L'éditeur de Downcodes a appris que l'Université de Pékin et d'autres équipes de recherche scientifique ont publié LLaVA-o1, un modèle open source multimodal historique. Le modèle a surpassé des concurrents tels que Gemini, GPT-4o-mini et Llama dans plusieurs tests de référence, et son mécanisme de raisonnement à « réflexion lente » lui a permis d'effectuer un raisonnement plus complexe, comparable à GPT-o1. L'open source de LLaVA-o1 apportera une nouvelle vitalité à la recherche et aux applications dans le domaine de l'IA multimodale.
Récemment, l'Université de Pékin et d'autres équipes de recherche scientifique ont annoncé la sortie d'un modèle open source multimodal appelé LLaVA-o1, qui serait le premier modèle de langage visuel capable de raisonnement spontané et systématique, comparable à GPT-o1.
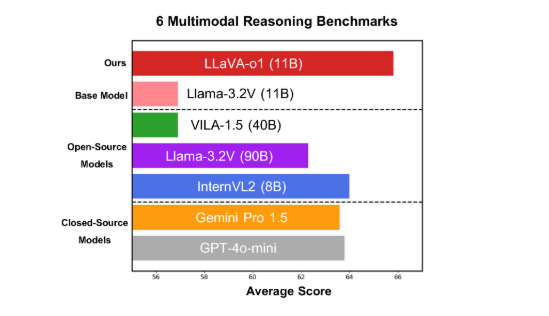
Le modèle fonctionne bien sur six benchmarks multimodaux difficiles, avec sa version à paramètres 11B surpassant d'autres concurrents tels que Gemini-1.5-pro, GPT-4o-mini et Llama-3.2-90B-Vision-Instruct.
LLaVA-o1 est basé sur le modèle Llama-3.2-Vision et adopte un mécanisme de raisonnement de « pensée lente », qui peut mener indépendamment des processus de raisonnement plus complexes, surpassant la méthode traditionnelle d'invite de la chaîne de pensée.
Sur le benchmark d'inférence multimodale, LLaVA-o1 a surperformé son modèle de base de 8,9 %. Le modèle est unique dans la mesure où son processus de raisonnement est divisé en quatre étapes : résumé, explication visuelle, raisonnement logique et génération de conclusions. Dans les modèles traditionnels, le processus de raisonnement est souvent relativement simple et peut facilement conduire à de mauvaises réponses, tandis que LLaVA-o1 garantit des résultats plus précis grâce à un raisonnement structuré en plusieurs étapes.
Par exemple, lors de la résolution du problème « Combien d'objets reste-t-il après avoir soustrait toutes les petites boules lumineuses et les objets violets ? », LLaVA-o1 résumera d'abord le problème, puis extraira les informations de l'image, puis effectuera un raisonnement étape par étape. , et enfin donner la réponse. Cette approche par étapes améliore les capacités de raisonnement systématique du modèle, le rendant plus efficace dans le traitement de problèmes complexes.

Il convient de mentionner que LLaVA-o1 introduit une méthode de recherche de faisceau au niveau de l'étage dans le processus d'inférence. Cette approche permet au modèle de générer plusieurs réponses candidates à chaque étape d'inférence et de sélectionner la meilleure réponse pour passer à l'étape d'inférence suivante, améliorant ainsi considérablement la qualité globale de l'inférence. Grâce à un réglage fin supervisé et à des données d'entraînement raisonnables, LLaVA-o1 fonctionne bien en comparaison avec des modèles plus grands ou à source fermée.
Les résultats de recherche de l’équipe de l’Université de Pékin favorisent non seulement le développement de l’IA multimodale, mais fournissent également de nouvelles idées et méthodes pour les futurs modèles de compréhension du langage visuel. L'équipe a déclaré que le code, les poids de pré-entraînement et les ensembles de données de LLaVA-o1 seront entièrement open source, et elle attend avec impatience que davantage de chercheurs et de développeurs explorent et appliquent conjointement ce modèle innovant.
Article : https://arxiv.org/abs/2411.10440
GitHub : https://github.com/PKU-YuanGroup/LLaVA-o1
L’open source de LLaVA-o1 favorisera sans aucun doute le développement technologique et l’innovation applicative dans le domaine de l’IA multimodale. Son mécanisme d'inférence efficace et ses excellentes performances en font une référence importante pour les futures recherches sur les modèles de langage visuel et méritent attention et anticipation. Nous attendons avec impatience la participation d’un plus grand nombre de développeurs et la promotion conjointe des progrès de la technologie de l’intelligence artificielle.