lang2sql
1.0.0
Ce dépôt fournit un guide étape par étape et un modèle pour configurer un langage naturel au générateur de code SQL avec l'API OPNEAI.
Le tutoriel est également disponible sur Medium.
Dernière mise à jour: 7 janvier 2024
Le développement rapide des modèles de langage naturel, en particulier les modèles de langage grand (LLMS), a présenté de nombreuses possibilités pour divers domaines. L'une des applications les plus courantes consiste à utiliser les LLM pour le codage. Par exemple, le Chatgpt d'Openai et le Code Llama de Meta sont des LLM qui offrent un langage naturel de pointe aux générateurs de code. Un cas d'utilisation potentiel est un langage naturel pour le générateur de code SQL, qui pourrait aider les professionnels non techniques avec des demandes de données simples et, espérons-le, permettre aux équipes de données de se concentrer sur des tâches plus intensives de données. Ce didacticiel se concentre sur la configuration d'une langue pour le générateur de code SQL à l'aide de l'API OpenAI.
Une application possible est un chatbot qui peut répondre aux requêtes utilisateur avec des données pertinentes (figure 1). Le chatbot peut être intégré à un canal Slack à l'aide d'une application Python qui effectue les étapes suivantes:
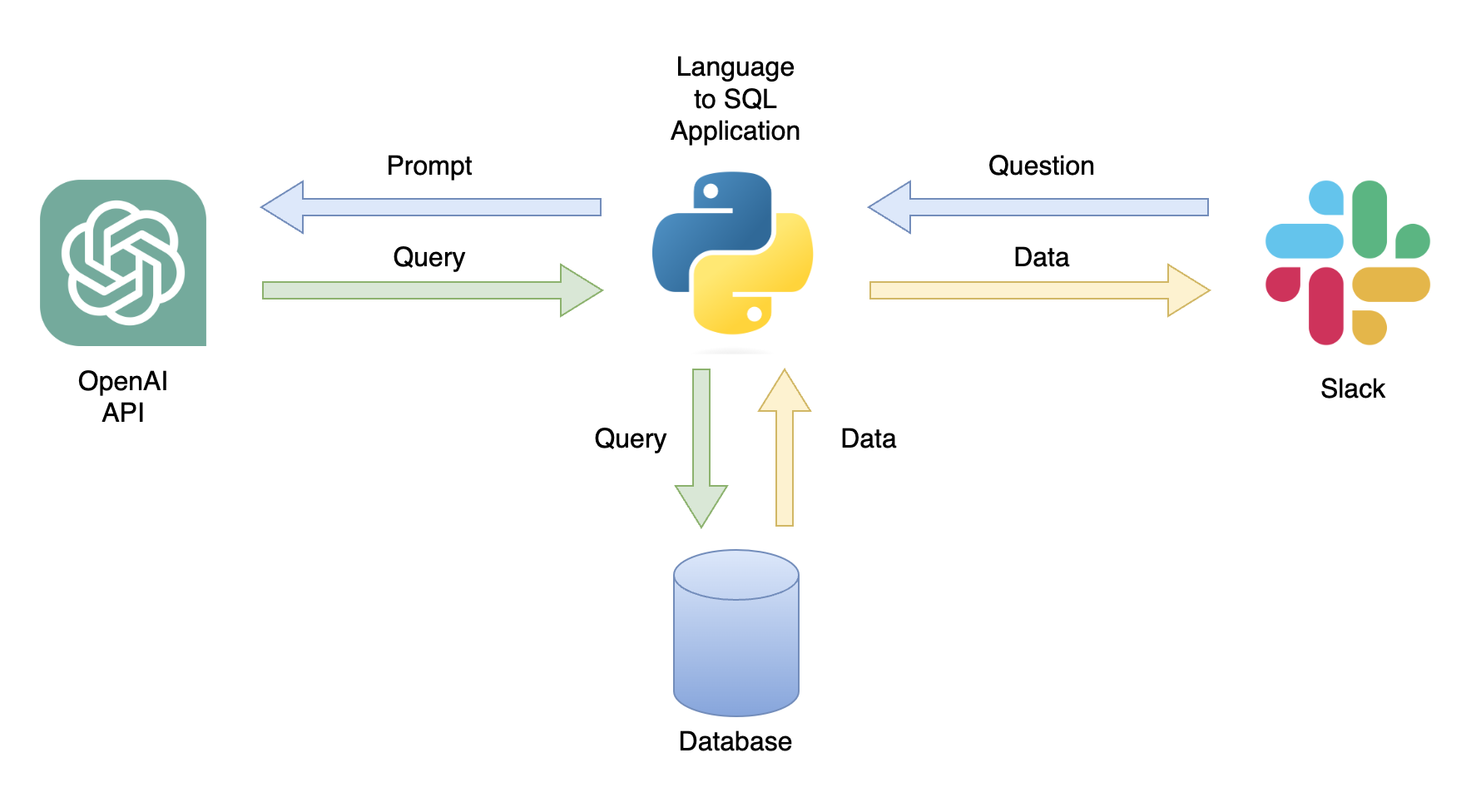
Dans ce tutoriel, nous créerons une application Python étape par étape qui convertit les questions des utilisateurs en requêtes SQL.
Ce tutoriel fournit un guide étape par étape sur la façon de configurer une application Python qui convertit les questions générales en requêtes SQL à l'aide de l'API OpenAI. Cela inclut les fonctionnalités suivantes:
La figure 2 ci-dessous décrit l'architecture générale d'une langue simple au générateur de code SQL.
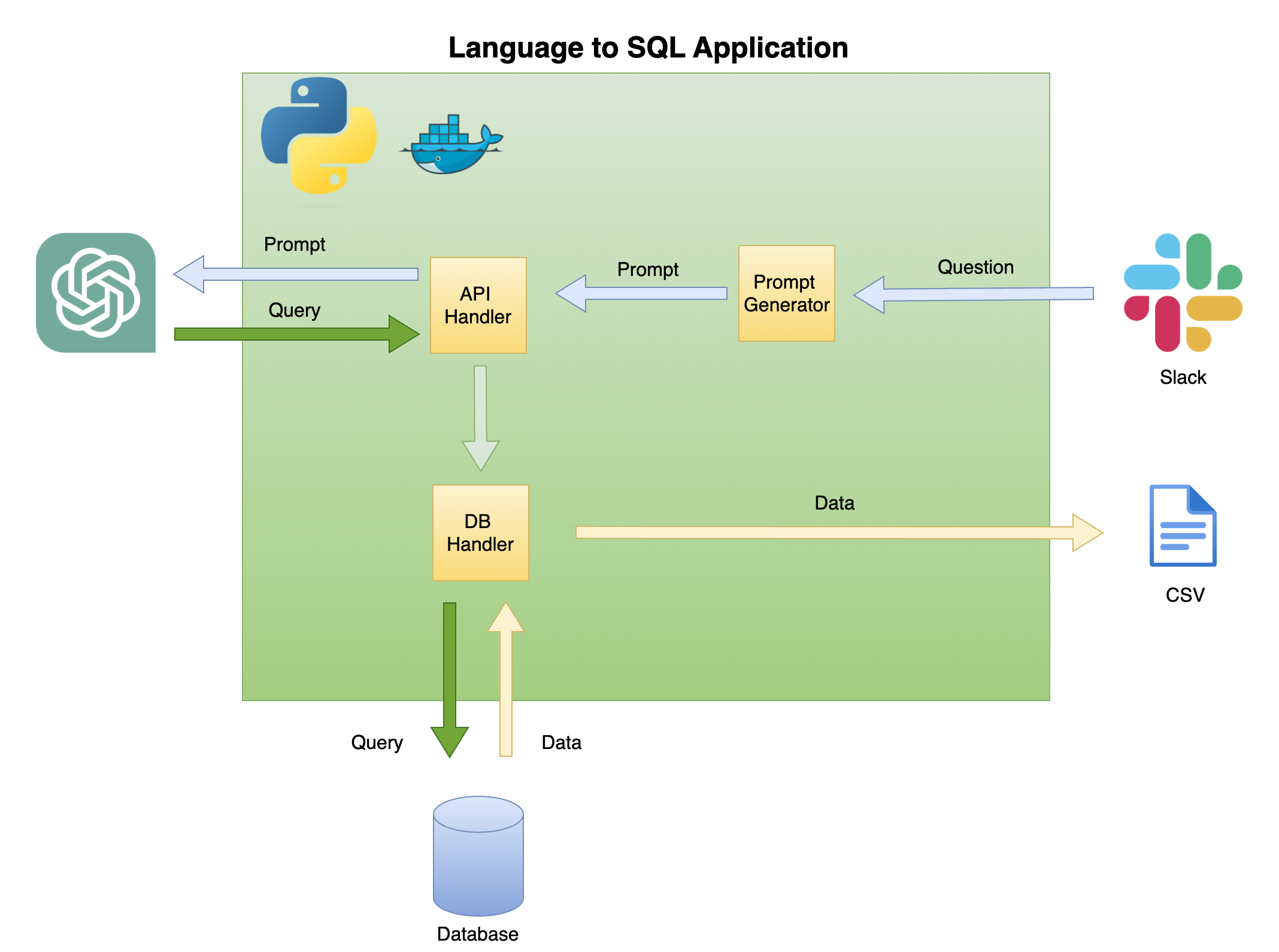
La portée et la focalisation de ce tutoriel se trouvent sur la boîte verte - construire la fonctionnalité suivante:
Question pour inviter - transformer la question en un format rapide:
Handler de l'API - Une fonction qui fonctionne avec l'API OpenAI:
DB Handler - Une fonction qui envoie la requête SQL à la base de données et renvoie les données requises
La principale condition préalable de ce tutoriel est la connaissance de base de Python. Cela inclut les fonctionnalités suivantes:
De plus, les connaissances de base de SQL et l'accès à l'API OpenAI sont nécessaires.
Bien que cela ne soit pas nécessaire, avoir une connaissance de base de Docker est utile, car le tutoriel a été créé dans un environnement dockerisé à l'aide de l'extension Dev Conteneurs de VScode. Si vous n'avez pas d'expérience avec Docker ou l'extension, vous pouvez toujours exécuter le tutoriel en créant un environnement virtuel et en installant les bibliothèques requises (comme décrit ci-dessous). La connaissance de l'ingénierie rapide et de l'API OpenAI est également bénéfique.
J'ai créé un tutoriel détaillé sur la définition d'un environnement dockerisé Python avec VSCODE et l'extension des conteneurs Dev:
https://github.com/ramikrispin/vscode-python
Pour configurer un langage naturel à la génération de code SQL, nous utiliserons les bibliothèques Python suivantes:
pandas - pour traiter les données tout au long du processusduckdb - Pour simuler le travail avec la base de donnéesopenai - pour travailler avec l'API OpenAItime et os - Charger les fichiers CSV et les champs de formatCe référentiel contient les paramètres nécessaires pour lancer un environnement dockerisé avec les exigences du didacticiel dans VScode et l'extension des conteneurs Dev. Plus de détails sont disponibles dans la section suivante.
Alternativement, vous pouvez configurer un environnement virtuel et installer les exigences du tutoriel en suivant les instructions ci-dessous en utilisant les instructions dans la section Environnement virtuel.
Ce didacticiel a été construit dans un environnement dockerisé avec VSCODE et l'extension des conteneurs Dev. Pour l'exécuter avec VSCODE, vous devrez installer l'extension des conteneurs Dev et demander à Docker Desktop (ou équivalent) ouverte. Les paramètres de l'environnement sont disponibles dans le dossier .devcontainer :
.── .devcontainer
├── Dockerfile
├── Dockerfile.dev
├── devcontainer.json
├── install_dependencies_core.sh
├── install_dependencies_other.sh
├── install_quarto.sh
├── requirements_core.txt
├── requirements_openai.txt
└── requirements_transformers.txt
Le devcontainer.json a les instructions de construction et les paramètres VScode pour cet environnement docking:
{
"name" : " lang2sql " ,
"build" : {
"dockerfile" : " Dockerfile " ,
"args" : {
"ENV_NAME" : " lang2sql " ,
"PYTHON_VER" : " 3.10 " ,
"METHOD" : " openai " ,
"QUARTO_VER" : " 1.3.450 "
},
"context" : " . "
},
"customizations" : {
"settings" : {
"python.defaultInterpreterPath" : " /opt/conda/envs/lang2sql/bin/python " ,
"python.selectInterpreter" : " /opt/conda/envs/lang2sql/bin/python "
},
"vscode" : {
"extensions" : [
" quarto.quarto " ,
" ms-azuretools.vscode-docker " ,
" ms-python.python " ,
" ms-vscode-remote.remote-containers " ,
" yzhang.markdown-all-in-one " ,
" redhat.vscode-yaml " ,
" ms-toolsai.jupyter "
]
}
},
"remoteEnv" : {
"OPENAI_KEY" : " ${localEnv:OPENAI_KEY} "
}
}
Où l'argument build définit la méthode docker build et définit les arguments pour la construction. Dans ce cas, nous définissons la version Python sur 3.10 et l'environnement virtuel Conda sur ang2sql . L'argument METHOD définit le type d'environnement - soit openai pour installer les bibliothèques Requirements pour ce didacticiel en utilisant l'API OpenAI ou transformers pour définir l'environnement pour HuggingFaces API (qui est hors de portée pour ce didacticiel).
L'argument remoteEnv permet de définir des variables d'environnement. Nous l'utiliserons pour définir la touche API OpenAI. Dans ce cas, je définis la variable localement sous le nom OPENAI_KEY , et je le charge en utilisant l'argument localEnv .
Si vous souhaitez en savoir plus sur la configuration d'un environnement de développement Python avec VScode et Docker, consultez ce tutoriel.
Si vous n'utilisez pas l'environnement Docking Tutorial, vous pouvez créer un environnement virtuel local à partir de la ligne de commande à l'aide du script ci-dessous:
ENV_NAME=openai_api
PYTHON_VER=3.10
conda create -y --name $ENV_NAME python= $PYTHON_VER
conda activate $ENV_NAME
pip3 install -r ./.devcontainer/requirements_core.txt
pip3 install -r ./.devcontainer/requirements_openai.txt
Remarque: j'ai utilisé conda et cela devrait également fonctionner avec toute autre méthode d'environnement virutal.
Nous utilisons les variables ENV_NAME et PYTHON_VER pour définir respectivement l'environnement virtuel et la version Python.
Pour confirmer que votre environnement est correctement défini, utilisez la conda list pour confirmer que les bibliothèques Python requises sont installées. Vous devez vous attendre à la sortie ci-dessous:
(openai_api) root@0ca5b8000cd5:/workspaces/lang2sql# conda list
# packages in environment at /opt/conda/envs/openai_api:
#
# Name Version Build Channel
_libgcc_mutex 0.1 main
_openmp_mutex 5.1 51_gnu
aiohttp 3.9.0 pypi_0 pypi
aiosignal 1.3.1 pypi_0 pypi
asttokens 2.4.1 pypi_0 pypi
async-timeout 4.0.3 pypi_0 pypi
attrs 23.1.0 pypi_0 pypi
bzip2 1.0.8 hfd63f10_2
ca-certificates 2023.08.22 hd43f75c_0
certifi 2023.11.17 pypi_0 pypi
charset-normalizer 3.3.2 pypi_0 pypi
comm 0.2.0 pypi_0 pypi
contourpy 1.2.0 pypi_0 pypi
cycler 0.12.1 pypi_0 pypi
debugpy 1.8.0 pypi_0 pypi
decorator 5.1.1 pypi_0 pypi
duckdb 0.9.2 pypi_0 pypi
exceptiongroup 1.2.0 pypi_0 pypi
executing 2.0.1 pypi_0 pypi
fonttools 4.45.1 pypi_0 pypi
frozenlist 1.4.0 pypi_0 pypi
gensim 4.3.2 pypi_0 pypi
idna 3.5 pypi_0 pypi
ipykernel 6.26.0 pypi_0 pypi
ipython 8.18.0 pypi_0 pypi
jedi 0.19.1 pypi_0 pypi
joblib 1.3.2 pypi_0 pypi
jupyter-client 8.6.0 pypi_0 pypi
jupyter-core 5.5.0 pypi_0 pypi
kiwisolver 1.4.5 pypi_0 pypi
ld_impl_linux-aarch64 2.38 h8131f2d_1
libffi 3.4.4 h419075a_0
libgcc-ng 11.2.0 h1234567_1
libgomp 11.2.0 h1234567_1
libstdcxx-ng 11.2.0 h1234567_1
libuuid 1.41.5 h998d150_0
matplotlib 3.8.2 pypi_0 pypi
matplotlib-inline 0.1.6 pypi_0 pypi
multidict 6.0.4 pypi_0 pypi
ncurses 6.4 h419075a_0
nest-asyncio 1.5.8 pypi_0 pypi
numpy 1.26.2 pypi_0 pypi
openai 0.28.1 pypi_0 pypi
openssl 3.0.12 h2f4d8fa_0
packaging 23.2 pypi_0 pypi
pandas 2.0.0 pypi_0 pypi
parso 0.8.3 pypi_0 pypi
pexpect 4.8.0 pypi_0 pypi
pillow 10.1.0 pypi_0 pypi
pip 23.3.1 py310hd43f75c_0
platformdirs 4.0.0 pypi_0 pypi
prompt-toolkit 3.0.41 pypi_0 pypi
psutil 5.9.6 pypi_0 pypi
ptyprocess 0.7.0 pypi_0 pypi
pure-eval 0.2.2 pypi_0 pypi
pygments 2.17.2 pypi_0 pypi
pyparsing 3.1.1 pypi_0 pypi
python 3.10.13 h4bb2201_0
python-dateutil 2.8.2 pypi_0 pypi
pytz 2023.3.post1 pypi_0 pypi
pyzmq 25.1.1 pypi_0 pypi
readline 8.2 h998d150_0
requests 2.31.0 pypi_0 pypi
scikit-learn 1.3.2 pypi_0 pypi
scipy 1.11.4 pypi_0 pypi
setuptools 68.0.0 py310hd43f75c_0
six 1.16.0 pypi_0 pypi
smart-open 6.4.0 pypi_0 pypi
sqlite 3.41.2 h998d150_0
stack-data 0.6.3 pypi_0 pypi
threadpoolctl 3.2.0 pypi_0 pypi
tk 8.6.12 h241ca14_0
tornado 6.3.3 pypi_0 pypi
tqdm 4.66.1 pypi_0 pypi
traitlets 5.13.0 pypi_0 pypi
tzdata 2023.3 pypi_0 pypi
urllib3 2.1.0 pypi_0 pypi
wcwidth 0.2.12 pypi_0 pypi
wheel 0.41.2 py310hd43f75c_0
xz 5.4.2 h998d150_0
yarl 1.9.3 pypi_0 pypi
zlib 1.2.13 h998d150_0
Nous utiliserons l'API OpenAI pour accéder à Chatgpt à l'aide du moteur text-davinci-003. Cela nécessitait un compte OpenAI actif et une clé API. Il est simple de définir un compte et une clé API suivant les instructions dans le lien ci-dessous:
https://openai.com/product
Une fois que vous avez défini l'accès à l'API et à une clé, je vous recommande d'ajouter la clé en tant que variable d'environnement à votre fichier .zshrc (ou tout autre format que vous utilisez pour stocker des variables d'environnement sur votre système de shell). J'ai stocké ma clé API sous la variable d'environnement OPENAI_KEY . Pour des raisons convaincantes, je vous recommande d'utiliser la même convention de dénomination.
Pour définir la variable sur le fichier .zshrc (ou équivalent), ajoutez la ligne ci-dessous au fichier:
export OPENAI_KEY= " YOUR_API_KEY " Si vous utilisez VScode ou en exécutant à partir du terminal, vous devez redémarrer votre session après avoir ajouté la variable au fichier .zshrc .
Afin de simuler la fonctionnalité de la base de données, nous utiliserons l'ensemble de données de Chicago Crime. Cet ensemble de données fournit des informations détaillées concernant les crimes enregistrés dans la ville de Chicago depuis 2001. Avec près de 8 millions d'enregistrements et 22 colonnes, l'ensemble de données comprend des informations telles que la classification du crime, l'emplacement, le temps, le résultat, etc. Les données sont disponibles en téléchargement à partir du portail de données de Chicago. Étant donné que nous stockons les données localement sous forme de trame de données Pandas et utilisons DuckDB pour simuler la requête SQL, nous téléchargerons un sous-ensemble des données en utilisant les trois dernières années.
Vous pouvez extraire les données de l'API ou télécharger un fichier CSV. Pour éviter d'appeler l'API à chaque fois que j'exécute le script, je télécharge les fichiers et les stocke sous le dossier de données. Vous trouverez ci-dessous les liens vers les ensembles de données par année:
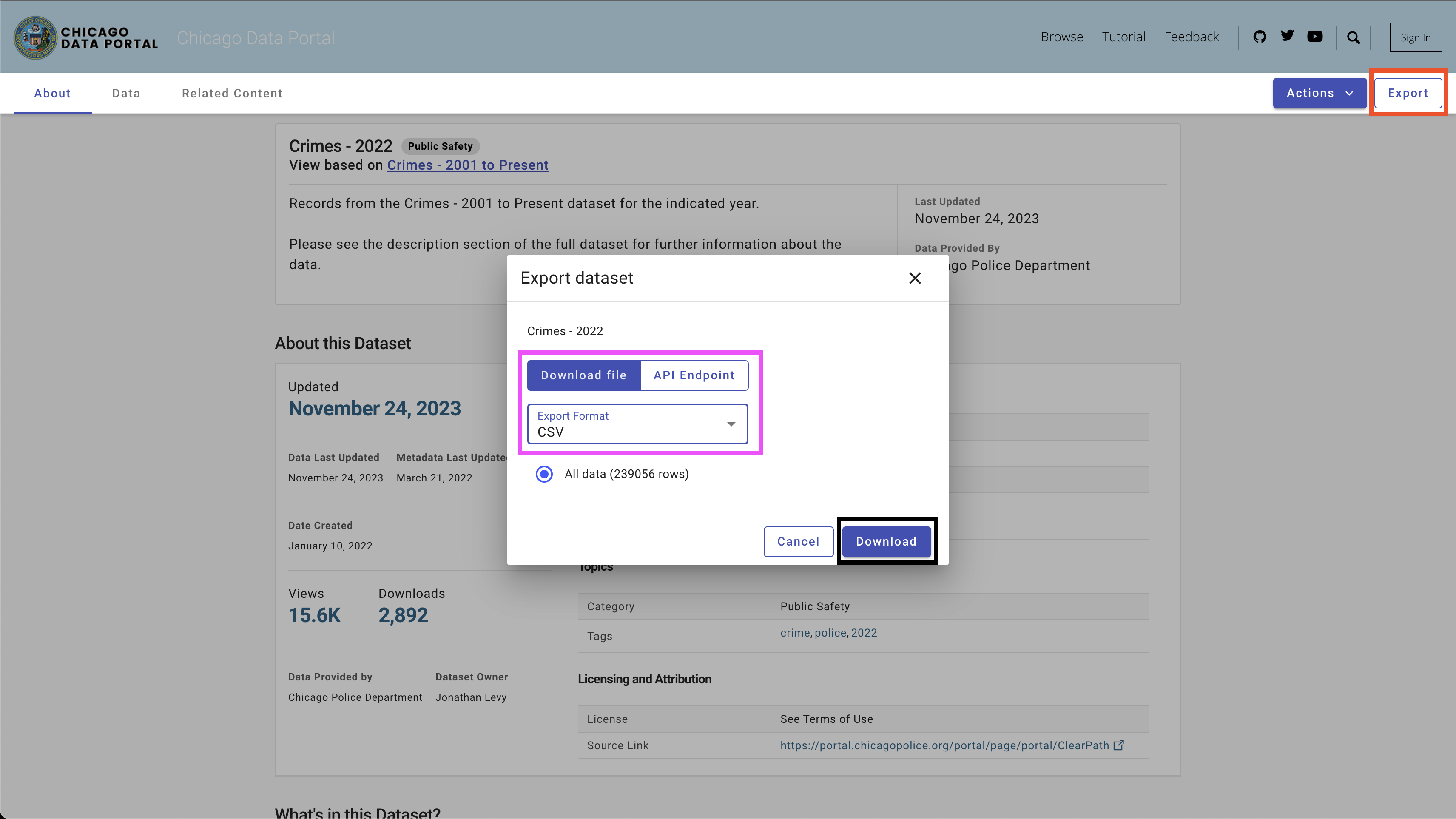
Pour télécharger les données, utilisez le bouton Export en haut à droite, sélectionnez l'option CSV et cliquez sur le bouton Download , comme le montre la figure 4.
J'ai utilisé la convention de dénomination suivante - Chicago_crime_year.csv et enregistré les fichiers dans le dossier data . Chaque taille de fichier est proche de 50 Mo. Par conséquent, je les ai ajoutés au fichier Git Ignore dans le dossier data , et ils ne sont pas disponibles sur ce dépôt. Après avoir téléchargé les fichiers et réglé leurs noms, vous devriez avoir les fichiers suivants dans le dossier:
| ── data
├── chicago_crime_2021.csv
├── chicago_crime_2022.csv
└── chicago_crime_2023.csv
Remarque: Au moment de la création de ce tutoriel, les données de 2023 sont toujours mises à jour. Par conséquent, vous pouvez recevoir des résultats légèrement différents lors de l'exécution de certaines des requêtes dans la section suivante.
Passons à la partie passionnante, qui configure un générateur de code SQL. Dans cette section, nous créerons une fonction Python qui prend la question d'un utilisateur, la table SQL associée et la clé API OpenAI et publie la requête SQL qui répond à la question de l'utilisateur.
Commençons par charger l'ensemble de données sur le crime de Chicago et les bibliothèques Python requises.
Première chose d'abord - Chargez les bibliothèques Python requises:
import pandas as pd
import duckdb
import openai
import time
import osNous utiliserons le système d'exploitation et les bibliothèques temporelles pour charger les fichiers CSV et reformater certains champs. Les données seront traitées à l'aide de la bibliothèque Pandas , et nous simulerons les commandes SQL avec la bibliothèque DuckDB . Enfin, nous établirons une connexion à l'API OpenAI à l'aide de la bibliothèque OpenAI .
Ensuite, nous chargerons les fichiers CSV à partir du dossier de données. Le code ci-dessous lit tous les fichiers CSV disponibles dans le dossier de données:
path = "./data"
files = [ x for x in os . listdir ( path = path ) if ".csv" in x ]Si vous avez téléchargé les fichiers correspondants pour les années 2021 à 2023 et utilisé la même convention de dénomination, vous devez vous attendre à la sortie suivante:
print ( files )
[ 'chicago_crime_2022.csv' , 'chicago_crime_2023.csv' , 'chicago_crime_2021.csv' ]Ensuite, nous lirons et chargerons tous les fichiers et les ajouterons dans une trame de données Pandas:
chicago_crime = pd . concat (( pd . read_csv ( path + "/" + f ) for f in files ), ignore_index = True )
chicago_crime . headSi vous avez chargé les fichiers correctement, vous devez vous attendre à la sortie suivante:
< bound method NDFrame . head of ID Case Number Date Block
0 12589893 JF109865 01 / 11 / 2022 03 : 00 : 00 PM 087 XX S KINGSTON AVE
1 12592454 JF113025 01 / 14 / 2022 03 : 55 : 00 PM 067 XX S MORGAN ST
2 12601676 JF124024 01 / 13 / 2022 04 : 00 : 00 PM 031 XX W AUGUSTA BLVD
3 12785595 JF346553 08 / 05 / 2022 09 : 00 : 00 PM 072 XX S UNIVERSITY AVE
4 12808281 JF373517 08 / 14 / 2022 02 : 00 : 00 PM 055 XX W ARDMORE AVE
... ... ... ... ...
648826 26461 JE455267 11 / 24 / 2021 12 : 51 : 00 AM 107 XX S LANGLEY AVE
648827 26041 JE281927 06 / 28 / 2021 01 : 12 : 00 AM 117 XX S LAFLIN ST
648828 26238 JE353715 08 / 29 / 2021 03 : 07 : 00 AM 010 XX N LAWNDALE AVE
648829 26479 JE465230 12 / 03 / 2021 08 : 37 : 00 PM 000 XX W 78 TH PL
648830 11138622 JA495186 05 / 21 / 2021 12 : 01 : 00 AM 019 XX N PULASKI RD
IUCR Primary Type
0 1565 SEX OFFENSE
1 2826 OTHER OFFENSE
2 1752 OFFENSE INVOLVING CHILDREN
3 1544 SEX OFFENSE
4 1562 SEX OFFENSE
... ... ...
648826 0110 HOMICIDE
648827 0110 HOMICIDE
648828 0110 HOMICIDE
648829 0110 HOMICIDE
648830 1752 OFFENSE INVOLVING CHILDREN
...
648828 41.899709 - 87.718893 ( 41.899709327 , - 87.718893208 )
648829 41.751832 - 87.626374 ( 41.751831742 , - 87.626373808 )
648830 41.915798 - 87.726524 ( 41.915798196 , - 87.726524412 ) Remarque: Lors de la création de ce tutoriel, des données partielles pour 2023 étaient disponibles. L'ajouter les trois fichiers entraînerait plus de lignes que celles indiquées (648830 lignes).
Avant d'entrer dans le code Python, arrêtons et passons en revue le fonctionnement de l'ingénierie rapide et comment nous pouvons aider Chatgpt (et généralement tout LLM) générer les meilleurs résultats. Nous utiliserons dans cette section l'interface Web Chatgpt.
Un facteur majeur dans les modèles d'apprentissage statistique et machine est que la qualité de sortie dépend de la qualité d'entrée. Comme le dit la célèbre phrase - Jounk-in, Junk-out . De même, la qualité de la sortie LLM dépend de la qualité de l'invite.
Par exemple, supposons que nous voulons compter le nombre de cas qui se sont retrouvés avec une arrestation.
Si nous utilisons l'invite suivante:
Create an SQL query that counts the number of records that ended up with an arrest.
Voici la sortie de Chatgpt:
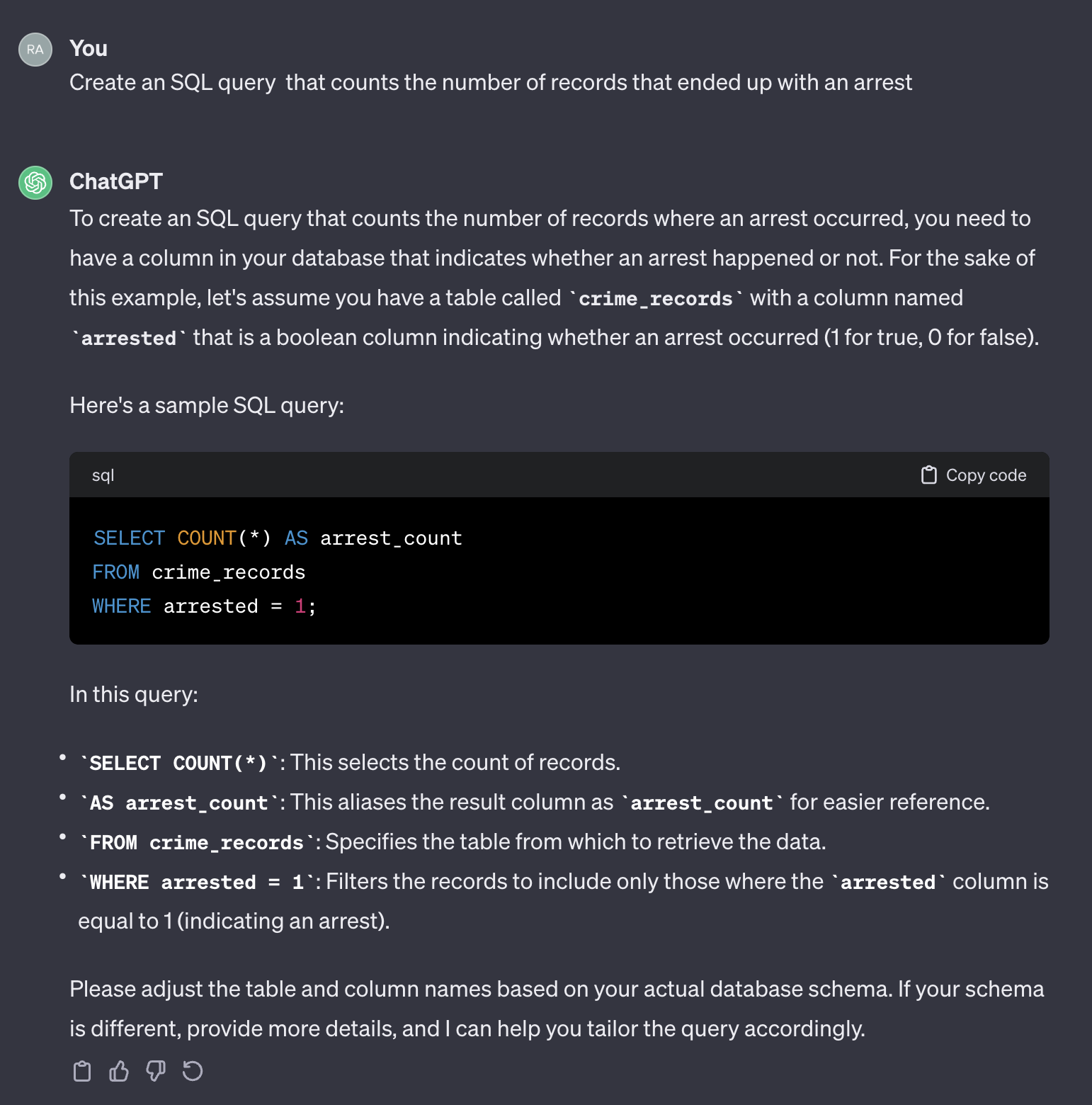
Il convient de noter que Chatgpt fournit une réponse générique. Bien qu'il soit généralement correct, il peut ne pas être pratique à utiliser dans un processus automatisé. Premièrement, les noms de champ dans la réponse ne correspondent pas à ceux du tableau réel que nous devons interroger. Deuxièmement, le champ qui représente le résultat d'arrestation est un booléen ( true ou false ) au lieu d'un entier ( 0 ou 1 ).
Chatgpt, en ce sens, agit comme un humain. Il est peu probable que vous receviez une réponse plus précise d'un humain en publiant la même question sur un formulaire de codage comme Stack Overflow ou toute autre plate-forme similaire. Étant donné que nous n'avons fourni aucun contexte ou information supplémentaire sur les caractéristiques du tableau, nous attendons à ce que Chatgpt devine que les noms de champ et leurs valeurs seraient déraisonnables. Le contexte est un facteur crucial dans toute invite. Pour illustrer ce point, voyons comment Chatgpt gère l'invite suivante:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
I want to create an SQL query that counts the number of records that ended up with an arrest.
Voici la sortie de Chatgpt:
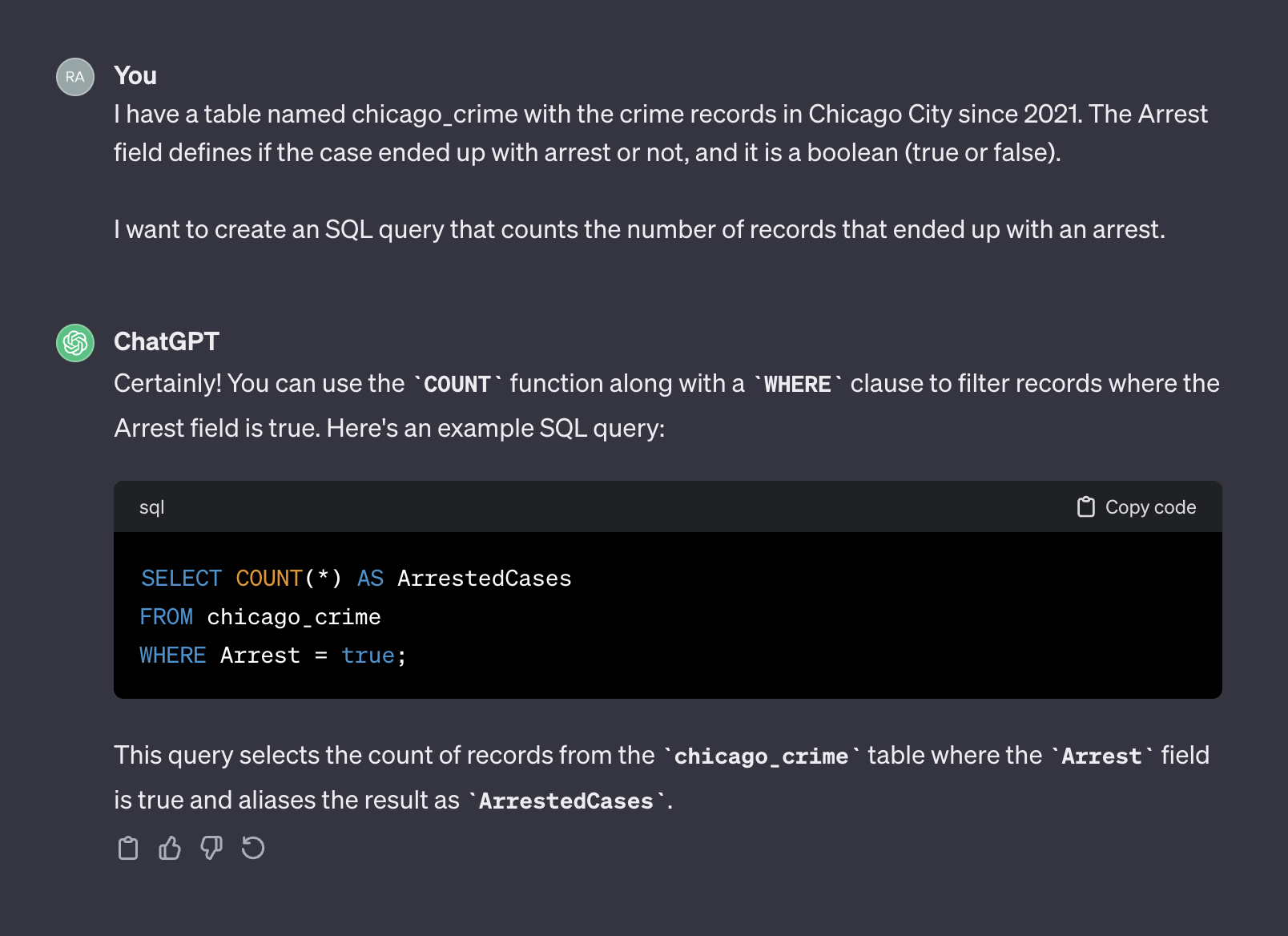
Cette fois, après avoir ajouté un contexte, ChatGpt a renvoyé une requête correcte que nous pouvons utiliser telle quel. Généralement, lorsque vous travaillez avec un générateur de texte, l'invite doit inclure deux composantes - contexte et demande. Dans l'invite ci-dessus, le premier paragraphe représente le contexte de l'invite:
I have a table named chicago_crime with the crime records in Chicago City since 2021. The Arrest field defines if the case ended up with arrest or not, and it is a boolean (true or false).
Où le deuxième paragraphe représente la demande:
I want to create an SQL query that counts the number of records that ended up with an arrest.
L'API OpenAI fait référence au contexte en tant que system et demande en tant user .
La documentation de l'API OpenAI fournit une recommandation pour définir le system et les composants user dans une invite lorsque vous demandez à générer un code SQL:
System
Given the following SQL tables, your job is to write queries given a user’s request.
CREATE TABLE Orders (
OrderID int,
CustomerID int,
OrderDate datetime,
OrderTime varchar(8),
PRIMARY KEY (OrderID)
);
CREATE TABLE OrderDetails (
OrderDetailID int,
OrderID int,
ProductID int,
Quantity int,
PRIMARY KEY (OrderDetailID)
);
CREATE TABLE Products (
ProductID int,
ProductName varchar(50),
Category varchar(50),
UnitPrice decimal(10, 2),
Stock int,
PRIMARY KEY (ProductID)
);
CREATE TABLE Customers (
CustomerID int,
FirstName varchar(50),
LastName varchar(50),
Email varchar(100),
Phone varchar(20),
PRIMARY KEY (CustomerID)
);
User
Write a SQL query which computes the average total order value for all orders on 2023-04-01.
Dans la section suivante, nous utiliserons l'exemple OpenAI ci-dessus et le généraliserons dans un modèle à usage général.
Dans la section précédente, nous avons discuté de l'importance de l'ingénierie rapide et de la façon dont la fourniture d'un bon contexte peut améliorer la précision de la réponse LLM. De plus, nous avons vu la structure rapide recommandée OpenAI pour la génération de code SQL. Dans cette section, nous nous concentrerons sur la généralisation du processus de création d'invites pour la génération SQL en fonction de ces principes. L'objectif est de construire une fonction Python qui reçoit un nom de table et une question utilisateur et crée l'invite en conséquence. Par exemple, pour la table chicago_crime Table que nous avons chargée auparavant et la question que nous avons posée dans la section précédente, la fonction doit créer l'invite ci-dessous:
Given the following SQL table, your job is to write queries given a user’s request.
CREATE TABLE chicago_crime (ID BIGINT, Case Number VARCHAR, Date VARCHAR, Block VARCHAR, IUCR VARCHAR, Primary Type VARCHAR, Description VARCHAR, Location Description VARCHAR, Arrest BOOLEAN, Domestic BOOLEAN, Beat BIGINT, District BIGINT, Ward DOUBLE, Community Area BIGINT, FBI Code VARCHAR, X Coordinate DOUBLE, Y Coordinate DOUBLE, Year BIGINT, Updated On VARCHAR, Latitude DOUBLE, Longitude DOUBLE, Location VARCHAR)
Write a SQL query that returns - How many cases ended up with arrest?
Commençons par la structure rapide. Nous adopterons le format OpenAI et utiliserons le modèle suivant:
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}" Où le system_template a reçu deux éléments:
Pour ce tutoriel, nous utiliserons la bibliothèque DuckDB pour gérer le cadre de données des Pandas car il s'agissait d'une table SQL et extraire les noms et attributs de champ de la table à l'aide de la fonction duckdb.sql . Par exemple, utilisons la commande SQL DESCRIBE pour extraire les informations sur les champs de table de chicago_crime :
duckdb . sql ( "DESCRIBE SELECT * FROM chicago_crime;" )Qui doit renvoyer le tableau ci-dessous:
┌──────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ ID │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Case Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Date │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Block │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ IUCR │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Primary Type │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Location Description │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Arrest │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Domestic │ BOOLEAN │ YES │ NULL │ NULL │ NULL │
│ Beat │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ District │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Ward │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Community Area │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ FBI Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ X Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Y Coordinate │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Year │ BIGINT │ YES │ NULL │ NULL │ NULL │
│ Updated On │ VARCHAR │ YES │ NULL │ NULL │ NULL │
│ Latitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Longitude │ DOUBLE │ YES │ NULL │ NULL │ NULL │
│ Location │ VARCHAR │ YES │ NULL │ NULL │ NULL │
├──────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┤
│ 22 rows 6 columns │
└────────────────────────────────────────────────────────────────────────────┘Remarque: les informations dont nous avons besoin - le nom de la colonne et son attribut sont disponibles sur les deux premières colonnes. Par conséquent, nous devrons analyser ces colonnes et les combiner au format suivant:
Column_Name Column_Attribute
Par exemple, la colonne Case Number doit être transféré dans le format suivant:
Case Number VARCHAR
La fonction create_message ci-dessous orchestre le processus de prise du nom du tableau et de la question et de la génération de l'invite en utilisant la logique ci-dessus:
def create_message ( table_name , query ):
class message :
def __init__ ( message , system , user , column_names , column_attr ):
message . system = system
message . user = user
message . column_names = column_names
message . column_attr = column_attr
system_template = """
Given the following SQL table, your job is to write queries given a user’s request. n
CREATE TABLE {} ({}) n
"""
user_template = "Write a SQL query that returns - {}"
tbl_describe = duckdb . sql ( "DESCRIBE SELECT * FROM " + table_name + ";" )
col_attr = tbl_describe . df ()[[ "column_name" , "column_type" ]]
col_attr [ "column_joint" ] = col_attr [ "column_name" ] + " " + col_attr [ "column_type" ]
col_names = str ( list ( col_attr [ "column_joint" ]. values )). replace ( '[' , '' ). replace ( ']' , '' ). replace ( ' ' ' , '' )
system = system_template . format ( table_name , col_names )
user = user_template . format ( query )
m = message ( system = system , user = user , column_names = col_attr [ "column_name" ], column_attr = col_attr [ "column_type" ])
return m La fonction crée le modèle d'invite et renvoie le system invite et les composants user et les noms et attributs des colonnes. Par exemple, exécutons le nombre de questions d'arrestation:
query = "How many cases ended up with arrest?"
msg = create_message ( table_name = "chicago_crime" , query = query )Cela reviendra:
print ( msg . system )
Given the following SQL table , your job is to write queries given a user ’ s request .
CREATE TABLE chicago_crime ( ID BIGINT , Case Number VARCHAR , Date VARCHAR , Block VARCHAR , IUCR VARCHAR , Primary Type VARCHAR , Description VARCHAR , Location Description VARCHAR , Arrest BOOLEAN , Domestic BOOLEAN , Beat BIGINT , District BIGINT , Ward DOUBLE , Community Area BIGINT , FBI Code VARCHAR , X Coordinate DOUBLE , Y Coordinate DOUBLE , Year BIGINT , Updated On VARCHAR , Latitude DOUBLE , Longitude DOUBLE , Location VARCHAR )
print ( msg . user )
Write a SQL query that returns - How many cases ended up with arrest ?
print ( msg . column_names )
0 ID
1 Case Number
2 Date
3 Block
4 IUCR
5 Primary Type
6 Description
7 Location Description
8 Arrest
9 Domestic
10 Beat
11 District
12 Ward
13 Community Area
14 FBI Code
15 X Coordinate
16 Y Coordinate
17 Year
18 Updated On
19 Latitude
20 Longitude
21 Location
Name : column_name , dtype : object
print ( msg . column_attr )
0 BIGINT
1 VARCHAR
2 VARCHAR
3 VARCHAR
4 VARCHAR
5 VARCHAR
6 VARCHAR
7 VARCHAR
8 BOOLEAN
9 BOOLEAN
10 BIGINT
11 BIGINT
12 DOUBLE
13 BIGINT
14 VARCHAR
15 DOUBLE
16 DOUBLE
17 BIGINT
18 VARCHAR
19 DOUBLE
20 DOUBLE
21 VARCHAR
Name : column_type , dtype : object La sortie de la fonction create_message a été conçue pour s'adapter à l'API OpenAI ChatCompletion.create Fonction Arguments, que nous examinerons dans la section suivante.
Cette section se concentre sur la fonctionnalité Openai Python Library. La bibliothèque OpenAI permet un accès transparent à l'API Openai REST. Nous utiliserons la bibliothèque pour nous connecter à l'API et envoyer des demandes GET avec notre invite.
Commençons par nous connecter à l'API en nourrissant notre API à la fonction openai.api_key :
openai . api_key = os . getenv ( 'OPENAI_KEY' ) Remarque: Nous avons utilisé la fonction getenv de la bibliothèque os pour charger la variable d'environnement OpenAI_KEY. Alternativement, vous pouvez nourrir directement votre clé API:
openai . api_key = "YOUR_OPENAI_API_KEY"L'API OpenAI donne accès à une variété de LLM avec différentes fonctionnalités. Vous pouvez utiliser la fonction openai.model.list pour obtenir une liste des modèles disponibles:
openai . Model . list () Pour le transformer en un bon format, vous pouvez l'envelopper dans un cadre de données pandas :
openai_api_models = pd . DataFrame ( openai . Model . list ()[ "data" ])
openai_api_models . headEt devrait s'attendre à la sortie suivante:
<bound method NDFrame.head of id object created owned_by
0 text-search-babbage-doc-001 model 1651172509 openai-dev
1 gpt-4 model 1687882411 openai
2 curie-search-query model 1651172509 openai-dev
3 text-davinci-003 model 1669599635 openai-internal
4 text-search-babbage-query-001 model 1651172509 openai-dev
.. ... ... ... ...
65 gpt-3.5-turbo-instruct-0914 model 1694122472 system
66 dall-e-2 model 1698798177 system
67 tts-1-1106 model 1699053241 system
68 tts-1-hd-1106 model 1699053533 system
69 gpt-3.5-turbo-16k model 1683758102 openai-internal
[70 rows x 4 columns]>
Pour notre cas d'utilisation, la génération de texte, nous utiliserons le modèle gpt-3.5-turbo , qui est une amélioration du modèle GPT3. Le modèle gpt-3.5-turbo représente une série de modèles qui continuent de se mettre à jour, et par défaut, si la version du modèle n'est pas spécifiée, l'API indiquera la version stable la plus récente. Lors de la création de ce didacticiel, le modèle 3.5 par défaut était gpt-3.5-turbo-0613 , en utilisant 4 096 jetons, et formé avec des données jusqu'en septembre 2021.
Pour envoyer une demande GET avec notre invite, nous utiliserons la fonction ChatCompletion.create . La fonction a de nombreux arguments et nous utiliserons les suivants:
model - L'ID du modèle à utiliser, une liste complète disponible icimessages - Une liste de messages comprenant la conversation jusqu'à présent (par exemple, l'invite)temperature - Gérez le hasard ou le déterminisme de la sortie du processus en réglant le niveau de température d'échantillonnage. Le niveau de température accepte des valeurs entre 0 et 2. Lorsque la valeur de l'argument est plus élevée, la sortie devient plus aléatoire. Inversement, lorsque la valeur de l'argument est plus proche de 0, la sortie devient plus déterministe (reproductible)max_tokens - Le nombre maximum de jetons à générer dans l'achèvementLa liste complète des arguments de fonction disponibles sur l'API Documentaiton.
Dans l'exemple ci-dessous, nous utiliserons la même invite que celle utilisée sur l'interface Web ChatGPT (c'est-à-dire la figure 5), cette fois en utilisant l'API. Nous générerons l'invite avec la fonction create_message :
query = "How many cases ended up with arrest?"
prompt = create_message ( table_name = "chicago_crime" , query = query ) Transformons l'invite ci-dessus en la structure de l'argument ChatCompletion.create Fonction messages :
message = [
{
"role" : "system" ,
"content" : prompt . system
},
{
"role" : "user" ,
"content" : prompt . user
}
] Ensuite, nous enverrons l'invite (c'est-à-dire l'objet message ) à l'API à l'aide de la fonction ChatCompletion.create :
response = openai . ChatCompletion . create (
model = "gpt-3.5-turbo" ,
messages = message ,
temperature = 0 ,
max_tokens = 256 ) Nous réglerons l'argument temperature sur 0 pour assurer une reproductibilité élevée et limiter le nombre de jetons dans l'achèvement du texte sur 256. La fonction renvoie un objet JSON avec l'achèvement du texte, les métadonnées et autres informations:
print ( response )
< OpenAIObject chat . completion id = chatcmpl - 8 PzomlbLrTOTx1uOZm4WQnGr4JwU7 at 0xffff4b0dcb80 > JSON : {
"id" : "chatcmpl-8PzomlbLrTOTx1uOZm4WQnGr4JwU7" ,
"object" : "chat.completion" ,
"created" : 1701206520 ,
"model" : "gpt-3.5-turbo-0613" ,
"choices" : [
{
"index" : 0 ,
"message" : {
"role" : "assistant" ,
"content" : "SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true;"
},
"finish_reason" : "stop"
}
],
"usage" : {
"prompt_tokens" : 137 ,
"completion_tokens" : 12 ,
"total_tokens" : 149
}
}En utilisant les Indes de réponse, nous pouvons extraire la requête SQL:
sql = response [ "choices" ][ 0 ][ "message" ][ "content" ]
print ( sql ) ' SELECT COUNT(*) FROM chicago_crime WHERE Arrest = true; ' Utilisation de la fonction duckdb.sql pour exécuter le code SQL:
duckdb . sql ( sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Dans la section suivante, nous généraliserons et fonctionnerons toutes les étapes.
Dans les sections précédentes, nous avons introduit le format d'invite, défini la fonction create_message et examiné la fonctionnalité de la fonction ChatCompletion.create . Dans cette section, nous nous coutures tous ensemble.
Une chose à noter sur le code SQL renvoyé de la fonction ChatCompletion.create est que la variable ne revient pas avec des devis. Cela pourrait être un problème lorsque le nom de variable de la requête combine deux mots ou plus. Par exemple, l'utilisation d'une variable telle que Case Number ou Primary Type de chicago_crime à l'intérieur d'une requête sans utiliser de devis entraînera une erreur.
Nous utiliserons la fonction d'assistance ci-dessous pour ajouter des devis aux variables de la requête si la requête retournée n'en a pas:
def add_quotes ( query , col_names ):
for i in col_names :
if i in query :
l = query . find ( i )
if query [ l - 1 ] != "'" and query [ l - 1 ] != '"' :
query = str ( query ). replace ( i , '"' + i + '"' )
return ( query ) Les entrées de fonction sont la requête et les noms de colonne de la table correspondante. Il boucle sur les noms de colonne et ajoute des citations s'il trouve une correspondance dans la requête. Par exemple, nous pouvons l'exécuter avec la requête SQL que nous avons analysée à partir de la sortie de fonction ChatCompletion.create :
add_quotes ( query = sql , col_names = prompt . column_names )
'SELECT COUNT(*) FROM chicago_crime WHERE "Arrest" = true;' Vous pouvez remarquer qu'il a ajouté des devis à la variable Arrest .
Nous pouvons maintenant introduire la fonction lang2sql qui tire parti des trois fonctions que nous avons introduites jusqu'à présent - create_message , ChatCompletion.create et add_quotes pour traduire une question utilisateur en un code SQL:
def lang2sql ( api_key , table_name , query , model = "gpt-3.5-turbo" , temperature = 0 , max_tokens = 256 , frequency_penalty = 0 , presence_penalty = 0 ):
class response :
def __init__ ( output , message , response , sql ):
output . message = message
output . response = response
output . sql = sql
openai . api_key = api_key
m = create_message ( table_name = table_name , query = query )
message = [
{
"role" : "system" ,
"content" : m . system
},
{
"role" : "user" ,
"content" : m . user
}
]
openai_response = openai . ChatCompletion . create (
model = model ,
messages = message ,
temperature = temperature ,
max_tokens = max_tokens ,
frequency_penalty = frequency_penalty ,
presence_penalty = presence_penalty )
sql_query = add_quotes ( query = openai_response [ "choices" ][ 0 ][ "message" ][ "content" ], col_names = m . column_names )
output = response ( message = m , response = openai_response , sql = sql_query )
return output La fonction reçoit, comme entrées, la clé API OpenAI, le nom de la table et les paramètres de base de la fonction ChatCompletion.create et renvoie un objet avec l'invite, la réponse de l'API et la requête analysée. Par exemple, essayons de réécrire la même requête que nous avons utilisée dans la section précédente avec la fonction lang2sql :
query = "How many cases ended up with arrest?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )Nous pouvons extraire la requête SQL de l'objet de sortie:
print ( response . sql ) SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = true;Nous pouvons tester la sortie par rapport aux résultats que nous avons reçus dans la section précédente:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 77635 │
└──────────────┘Ajoutons maintenant une complexité supplémentaire à la question et demandons des cas qui se sont retrouvés avec une arrestation en 2022:
query = "How many cases ended up with arrest during 2022"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query ) Comme vous pouvez le voir, le modèle a correctement identifié le champ pertinent comme Year et a généré la bonne requête:
print ( response . sql )Le code SQL:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Arrest " = TRUE AND " Year " = 2022 ;Test de la requête dans le tableau:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 27805 │
└──────────────┘Voici un exemple d'une question simple qui nécessitait un regroupement par une variable spécifique:
query = "Summarize the cases by primary type"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Vous pouvez voir à partir de la sortie de réponse que le code SQL dans ce cas est correct:
SELECT " Primary Type " , COUNT ( * ) as TotalCases
FROM chicago_crime
GROUP BY " Primary Type "Ceci est la sortie de la requête:
duckdb . sql ( response . sql ). show ()
┌───────────────────────────────────┬────────────┐
│ Primary Type │ TotalCases │
│ varchar │ int64 │
├───────────────────────────────────┼────────────┤
│ MOTOR VEHICLE THEFT │ 54934 │
│ ROBBERY │ 25082 │
│ WEAPONS VIOLATION │ 24672 │
│ INTERFERENCE WITH PUBLIC OFFICER │ 1161 │
│ OBSCENITY │ 127 │
│ STALKING │ 1206 │
│ BATTERY │ 115760 │
│ OFFENSE INVOLVING CHILDREN │ 5177 │
│ CRIMINAL TRESPASS │ 11255 │
│ PUBLIC PEACE VIOLATION │ 1980 │
│ · │ · │
│ · │ · │
│ · │ · │
│ ASSAULT │ 58685 │
│ CRIMINAL DAMAGE │ 75611 │
│ DECEPTIVE PRACTICE │ 46377 │
│ NARCOTICS │ 13931 │
│ BURGLARY │ 19898 │
...
├───────────────────────────────────┴────────────┤
│ 31 rows ( 20 shown ) 2 columns │
└────────────────────────────────────────────────┘Enfin et surtout, le LLM peut identifier le contexte (par exemple, quelle variable) même lorsque nous fournissons un nom de variable partiel:
query = "How many cases is the type of robbery?"
response = lang2sql ( api_key = api_key , table_name = "chicago_crime" , query = query )
print ( response . sql )Il renvoie le code SQL ci-dessous:
SELECT COUNT ( * ) FROM chicago_crime WHERE " Primary Type " = ' ROBBERY ' ;Ceci est la sortie de la requête:
duckdb . sql ( response . sql ). show ()
┌──────────────┐
│ count_star () │
│ int64 │
├──────────────┤
│ 25082 │
└──────────────┘Dans ce tutoriel, nous avons démontré comment créer un générateur de code SQL avec quelques lignes de code Python et utiliser l'API OpenAI. Nous avons vu que la qualité de l'invite est cruciale pour le succès du code SQL résultant. En plus du contexte fourni par l'invite, les noms de champ doivent également fournir des informations sur les caractéristiques du champ pour aider la LLM à identifier la pertinence du champ à la question de l'utilisateur.
Bien que ce tutoriel se soit limité à travailler avec une seule table (par exemple, pas de jointures entre les tables), certains LLM, tels que ceux disponibles sur OpenAI, peuvent gérer des cas plus complexes, notamment en travaillant avec plusieurs tables et en identifiant les opérations de jointure correctes. L'ajustement de la fonction LANG2SQL pour gérer plusieurs tables pourrait être une belle étape suivante.
Ce tutoriel est sous licence sous une licence internationale Creative Commons Attribution-NonCommercial-Sharealike 4.0.


