L'éditeur de Downcodes a appris que Meta a récemment publié une nouvelle commande de dialogue multi-tours multilingue à la suite du test de référence d'évaluation des capacités Multi-IF. Le benchmark couvre huit langues et contient 4501 tâches de dialogue en trois tours, visant à évaluer de manière plus complète les grandes tâches. performances des modèles de langage (LLM) dans des applications pratiques. Contrairement aux normes d'évaluation existantes qui se concentrent principalement sur le dialogue à un seul tour et les tâches dans une seule langue, Multi-IF se concentre sur l'examen de la capacité du modèle dans des scénarios complexes à plusieurs tours et multilingues, fournissant ainsi une orientation plus claire pour l'amélioration du LLM.
Meta a récemment publié un nouveau test de référence appelé Multi-IF, conçu pour évaluer la capacité de suivi d'instructions des grands modèles de langage (LLM) dans des conversations à plusieurs tours et des environnements multilingues. Ce benchmark couvre huit langues et contient 4501 tâches de dialogue à trois tours, se concentrant sur les performances des modèles actuels dans des scénarios complexes multi-tours et multilingues.
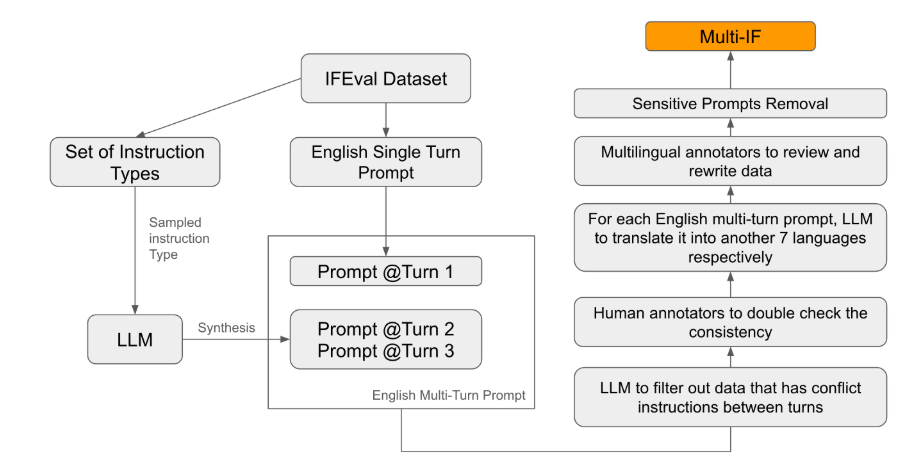
Parmi les normes d'évaluation existantes, la plupart se concentrent sur le dialogue à tour unique et les tâches en une seule langue, qui sont difficiles à refléter pleinement les performances du modèle dans des applications pratiques. Le lancement de Multi-IF vise à combler cette lacune. L'équipe de recherche a généré des scénarios de dialogue complexes en étendant une seule série d'instructions en plusieurs séries d'instructions, et a veillé à ce que chaque série d'instructions soit logiquement cohérente et progressive. En outre, l'ensemble de données prend également en charge plusieurs langues grâce à des étapes telles que la traduction automatique et la relecture manuelle.
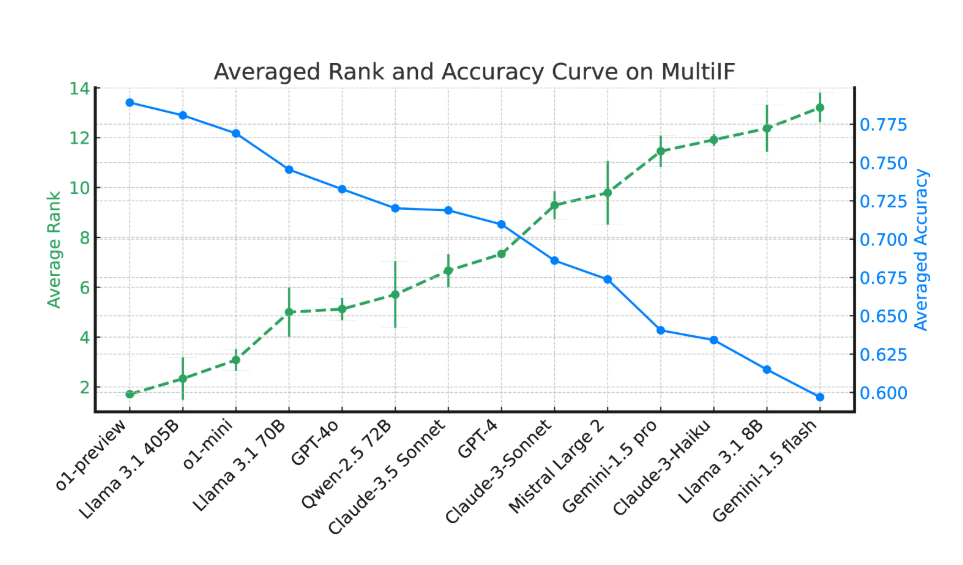
Les résultats expérimentaux montrent que les performances de la plupart des LLM diminuent considérablement au fil de plusieurs cycles de dialogue. En prenant comme exemple le modèle o1-preview, sa précision moyenne au premier tour était de 87,7 %, mais est tombée à 70,7 % au troisième tour. Surtout dans les langues avec des écritures non latines, comme l'hindi, le russe et le chinois, les performances du modèle sont généralement inférieures à celles de l'anglais, ce qui montre des limites dans les tâches multilingues.
Lors de l'évaluation de 14 modèles linguistiques de pointe, o1-preview et Llama3.1405B ont obtenu les meilleurs résultats, avec des taux de précision moyens de 78,9 % et 78,1 % respectivement dans trois séries d'instructions. Cependant, au cours de plusieurs cycles de dialogue, tous les modèles ont montré un déclin général de leur capacité à suivre les instructions, reflétant les défis rencontrés par les modèles dans des tâches complexes. L'équipe de recherche a également introduit le « taux d'oubli d'instructions » (IFR) pour quantifier le phénomène d'oubli d'instructions du modèle au cours de plusieurs cycles de dialogue. Les résultats montrent que les modèles hautes performances fonctionnent relativement bien à cet égard.
La sortie de Multi-IF offre aux chercheurs une référence stimulante et favorise le développement du LLM dans la mondialisation et les applications multilingues. Le lancement de ce benchmark révèle non seulement les lacunes des modèles actuels dans les tâches multi-tours et multilingues, mais fournit également une orientation claire pour les améliorations futures.
Article : https://arxiv.org/html/2410.15553v2
La sortie du test de référence Multi-IF fournit une référence importante pour la recherche de grands modèles de langage dans le dialogue multitours et le traitement multilingue, et ouvre également la voie à de futures améliorations du modèle. On s'attend à ce que des LLM de plus en plus puissants émergent à l'avenir pour mieux faire face aux défis des tâches multilingues complexes à plusieurs tours.