super json mode
1.0.0
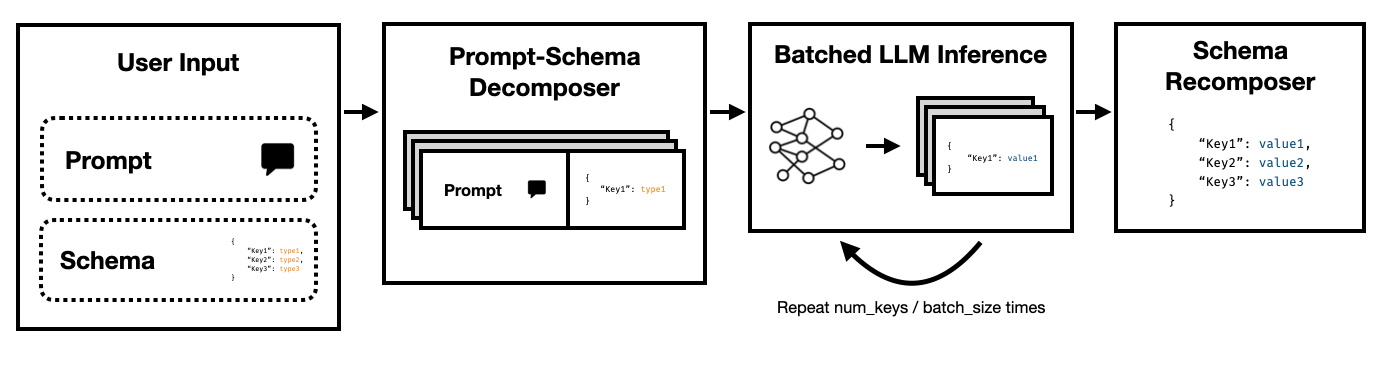
Le mode Super JSON est un cadre Python qui permet la création efficace de la sortie structurée d'un LLM en divisant un schéma cible en composants atomiques, puis en effectuant des générations en parallèle.
Il prend en charge à la fois l'API de statut de statut de statut de State of the Art via l'API de compléments hérités d'Openai et les LLM open source tels que via les transformateurs de face étreintes et VLLM . Plus de LLMS seront bientôt pris en charge!
Par rapport à un pipeline de génération JSON naïf reposant sur l'incitation et les transformateurs HF, nous constatons que le mode Super JSON peut générer des sorties jusqu'à 10x plus rapidement . Il est également plus déterministe et moins susceptible de rencontrer des problèmes d'analyse par rapport à la génération naïve.
L'installation est simple: pip install super-json-mode
Les formats de sortie structurés, tels que JSON ou YAML, ont une structure parallèle ou hiérarchique inhérente.
Considérez le passage non structuré suivant (généré par GPT-4):
Bienvenue au 123 Azure Lane, une superbe résidence de San Francisco avec un design contemporain fantastique, maintenant sur le marché pour 2 500 000 $. Étendue sur un luxe de 3 000 pieds carrés, cette propriété combine la sophistication et le confort pour créer une expérience de vie vraiment unique.
Une maison idyllique pour les familles ou les professionnels, notre résidence exclusive est équipée de cinq chambres spacieuses, chacune de chaleur suintant et d'élégance moderne. Les chambres sont soigneusement prévues pour permettre une lumière naturelle et un espace de stockage généreux. Avec trois salles de bains complètes élégamment conçues, la résidence garantit la commodité et l'intimité de ses résidents.
La grande entrée vous mène à un salon spacieux, offrant une excellente ambiance aux rassemblements ou une soirée tranquille près du feu. La cuisine du chef comprend des appareils électroménagers de pointe, des armoires personnalisées et de beaux comptoirs en granit, ce qui en fait un rêve pour tous ceux qui aiment cuisiner.
Si nous voulons extraire address , square footage , number of bedrooms , number of bathrooms et price à l'aide d'un LLM, nous pourrions demander au modèle de remplir un schéma selon la description.
Un schéma potentiel (comme celui généré à partir d'un objet pydatique) pourrait ressembler à ceci:
{
"address": {
"type": "string"
},
"price": {
"type": "number"
},
"square_feet": {
"type": "integer"
},
"num_beds": {
"type": "integer"
},
"num_baths": {
"type": "integer"
}
}
Et une sortie valide pourrait ressembler à ceci:
{
"address": "123 Azure Lane",
"price": 2500000,
"square_feet": 3000,
"num_beds": 5,
"num_baths": 3
}
L'approche évidente consiste à nicher le schéma dans l'invite et à demander au modèle de le remplir. C'est actuellement ainsi que la plupart des équipes extraient actuellement la sortie structurée à partir de texte non structuré à l'aide de LLMS.
Cependant, cela est inefficace pour trois raisons.
Remarquez comment chacune de ces clés est indépendante les unes des autres. Le mode Super JSON tire parti du parallélisme rapide en traitant chaque paire de valeurs clés dans le schéma comme une enquête distincte. Par exemple, nous pouvons extraire le num_baths sans avoir déjà généré l' address !
Demander un modèle pour générer JSON à partir de zéro consomme inutilement les jetons (et le temps) sur la syntaxe prévisible, comme les noms d'engins et les clés, qui sont déjà attendus dans la sortie. Il s'agit d'une forte antérieure sur la génération que nous devrions être en mesure d'utiliser pour améliorer les latences.
Les LLM sont embarrassantes et exécutées les requêtes en lots sont beaucoup plus rapides que dans un ordre en série. Ainsi, nous pouvons diviser le schéma sur plusieurs requêtes. Le LLM remplira ensuite le schéma pour chaque clé indépendante en parallèle et émettra beaucoup moins de jetons en un seul passage, permettant des temps d'inférence beaucoup plus rapides.
Exécutez la commande suivante:
pip install super-json-mode
conda create --name superjsonmode python=3.10 -y
conda activate superjsonmode
git clone https://github.com/varunshenoy/super-json-mode
cd superjsonmode
pip install -r requirements.txt
Nous avons essayé de rendre le mode Super JSON super facile à utiliser. Voir le dossier examples pour plus d'exemples et utilisation vLLM .
Utilisation d'Openai et gpt-3-instruct-turbo :
from superjsonmode . integrations . openai import StructuredOpenAIModel
from pydantic import BaseModel
import time
model = StructuredOpenAIModel ()
class Character ( BaseModel ):
name : str
genre : str
age : int
race : str
occupation : str
best_friend : str
home_planet : str
prompt_template = """{prompt}
Please fill in the following information about this character for this key. Keep it succinct. It should be a {type}.
{key}: """
prompt = """Luke Skywalker is a famous character."""
start = time . time ()
output = model . generate (
prompt ,
extraction_prompt_template = prompt_template ,
schema = Character ,
batch_size = 7 ,
stop = [ " n n " ],
temperature = 0 ,
)
print ( f"Total time: { time . time () - start } " )
# Total Time: 0.409s
print ( output )
# {
# "name": "Luke Skywalker",
# "genre": "Science fiction",
# "age": "23",
# "race": "Human",
# "occupation": "Jedi Knight",
# "best_friend": "Han Solo",
# "home_planet": "Tatooine",
# }Utilisation de Mistral 7B avec des transformateurs à câlins:
from transformers import AutoTokenizer , AutoModelForCausalLM
from superjsonmode . integrations . transformers import StructuredOutputForModel
from pydantic import BaseModel
device = "cuda"
model = AutoModelForCausalLM . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" ). to ( device )
tokenizer = AutoTokenizer . from_pretrained ( "mistralai/Mistral-7B-Instruct-v0.2" )
# Create a structured output object
structured_model = StructuredOutputForModel ( model , tokenizer )
passage = """..."""
class QuarterlyReport ( BaseModel ):
company : str
stock_ticker : str
date : str
reported_revenue : str
dividend : str
prompt_template = """[INST]{prompt}
Based on this excerpt, extract the correct value for "{key}". Keep it succinct. It should have a type of `{type}`.[/INST]
{key}: """
output = structured_model . generate ( passage ,
extraction_prompt_template = prompt_template ,
schema = QuarterlyReport ,
batch_size = 6 )
print ( json . dumps ( output , indent = 2 ))
# {
# "company": "NVIDIA",
# "stock_ticker": "NVDA",
# "date": "2023-10",
# "reported_revenue": "18.12 billion dollars",
# "dividend": "0.04"
# } Il y a beaucoup de fonctionnalités qui peuvent améliorer le mode Super JSON. Voici quelques idées.
Analyse de sortie qualitative : nous avons effectué des références de performance, mais nous devrions trouver une approche plus rigoureuse pour juger les sorties qualitatives du mode Super JSON.
Échantillonnage structuré : idéalement, nous devons masquer les logits de la LLM pour appliquer les contraintes de type, similaires à JSONFormger. Il existe quelques packages qui le font déjà, et soit ceux-ci doivent intégrer notre pipeline de génération JSON parallélisée, soit nous devons le construire en mode Super JSON.
Support du graphique de dépendance : le mode Super JSON a un cas de défaillance très évident: lorsqu'une clé a une dépendance à une autre clé. Considérez un blob JSON avec deux clés, thought et response . Ce type de sortie souhaitée est courant pour la chaîne de pensées avec des modèles de grands langues, et il est très clair que la response dépend de la thought . Nous devrions être en mesure de passer un graphique des dépendances et des invites par lots d'une manière que les sorties parents sont terminées et transmises aux éléments de schéma enfant.
Prise en charge du modèle local : le mode Super JSON fonctionne mieux dans les situations locales où la taille du lot est généralement 1. Vous pouvez exploiter les lots pour réduire la latence, similaire au décodage spéculatif. Lama.cpp est le premier cadre pour les modèles locaux + l'inférence CPU. J'adorerais implémenter cela en utilisant Olllama si possible.
Prise en charge de TRT-LLM : VLLM est génial et facile à utiliser, mais idéalement, nous nous intégrons à un framework beaucoup plus performant comme Trt-llm.
Nous l'apprécions si vous veuillez citer ce dépôt si vous trouviez la bibliothèque utile pour votre travail:
@misc{ShenoyDerhacobian2024,
author = {Shenoy, Varun and Derhacobian, Alex},
title = {Super JSON Mode: A Framework for Accelerated Structured Output Generation},
year = {2024},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {url{https://github.com/varunshenoy/super-json-mode}}
}
Ce projet a été construit pour CS 229: Systèmes pour l'apprentissage automatique. Un grand merci à l'équipe d'enseignement et aux TAS pour leurs conseils tout au long de ce projet.


