La compréhension des vidéos ultra-longues a toujours été un problème difficile pour les modèles multimodaux en langage étendu (MLLM). Les modèles existants sont difficiles à traiter des données vidéo qui dépassent la longueur maximale du contexte, et l'atténuation des informations et les coûts de calcul élevés constituent également un défi majeur. L'éditeur de Downcodes a appris que l'Institut de recherche Zhiyuan et plusieurs universités avaient proposé un modèle de langage visuel ultra-long appelé Video-XL, conçu pour gérer efficacement les problèmes de compréhension vidéo au niveau d'une heure. La technologie de base de ce modèle est le « résumé latent du contexte visuel », qui utilise intelligemment les capacités de modélisation contextuelle de LLM pour compresser de longues représentations visuelles dans une forme plus compacte, semblable à la condensation d'une vache entière dans un bol d'essence de bœuf, ce qui rend le modèle plus compact. plus efficace. Absorber les informations clés.
Actuellement, les modèles multimodaux de langage étendu (MLLM) ont fait des progrès significatifs dans le domaine de la compréhension vidéo, mais le traitement de vidéos extrêmement longues reste un défi. En effet, MLLM a généralement du mal à gérer des milliers de jetons visuels qui dépassent la longueur maximale du contexte et souffre d'une dégradation des informations causée par l'agrégation de jetons. Dans le même temps, un grand nombre de balises vidéo entraînera également des coûts de calcul élevés.
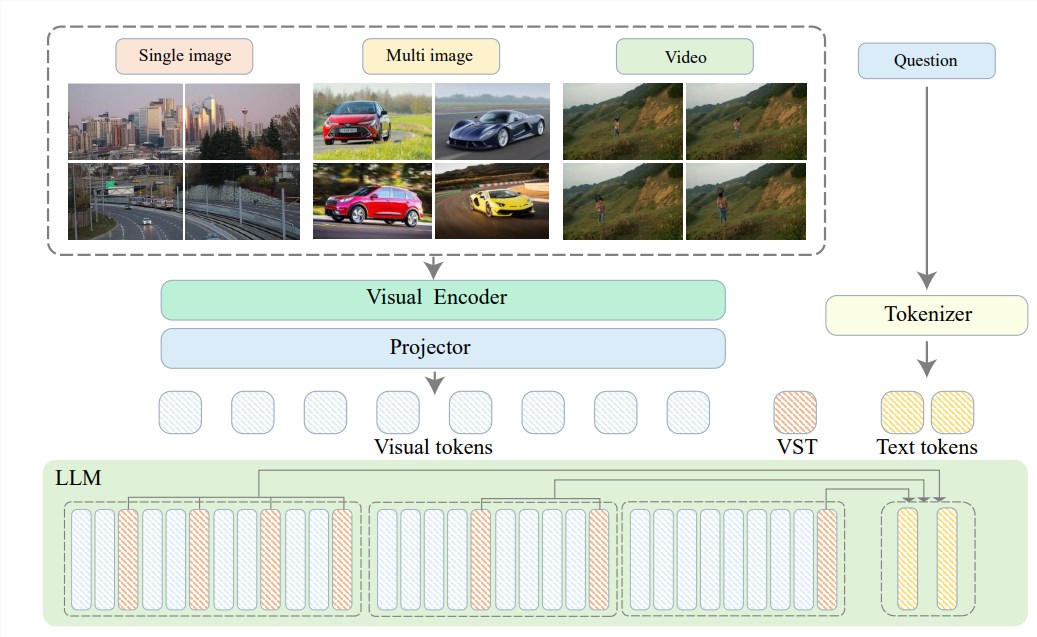
Afin de résoudre ces problèmes, l'Institut de recherche Zhiyuan s'est associé à l'Université Jiao Tong de Shanghai, à l'Université Renmin de Chine, à l'Université de Pékin, à l'Université des postes et télécommunications de Pékin et à d'autres universités pour proposer Video-XL, un système ultra haute définition conçu pour compréhension vidéo efficace au niveau de l’heure. Modèle de langage visuel long. Le cœur de Video-XL réside dans la technologie de « résumé latent du contexte visuel », qui exploite les capacités de modélisation de contexte inhérentes à LLM pour compresser efficacement de longues représentations visuelles sous une forme plus compacte.
Pour faire simple, il s'agit de compresser le contenu vidéo sous une forme plus simplifiée, tout comme condenser une vache entière dans un bol d'essence de bœuf, ce qui est plus facile à digérer et à absorber pour le modèle.
Cette technologie de compression améliore non seulement l'efficacité, mais préserve également efficacement les informations clés de la vidéo. Vous savez, les longues vidéos sont souvent remplies de nombreuses informations redondantes, comme les chaussures d’une vieille dame, longues et malodorantes. Video-XL peut éliminer avec précision ces informations inutiles et conserver uniquement les parties essentielles, ce qui garantit que le modèle ne se perdra pas lors de la compréhension d'un contenu vidéo long.
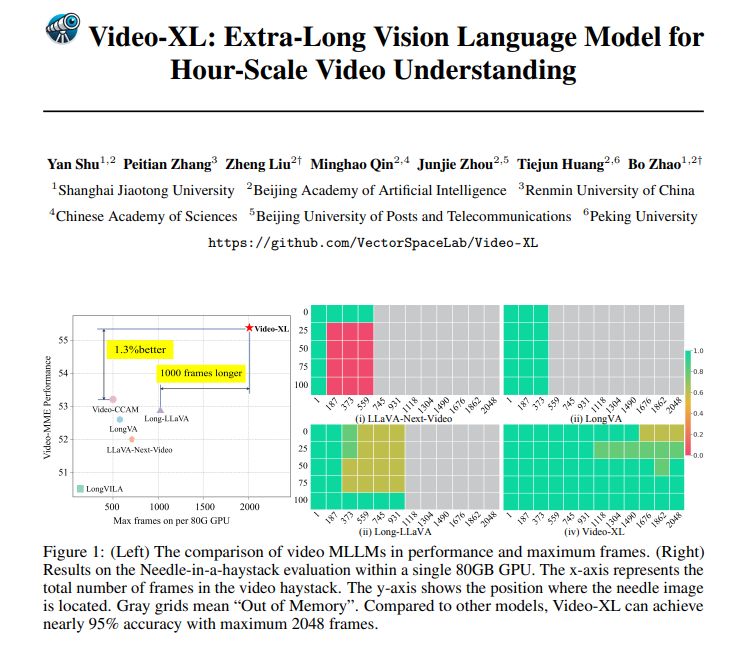
Video-XL est non seulement excellent en théorie, mais aussi tout à fait performant en pratique. Video-XL a obtenu des résultats de premier plan dans plusieurs tests de compréhension de vidéos longues, en particulier dans le test VNBench, où sa précision est près de 10 % supérieure à celle des meilleures méthodes existantes.
Plus impressionnant encore, Video-XL atteint un équilibre étonnant entre efficacité et efficacité, capable de traiter 2 048 images vidéo sur un seul GPU de 80 Go tout en conservant une précision de près de 95 % dans l'évaluation du taux « aiguille dans la botte de foin ».
Video-XL offre également de larges perspectives d'application. En plus d'être capable de comprendre de longues vidéos générales, il est également capable d'effectuer des tâches spécifiques telles que le résumé de films, la détection d'anomalies de surveillance et la reconnaissance de placement d'annonces.
Cela signifie que vous n'aurez plus à supporter de longues intrigues lorsque vous regarderez des films à l'avenir. Vous pouvez directement utiliser Video-XL pour générer un résumé simplifié, économisant ainsi du temps et des efforts, ou vous pouvez l'utiliser pour surveiller les images de surveillance et identifier automatiquement les événements anormaux ; , ce qui est beaucoup plus efficace que le suivi manuel .
Adresse du projet : https://github.com/VectorSpaceLab/Video-XL
Article : https://arxiv.org/pdf/2409.14485
Video-XL a réalisé des progrès révolutionnaires dans le domaine de la compréhension des vidéos ultra-longues. Sa combinaison parfaite d'efficacité et de précision offre une nouvelle solution pour le traitement des vidéos longues. Elle a de larges perspectives d'application dans le futur et mérite d'être attendue !