llm gateway
v0.1.2
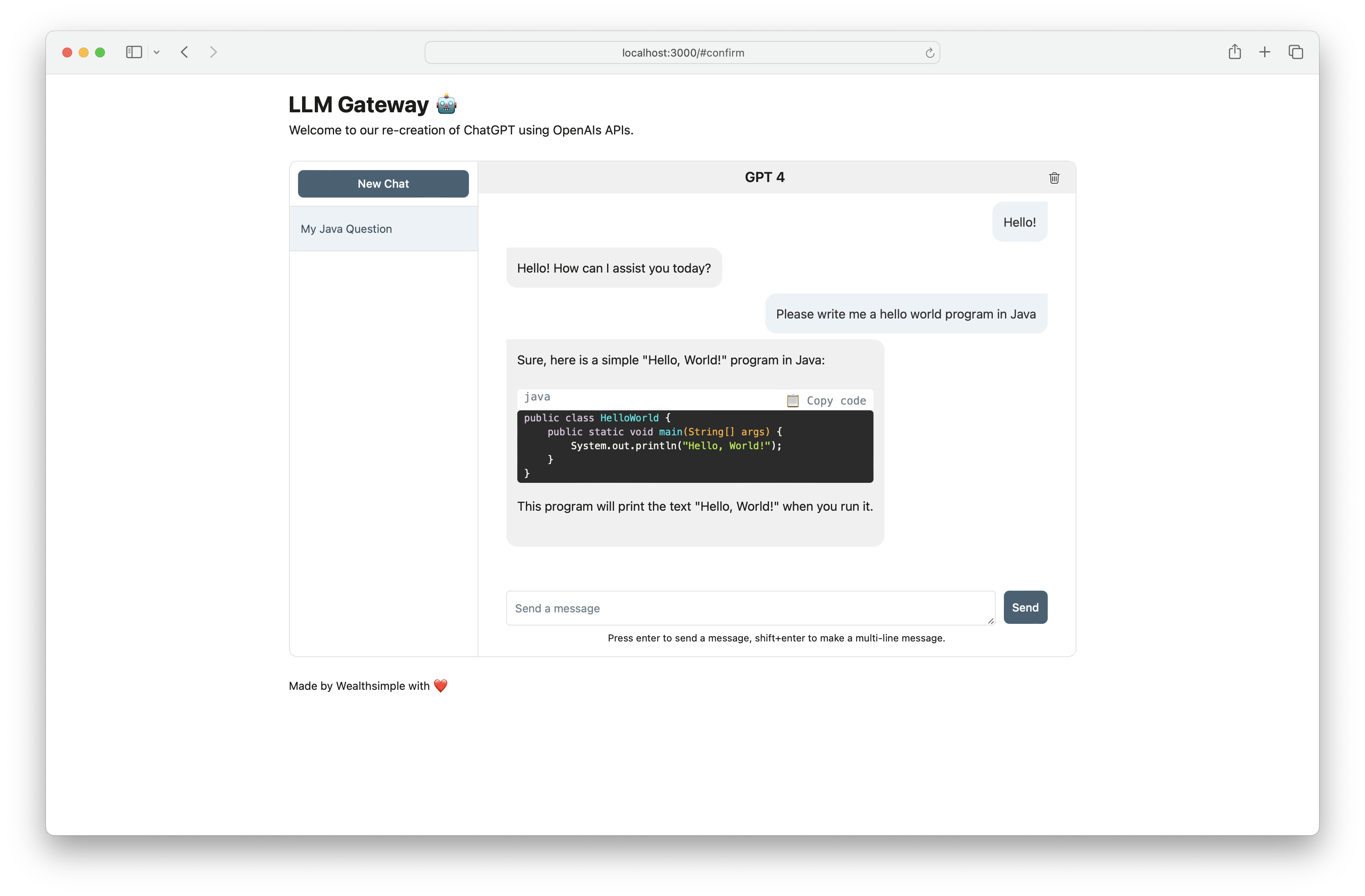
llm-gateway est une passerelle pour les fournisseurs de tiers LLM tels que OpenAI, Cohere, etc. Il suit les données envoyées et reçues de ces fournisseurs dans une base de données Postgres et exécute l'heuristique de nettoyage PII avant l'envoi.
Selon la politique d'utilisation des données des produits de consommation non API d'OpenAI, ils "peuvent utiliser des contenus tels que des invites, des réponses, des images téléchargées et des images générées pour améliorer nos services" pour améliorer les produits comme Chatgpt et Dall-E.
Utilisez llm-gateway pour interagir avec OpenAI de manière sûre. La passerelle recrée également le frontend Chatgpt en utilisant le point de terminaison Openai /ChatCompletion pour conserver toute communication au sein de l'API.
| Fournisseur | Modèle |
|---|---|
| Openai | GPT 3.5 Turbo |
| Openai | GPT 3.5 Turbo 16k |
| Openai | Gpt 4 |
| Laboratoires AI21 | Jurassic-2 Ultra |
| Laboratoires AI21 | Jurassic-2 Mid |
| Amazone | Titan Text Lite |
| Amazone | Titan Text Express |
| Amazone | Titan Text Embeddings |
| Anthropique | Claude 2.1 |
| Anthropique | Claude 2.0 |
| Anthropique | Claude 1.3 |
| Anthropique | Claude instantané |
| Adhérer | Commande |
| Adhérer | Lumière de commande |
| Adhérer | Embed - Anglais |
| Adhérer | Intégration - multilingue |
| Méta | Lama-2-13b-chat |
| Méta | LLAMA-2-70B-CHAT |
La clé API du fournisseur doit être enregistrée en tant que variable d'environnement (voir la configuration plus bas). Si vous communiquez avec OpenAI, définissez OPENAI_API_KEY .
Pour les instructions de configuration étape par étape avec le fondement Cohere, Openai et AWS, cliquez ici.
[Openai] Exemple de curl vers /completion point de terminaison:
curl -X 'POST'
'http://<host>/api/openai/completion'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"temperature": 0,
"prompt": "Tell me what is the meaning of life",
"max_tokens": 50,
"model": "text-davinci-003"
}'
[Openai] Lorsque vous utilisez le point de terminaison /chat_completion , formulez-vous comme conversation entre l'utilisateur et l'assistant.
curl -X 'POST'
'http://<host>/api/openai/chat_completion'
-H 'accept: application/json'
-H 'Content-Type: application/json'
-d '{
"messages": [
{"role": "assistant", "content": "You are an intelligent assistant."},
{"role": "user", "content": "create a healthy recipe"}
],
"model": "gpt-3.5-turbo",
"temperature": 0
}'
from llm_gateway . providers . openai import OpenAIWrapper
wrapper = OpenAIWrapper ()
wrapper . send_openai_request (
"Completion" ,
"create" ,
max_tokens = 100 ,
prompt = "What is the meaning of life?" ,
temperature = 0 ,
model = "text-davinci-003" ,
)Ce projet utilise la poésie, Pyenv pour la dépendance et la gestion de l'environnement. Consultez la documentation d'installation officielle de la poésie et de PYENV pour commencer. Pour la partie frontale, ce projet utilise le NPM et le fil pour la gestion des dépendances. La version de nœud la plus à jour requise pour ce projet est déclarée dans .Node-Version.
Si l'utilisation de Docker, les étapes 1 à 3 sont facultatives. Nous vous recommandons d'installer des crochets pré-comités pour accélérer le cycle de développement.
pyenv install 3.11.3 brew install gitleaks
poetry install
poetry run pre-commit install
cp .envrc.example .envrc et mettre à jour avec des secrets d'APIPour courir dans Docker:
# spin up docker-compose
make up
# open frontend in browser
make browse
# open FastAPI Swagger API
make browse-api
# delete docker-compose setup
make down


