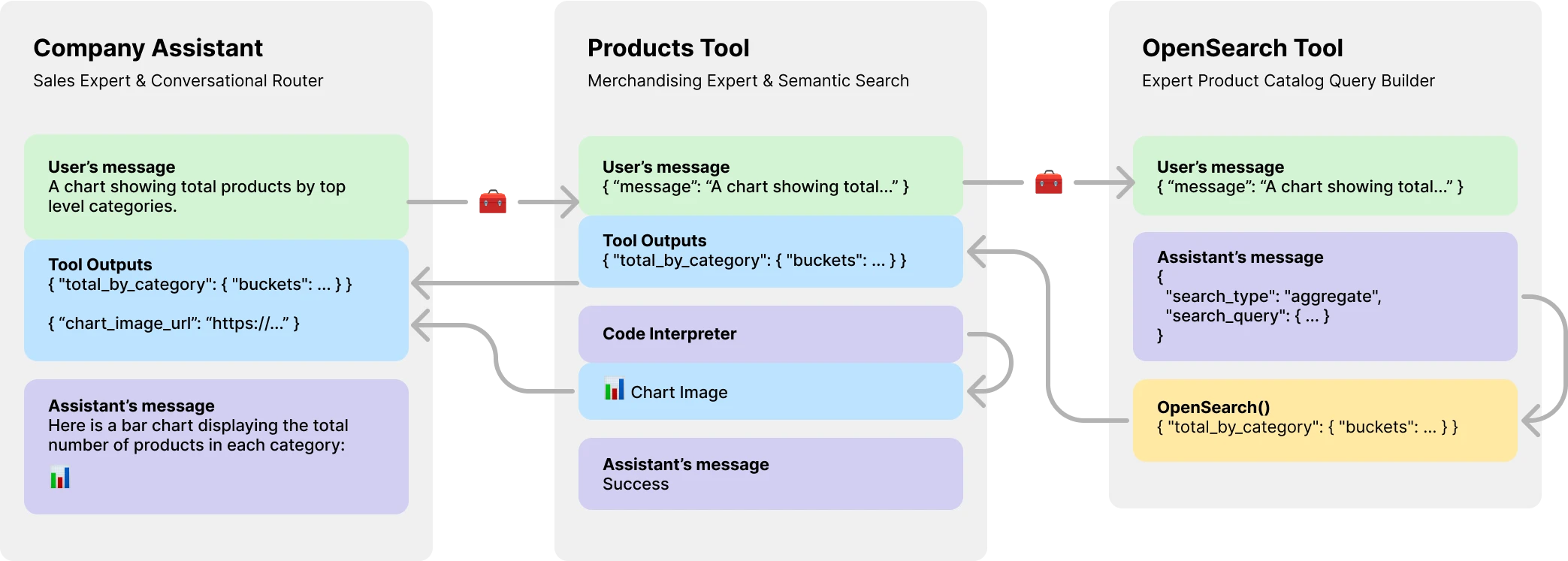
console . log ( output ) // HelloPlus important encore, des experts.js présentent des assistants comme des outils, permettant la création de systèmes d'agents multi-ai. Chaque outil est un assistant soutenu par LLM qui peut assumer des rôles spécialisés ou accomplir des tâches complexes au nom de son assistant ou de son outil parent. Permettre des flux de travail d'orchestration complexes ou chorégraphier une série de tâches serrées. Il y a ici un exemple d'assistant d'entreprise avec un outil de catalogue de produits qui a lui-même un outil soutenu LLM pour créer des requêtes OpenSearch.
Installez via NPM. L'utilisation est très simple, il n'y a que trois objets à importer.
npm install expertsExperts.js prend en charge la syntaxe d'importation ES6 et CommonJS exiger des instructions.
import { Assistant , Tool , Thread } from "experts" ; Le constructeur de notre objet de façade assistant nécessite un nom, une description et des instructions. Le troisième argument est un ensemble d'options qui mappe directement à toutes les options de corps de demande décrites dans la documentation de création de l'assistant. Tous les exemples dans des experts.js sont écrits en classes ES6 pour la simplicité. Le modèle par défaut est gpt-4o-mini .
class MyAssistant extends Assistant {
constructor ( ) {
super ( {
name : "My Assistant" ,
instructions : "..." ,
model : "gpt-4o-mini" ,
tools : [ { type : "file_search" } ] ,
temperature : 0.1 ,
tool_resources : {
file_search : {
vector_store_ids : [ process . env . VECTOR_STORE_ID ] ,
} ,
} ,
} ) ;
}
}
const assistant = await MyAssistant . create ( ) ; La fonction d'usine de base experts.js ASYNC Assistant.create() est un moyen simple de créer un assistant utilisant les mêmes options de constructeur.
const assistant = Assistant . create ( {
name : "My Assistant" ,
instructions : "..." ,
model : "gpt-4o-mini" ,
} ) ; Important
La création d'assistants sans paramètre id créera toujours un nouvel assistant. Voir notre section de déploiement pour plus d'informations.
La fonction ask() est une interface simple pour demander ou instruire vos assistants. Il nécessite un message et un identifiant de fil. Plus sur les fils ci-dessous. Le message peut être une chaîne ou un objet de message OpenAI natif. C'est là que les experts.js brillent vraiment. Vous n'avez jamais à gérer directement les objets d'exécution ou leurs étapes d'exécution.
const output = await assistant . ask ( "..." , threadID )
const output = await assistant . ask ( { role : "user" , content : "..." } , threadID ) ; Les outils OpenAI normaux et les appels de fonction sont pris en charge via notre objet Options Constructeurs via tools et tool_resources . Experts.js prend également en charge l'ajout d'assistants comme outils. Plus d'informations sur l'utilisation des assistants comme outils peuvent être trouvées dans la section suivante. Utilisez la fonction addAssistantTool pour ajouter un assistant comme outil. Cela doit arriver après super() dans le constructeur de votre assistant.
class MainAssistant extends Assistant {
constructor ( ) {
super ( {
name : "Company Assistant" ,
instructions : "..." ,
} ) ;
this . addAssistantTool ( ProductsTools ) ;
}
}Par défaut, des experts.js exploitent les événements de streaming des assistants. Ceux-ci permettent à vos applications de recevoir des sorties de texte, d'image et d'outil via les événements Server-Ennd d'Openai. Nous tirons parti des aides de flux d'Openai-Node et faisons surface ces événements ainsi que quelques-uns personnalisés donnant à vos assistants pour exploiter le cycle de vie complet d'une course.
const assistant = await MainAssistant . create ( ) ;
assistant . on ( "textDelta" , ( delta , _snapshot ) => {
process . stdout . write ( delta . value )
} ) ; Tous les événements de streaming à nœuds Openai sont pris en charge via notre fonction on() . Les noms d'événements disponibles sont: event , textDelta , textDone , imageFileDone , toolCallDelta , runStepDone , toolCallDone et end
Important
Les événements d'Openai Server-Send ne sont pas adaptés à l'async / à attendre.
Si vos auditeurs doivent effectuer des travaux de manière asynchrone, tels que la redirection des sorties d'outils, envisagez d'utiliser nos extensions vers ces événements. Ils sont appelés dans cet ordre une fois la course terminée. Les noms d'événements asynchrones disponibles sont: textDoneAsync , imageFileDoneAsync , runStepDoneAsync , toolCallDoneAsync et endAsync .
Si vous souhaitez stopper paresseusement des ressources supplémentaires lorsque la fonction create() d'un assistant est appelée, implémentez la fonction beforeInit() dans votre classe. Il s'agit d'une méthode asynchrone qui sera appelée avant la création de l'assistant.
async beforeInit ( ) {
await this . # createFileSearch ( ) ;
} De même, la fonction afterInit() peut être utilisée. Par exemple, pour rédiger les ID assistants nouvellement créés dans un fichier environnement.
async afterInit ( ) {
// ...
} Tous les événements adjoints reçoivent un argument de métadonnées supplémentaires d'experts. Un objet qui contient le stream de la course. Cela vous permet d'utiliser les fonctions d'assistance du nœud Openai telles que currentEvent , finalMessages , etc.
assistant . on ( "endAsync" , async ( metadata ) => {
await metadata . stream . finalMessages ( ) ;
} ) ; L'utilisation d'un assistant comme outil est le point focal central du cadre experts.js. Les outils sont une sous-classe d'assistant et encapsulent l'interface de leurs objets parents. De cette façon, les outils d'experts. Nos exemples illustrent un modèle de passage de message de base, pour la concision. Vous devez tirer parti de toutes les fonctionnalités de l'outil et de la fonction d'Openai au maximum.
class EchoTool extends Tool {
constructor ( ) {
super ( {
name : "Echo Tool" ,
instructions : "Echo the same text back to the user" ,
parentsTools : [
{
type : "function" ,
function : {
name : "echo" ,
description : description ,
parameters : {
type : "object" ,
properties : { message : { type : "string" } } ,
required : [ "message" ] ,
} ,
} ,
} ,
] ,
} ) ;
}
} Prudence
Il est essentiel que le nom de fonction de votre outil soit unique dans l'ensemble des noms d'outils de son parent.
En tant que tels, les noms de classe d'outils sont importants et aident les modèles d'Openai à décider quel outil appeler. Alors choisissez un bon nom pour votre classe d'outils. Par exemple, ProductsOpenSearchTool sera products_open_search et aide clairement le modèle à déduire avec la description de l'outil quel rôle il joue.
Des outils sont ajoutés à votre assistant via la fonction addAssistantTool . Cette fonction ajoutera l'outil au tableau d'outils de l'assistant et mettra à jour la configuration de l'assistant. Cela doit arriver après super() dans le constructeur de votre assistant.
class MainAssistant extends Assistant {
constructor ( ) {
super ( {
name : "Company Assistant" ,
instructions : "..."
} ) ;
this . addAssistantTool ( EchoTool ) ;
}
}Votre réponse d'assistant d'outil sera automatiquement soumise en tant que sortie pour l'assistant parent ou l'outil.
Par défaut, les outils sont soutenus par un model LLM et effectuent tous les mêmes événements de cycle de vie, exécutions, etc. en tant qu'assistants. Cependant, vous pouvez créer un outil qui n'utilise aucune des fonctionnalités de l'assistant principal en définissant l'option llm sur false . Ce faisant, vous devez implémenter la fonction ask() dans votre outil. La valeur de retour sera soumise en tant que sortie de l'outil.
class AnswerTwoTool extends Tool {
constructor ( ) {
super ( {
// ...
llm : false ,
parentsTools : [ ... ] ,
} ) ;
}
async ask ( message ) {
return ... ;
}
} Dans les workflows complexes, un outil sauvegardé LLM peut être utilisé pour convertir les instructions humaines ou autres LLM en code exécutable et le résultat de ce code (et non la sortie LLM) devrait être soumis pour les sorties de votre outil. Par exemple, le ProductsOpenSearchTool pourrait convertir des messages en requêtes OpenSearch, les exécuter et renvoyer les résultats. Les sous-classes peuvent implémenter la fonction answered() pour contrôler la sortie. Dans ce cas, la output serait une requête Opensearch et les sorties d'outils contiennent désormais les résultats de cette requête générée par LLM.
async answered ( output ) {
const args = JSON . parse ( output ) ;
return await this . opensearchQuery ( args ) ;
}Alternativement, les outils sauvegardés LLM pourraient choisir de rediriger leurs propres sorties d'outils vers leur assistant parent ou outil. Ignorant ainsi la sortie LLM. Cela permet également de soumettre toutes les sorties d'outils d'outils en tant que sortie du parent. En savoir plus sur les raisons pour lesquelles cela est important dans l'exemple du catalogue de produits ci-dessous.
class ProductsTool extends Tool {
constructor ( ) {
super ( {
// ...
temperature : 0.1 ,
tools : [ { type : "code_interpreter" } ] ,
outputs : "tools" ,
parentsTools : [ ... ] ,
} ) ;
this . addAssistantTool ( ProductsOpenSearchTool ) ;
this . on ( "imageFileDoneAsync" , this . imageFileDoneAsync . bind ( this ) ) ;
}
} L'API Assistants d'Openai présente une nouvelle ressource appelée threads dans lesquels les messages et les fichiers sont stockés. Essentiellement, les threads sont une fenêtre de contexte gérée (mémoire) pour vos agents. La création d'un nouveau fil avec des experts.js est aussi simple que:
const thread = await Thread . create ( ) ;
console . log ( thread . id ) // thread_abc123Vous pouvez également créer un thread avec des messages, des fichiers ou des ressources d'outils pour démarrer une conversation. Nous prenons en charge le corps de la demande de thread d'Openai décrit dans leur référence API Threads.
const thread = await Thread . create ( {
messages : [
{ role : "user" , content : "My name is Ken" } ,
{ role : "user" , content : "Oh, my last name is Collins" } ,
] ,
} ) ;
const output = await assistant . ask ( "What is my full name?" , thread . id ) ;
console . log ( output ) // Ken CollinsPar défaut, chaque outil dans experts.js a son propre thread et son contexte. Cela évite un problème de verrouillage de thread potentiel qui se produit si un outil devait partager le thread d'un assistant en attendant que les sorties d'outils soient soumises. Le diagramme suivant illustre comment les experts.js gèrent les threads en votre nom pour éviter ce problème:

Toutes les questions à vos experts nécessitent un identifiant de fil. Pour les applications de chat, l'ID serait stocké sur le client. Comme un paramètre de chemin d'URL. Avec experts.js, aucun autre identifiant côté client n'est nécessaire. Comme chaque assistant appelle un outil soutenu LLM, il trouvera ou créera un thread pour cet outil selon les besoins. Experts.js stocke cette relation parent -> Child Thread pour vous en utilisant les métadonnées du thread d'Openai.
Les courses sont gérées pour vous derrière la fonction ask de l'assistant. Cependant, vous pouvez toujours transmettre des options qui seront utilisées lors de la création d'un exécution de deux manières.
Tout d'abord, vous pouvez spécifier run_options dans le constructeur de l'assistant. Ces options seront utilisées pour toutes les exécutions créées par l'assistant. C'est un excellent moyen de forcer le modèle à utiliser un outil via l'option tool_choice .
class CarpenterAssistant extends Assistant {
constructor ( ) {
super ( {
// ...
run_options : {
tool_choice : {
type : "function" ,
function : { name : "my_tool_name" } ,
} ,
} ,
} ) ;
this . addAssistantTool ( MyTool ) ;
}
} Alternativement, vous pouvez transmettre un objet Options à la méthode ask à utiliser pour l'exécution actuelle. C'est un excellent moyen de créer des options à exécution unique.
await assistant . ask ( "..." , "thread_abc123" , {
run : {
tool_choice : { type : "function" , function : { name : "my_tool_name" } } ,
additional_instructions : "..." ,
additional_messages : [ ... ] ,
} ,
} ) ; Pour voir des exemples de code de ceux-ci et plus en action, veuillez jeter un œil à notre suite de tests.
Dans la section Aperçu, nous avons montré un système d'agent à trois niveaux qui peut répondre aux types de questions suivants. Les exemples utilisent la plupart, sinon la totalité, les fonctionnalités du framework experts.js.
Exemple de base en utilisant l'événement textDelta pour diffuser des réponses à partir d'une route express.
import express from "express" ;
import { MainAssistant } from "../experts/main.js" ;
const assistant = await MainAssistant . create ( ) ;
messagesRouter . post ( "" , async ( req , res , next ) => {
res . setHeader ( "Content-Type" , "text/plain" ) ;
res . setHeader ( "Transfer-Encoding" , "chunked" ) ;
assistant . on ( "textDelta" , ( delta , _snapshot ) => {
res . write ( delta . value ) ;
} ) ;
await assistant . ask ( req . body . message . content , req . body . threadID ) ;
res . end ( ) ;
} ) ; L'API de l'assistant prend en charge les messages avec des images à l'aide des types de contenu image_url ou image_file . Étant donné que notre fonction ask() prend en charge les chaînes ou les objets de message OpenAI natifs.
const output = await assistant . ask (
{
role : "user" ,
content : [
{ type : "text" , text : "Tell me about this image." } ,
{ type : "image_file" , image_file : { file_id : file . id detail : "high" } } ,
] ,
} ,
threadID
) ; L'utilisation d'un magasin vectoriel pour la recherche de fichiers est facile à l'aide de l'interface d'Openai via notre troisième option de configuration. Vous pouvez également créer votre magasin vectoriel à la demande à l'aide de notre fonction beforeInit() décrite dans les fonctionnalités avancées.
class VectorSearchAssistant extends Assistant {
constructor ( ) {
super ( {
name : "Vector Search Assistant" ,
instructions : "..." ,
tools : [ { type : "file_search" } ] ,
temperature : 0.1 ,
tool_resources : {
file_search : {
vector_store_ids : [ process . env . VECTOR_STORE_ID ] ,
} ,
} ,
} ) ;
}
}L'utilisation de la fonction de streaming et d'événements pour signaler l'utilisation de jetons vous permet d'avoir des métriques assistantes.
class MyAssistant extends Assistant {
constructor ( ) {
super ( {
// ...
} ) ;
this . on ( "runStepDone" , this . # reportUsage . bind ( this ) ) ;
}
# reportUsage ( runStep ) {
if ( ! runStep ?. usage ?. total_tokens ) return ;
const iT = runStep . usage . prompt_tokens ;
const oT = runStep . usage . completion_tokens ;
const tT = runStep . usage . total_tokens ;
console . log ( { InTokens : iT , OutTokens : oT , TotalTokens : tT } ) ;
}
} Pour qu'un assistant soit déployé dans un environnement de production, nous recommandons les configurations suivantes. Tout d'abord, créez ou trouvez l'identification de votre assistant. La chaîne sera dans le format de asst_abc123 . Ensuite, passez cet ID dans le constructeur de l'assistant ou des outils. Cela garantira que le même assistant est utilisé dans tous les déploiements.
class MyAssistant extends Assistant {
constructor ( ) {
super ( {
// ...
id : process . env . MY_ASSISTANT_ID
} ) ;
}
} Une fois qu'un assistant ou un outil est trouvé par ID, toutes les configurations distantes qui sont différentes sont remplacées par les configurations locales. Si nécessaire, par exemple dans un environnement de stadification, vous pouvez contourner ce comportement en définissant l'option skipUpdate sur true .
Vous pouvez définir le modèle à l'échelle mondiale pour tous les assistants à l'aide de la variable d'environnement EXPERTS_DEFAULT_MODEL . Cela ne fonctionne que si vous n'avez pas explicitement défini le modèle dans le constructeur de votre assistant.
Pour déboguer votre assistant, vous pouvez définir la variable d'environnement DEBUG=1 . Cela sortira la journalisation verbale de tous les appels d'API et des événements de fin de serveur. Les événements Delta peuvent être quelque peu verbeux et sont désactivés par défaut. Veuillez également utiliser la variable d'environnement DEBUG_DELTAS=1 pour les activer.
Ce projet exploite des conteneurs de développement, ce qui signifie que vous pouvez l'ouvrir dans n'importe quel IDE de support pour commencer immédiatement. Cela inclut l'utilisation du code vs avec des conteneurs de développement qui est l'approche recommandée.
Une fois ouvert dans votre conteneur de développement, créez un fichier .env.development.local avec votre touche API OpenAI et la clé API Postimage.org:
OPENAI_API_KEY=sk-...
POST_IMAGES_API_KEY=...
Vous pouvez maintenant exécuter les commandes suivantes:
./bin/setup
./bin/test

