Êtes-vous curieux de connaître la technologie derrière les produits d'IA tels que ChatGPT et Wenxinyiyan ? Ils s'appuient tous sur de grands modèles de langage (LLM). L'éditeur de Downcodes vous fera comprendre le principe de fonctionnement du LLM d'une manière simple et facile à comprendre Même si vous n'avez qu'un niveau de mathématiques de deuxième année, vous pourrez facilement le comprendre ! Nous partirons des concepts de base des réseaux de neurones et expliquerons progressivement la formation de modèles, les techniques avancées et les technologies de base telles que l'architecture GPT et Transformer, afin que vous ayez une compréhension claire du LLM.
Avez-vous entendu parler d'IA avancées telles que ChatGPT et Wen Xinyiyan ? La technologie de base qui les sous-tend est le « grand modèle de langage » (LLM). Vous trouvez cela compliqué et difficile à comprendre ? Ne vous inquiétez pas, même si vous n'avez qu'un niveau de mathématiques en CE2, vous pourrez facilement comprendre le principe de fonctionnement du LLM après avoir lu cet article !
Réseaux de neurones : la magie des nombres
Tout d’abord, il faut savoir qu’un réseau de neurones est comme un superordinateur, il ne peut traiter que des nombres. L’entrée et la sortie doivent être des nombres. Alors, comment lui faire comprendre le texte ?
Le secret est de convertir les mots en nombres. Par exemple, nous pouvons représenter chaque lettre par un nombre, comme a=1, b=2, etc. De cette manière, le réseau neuronal peut « lire » le texte.
Entraîner le modèle : laissez le réseau « apprendre » le langage
Avec le texte numérique, l’étape suivante consiste à entraîner le modèle et à laisser le réseau neuronal « apprendre » les règles du langage.
Le processus de formation ressemble à un jeu de devinettes. Nous montrons au réseau un texte, tel que « Humpty Dumpty », et lui demandons de deviner quelle est la lettre suivante. S’il devine correctement, nous lui donnons une récompense ; s’il se trompe, nous lui donnons une pénalité. En devinant et en s'ajustant constamment, le réseau peut prédire la lettre suivante avec une précision croissante, pour finalement produire des phrases complètes telles que « Humpty Dumpty assis sur un mur ».
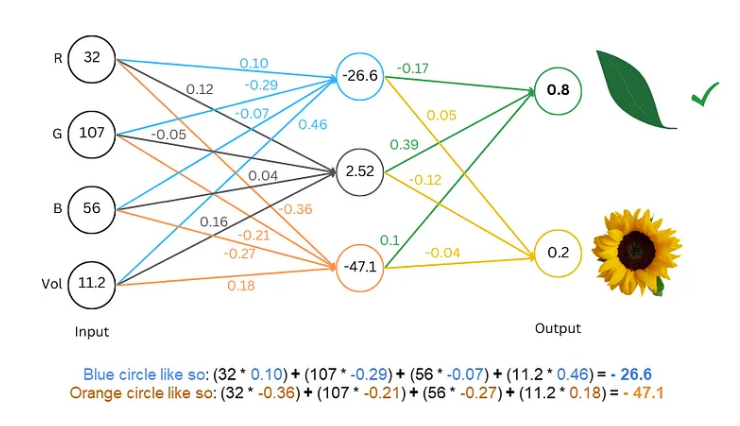
Techniques avancées : Rendre le modèle plus "intelligent"
Afin de rendre le modèle plus « intelligent », les chercheurs ont inventé de nombreuses techniques avancées, telles que :
Incorporation de mots : au lieu d'utiliser de simples nombres pour représenter les lettres, nous utilisons un ensemble de nombres (vecteurs) pour représenter chaque mot, ce qui peut décrire plus complètement la signification du mot.
Segmenteur de sous-mots : divisez les mots en unités plus petites (sous-mots), par exemple en divisant « chats » en « chat » et « s », ce qui peut réduire le vocabulaire et améliorer l'efficacité.
Mécanisme d'auto-attention : lorsque le modèle prédit le mot suivant, il ajustera le poids de la prédiction en fonction de tous les mots du contexte, tout comme nous comprenons la signification du mot en fonction du contexte lors de la lecture.
Connexion résiduelle : Afin d'éviter les difficultés de formation causées par un trop grand nombre de couches réseau, les chercheurs ont inventé la connexion résiduelle pour faciliter l'apprentissage du réseau.
Mécanisme d'attention multi-têtes : en exécutant plusieurs mécanismes d'attention en parallèle, le modèle peut comprendre le contexte sous différentes perspectives et améliorer la précision des prédictions.
Encodage positionnel : pour que le modèle comprenne l'ordre des mots, les chercheurs ajouteront des informations de position aux intégrations de mots, tout comme nous prêtons attention à l'ordre des mots lors de la lecture.
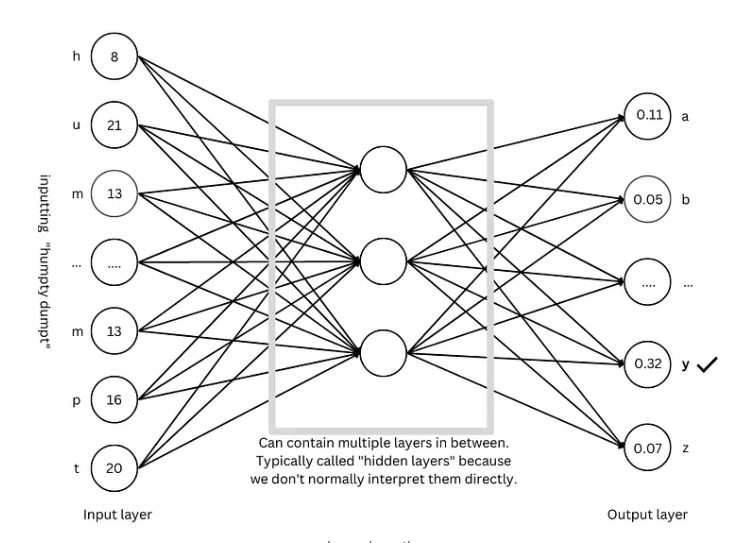
Architecture GPT : le « modèle » pour les modèles de langage à grande échelle
L'architecture GPT est actuellement l'une des architectures de modèles de langage à grande échelle les plus populaires. Elle constitue comme un « plan » qui guide la conception et la formation du modèle. L'architecture GPT combine intelligemment les techniques avancées mentionnées ci-dessus pour permettre au modèle d'apprendre et de générer efficacement le langage.
Transformer Architecture : la « révolution » des modèles de langage
L'architecture Transformer constitue une avancée majeure dans le domaine des modèles de langage ces dernières années. Elle améliore non seulement la précision de la prédiction, mais réduit également la difficulté de la formation, jetant ainsi les bases du développement de modèles de langage à grande échelle. L'architecture GPT a également évolué sur la base de l'architecture Transformer.
Référence : https://towardsdatascience.com/understanding-llms-from-scratch-using-middle-school-math-e602d27ec876
J'espère que l'explication de l'éditeur de Downcodes pourra vous aider à comprendre les principes de fonctionnement des grands modèles de langage. Bien sûr, la technologie LLM est encore en développement. Cet article n'est que la pointe de l'iceberg. Un contenu de plus en plus approfondi vous oblige à continuer à apprendre et à explorer !