La formation sur de grands modèles prend du temps et demande beaucoup de travail. Comment améliorer l'efficacité et réduire la consommation d'énergie est devenu une question clé dans le domaine de l'IA. AdamW, en tant qu'optimiseur par défaut pour la pré-formation de Transformer, est progressivement incapable de gérer des modèles de plus en plus volumineux. L'éditeur de Downcodes vous fera découvrir un nouvel optimiseur développé par une équipe chinoise - C-AdamW. Avec sa stratégie "prudente", il réduit considérablement la consommation d'énergie tout en assurant la vitesse et la stabilité de l'entraînement, et apporte de grands avantages à l'entraînement de grands modèles. .pour révolutionner le changement.
Dans le monde de l’IA, travailler dur pour réaliser des miracles semble être la règle d’or. Plus le modèle est grand, plus il y a de données et plus la puissance de calcul est forte, plus il semble se rapprocher du Saint Graal de l’intelligence. Cependant, derrière ce développement rapide, il existe également d’énormes pressions sur les coûts et la consommation d’énergie.
Afin de rendre la formation en IA plus efficace, les scientifiques recherchent des optimiseurs plus puissants, comme un coach, pour guider les paramètres du modèle afin d'optimiser en permanence et finalement atteindre le meilleur état. AdamW, en tant qu'optimiseur par défaut pour la pré-formation de Transformer, est la référence du secteur depuis de nombreuses années. Cependant, face à l'échelle de plus en plus grande du modèle, AdamW a également commencé à paraître incapable de faire face à ses capacités.
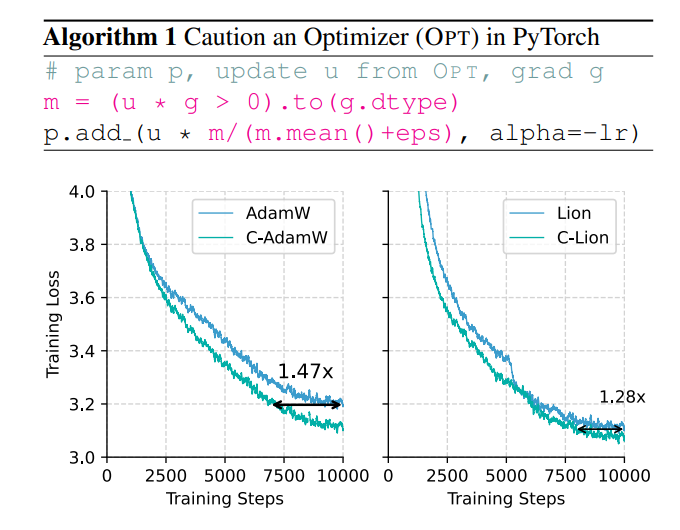
N'y a-t-il pas un moyen d'augmenter la vitesse d'entraînement tout en réduisant la consommation d'énergie ? Ne vous inquiétez pas, une équipe entièrement chinoise est là avec son arme secrète C-AdamW !
Le nom complet de C-AdamW est Cautious AdamW, et son nom chinois est Cautious AdamW Cela ne semble-t-il pas très bouddhiste ? Oui, l'idée centrale de C-AdamW est de réfléchir à deux fois avant d'agir.

Imaginez que les paramètres du modèle ressemblent à un groupe d'enfants énergiques qui veulent toujours courir. AdamW est comme un professeur dévoué, essayant de les guider dans la bonne direction. Mais parfois, les enfants sont trop excités et courent dans la mauvaise direction, perdant ainsi du temps et de l’énergie.
À l'heure actuelle, C-AdamW est comme un aîné sage avec une paire d'yeux perçants, capable d'identifier avec précision si la direction de la mise à jour est correcte. Si la direction est mauvaise, C-AdamW appellera de manière décisive un arrêt pour empêcher le modèle d'aller plus loin sur la mauvaise route.
Cette stratégie prudente garantit que chaque mise à jour peut réduire efficacement la fonction de perte, accélérant ainsi la convergence du modèle. Les résultats expérimentaux montrent que C-AdamW augmente la vitesse d'entraînement jusqu'à 1,47 fois lors de la pré-entraînement Llama et MAE !
Plus important encore, C-AdamW ne nécessite pratiquement aucune charge de calcul supplémentaire et peut être implémenté avec une simple modification d'une ligne du code existant. Cela signifie que les développeurs peuvent facilement appliquer C-AdamW à diverses formations de modèles et profiter de la vitesse et de la passion !
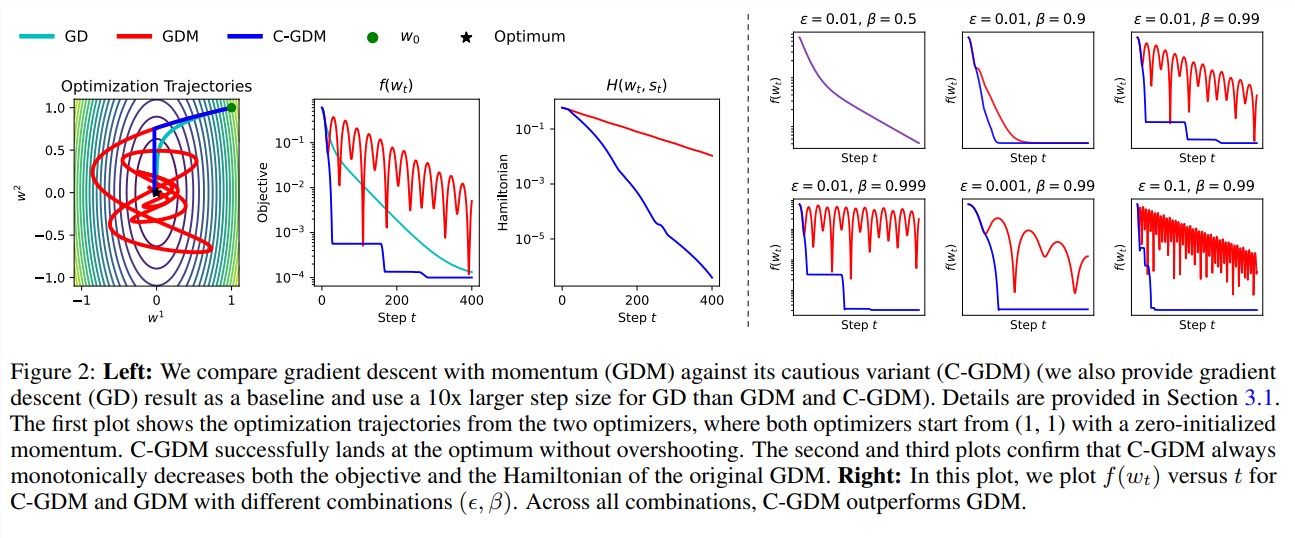
L'avantage de C-AdamW est qu'il conserve la fonction hamiltonienne d'Adam et ne détruit pas la garantie de convergence dans l'analyse de Lyapunov. Cela signifie que C-AdamW est non seulement plus rapide, mais que sa stabilité est également garantie et qu'il n'y aura aucun problème tel qu'un crash d'entraînement.
Bien entendu, être bouddhiste ne signifie pas que vous n’êtes pas entreprenant. L'équipe de recherche a déclaré qu'elle continuerait à explorer des fonctions ϕ plus riches et à appliquer des masques dans l'espace des fonctionnalités plutôt que dans l'espace des paramètres pour améliorer encore les performances de C-AdamW.
Il est prévisible que C-AdamW deviendra le nouveau favori dans le domaine de l'apprentissage profond, apportant des changements révolutionnaires à la formation de grands modèles !
Adresse papier : https://arxiv.org/abs/2411.16085
GitHub :
https://github.com/kyleliang919/C-Optim
L'émergence de C-AdamW fournit de nouvelles idées pour résoudre les problèmes d'efficacité de la formation des grands modèles et de consommation d'énergie. Son rendement élevé, sa stabilité et ses caractéristiques faciles à utiliser le rendent très prometteur pour les applications. On s’attend à ce que C-AdamW puisse être appliqué dans davantage de domaines à l’avenir et favoriser le développement continu de la technologie de l’IA. L'éditeur de Downcodes continuera à prêter attention aux progrès technologiques pertinents, alors restez à l'écoute !