GPT-4V, cet artefact connu sous le nom de « regarder des images et parler », a été critiqué pour son manque de compréhension des interfaces graphiques. C’est comme une personne « aveugle à l’écran » qui clique souvent sur les mauvais boutons, ce qui est exaspérant. Cependant, le modèle OmniParser publié par Microsoft devrait résoudre complètement ce problème ! OmniParser est comme un « traducteur d'écran », convertissant les captures d'écran dans le langage structuré facile à comprendre de GPT-4V, rendant la « vue » de GPT-4V plus nette. L'éditeur de Downcodes vous amènera à avoir une compréhension approfondie de ce modèle magique, à voir comment il aide GPT-4V à surmonter le défaut de « cécité oculaire » et à l'étonnante technologie qui se cache derrière.
Vous souvenez-vous encore du GPT-4V, un artefact connu sous le nom de « regarder des images et parler » ? Il peut comprendre le contenu des images et effectuer des tâches basées sur des images. C'est une bénédiction pour les paresseux ! point faible : sa vue n'est pas très bonne !
Imaginez que vous demandiez à GPT-4V de cliquer sur un bouton pour vous, mais qu'il clique partout comme un « store d'écran ».
Aujourd'hui, je vais vous présenter un artefact qui peut améliorer l'apparence de GPT-4V - OmniParser ! Il s'agit d'un nouveau modèle publié par Microsoft, visant à résoudre le problème de l'interaction automatique des interfaces utilisateur graphiques (GUI).
Que fait OmniParser ?
Pour faire simple, OmniParser est un « traducteur d'écran » capable d'analyser les captures d'écran dans un « langage structuré » que GPT-4V peut comprendre. OmniParser combine le modèle de détection d'icônes interactif affiné, le modèle de description d'icône affiné et la sortie du module OCR.

Cette combinaison produit une représentation structurée de type DOM de l'interface utilisateur, ainsi que des captures d'écran couvrant les cadres de délimitation des éléments potentiellement interactifs. Les chercheurs ont d’abord créé un ensemble de données interactif de détection d’icônes à l’aide de pages Web populaires et d’ensembles de données de description d’icônes. Ces ensembles de données permettent d'affiner des modèles spécialisés : un modèle de détection pour analyser les zones interactives sur l'écran et un modèle de description pour extraire la sémantique fonctionnelle des éléments détectés.
Plus précisément, OmniParser :
Identifiez toutes les icônes et boutons interactifs sur l'écran, marquez-les avec des cases et attribuez à chaque case un identifiant unique.
Utilisez du texte pour décrire la fonction de chaque icône, par exemple « Paramètres » et « Réduire ». Reconnaissez le texte à l'écran et extrayez-le.
De cette façon, GPT-4V peut savoir clairement ce qui est à l'écran et ce que fait chaque élément. Indiquez-lui simplement l'ID du bouton sur lequel vous souhaitez cliquer.
À quel point OmniParser est-il génial ?
Les chercheurs ont utilisé divers tests pour tester OmniParser et ont découvert qu'il pouvait vraiment améliorer le GPT-4V !
Lors du test ScreenSpot, OmniParser a considérablement amélioré la précision du GPT-4V, surpassant même certains modèles spécialement conçus pour les interfaces graphiques. Par exemple, sur l'ensemble de données ScreenSpot, OmniParser améliore la précision de 73 %, surpassant ainsi les modèles qui reposent sur l'analyse HTML sous-jacente. Notamment, l'intégration de la sémantique locale des éléments de l'interface utilisateur a entraîné une amélioration significative de la précision des prédictions : les icônes de GPT-4V étaient correctement étiquetées de 70,5 % à 93,8 % lors de l'utilisation de la sortie d'OmniParser.
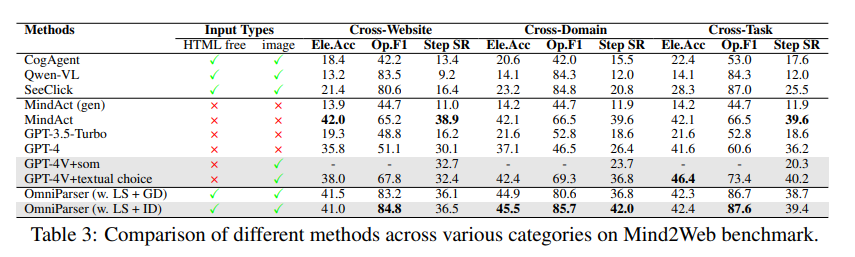
Dans le test Mind2Web, OmniParser a amélioré les performances de GPT-4V dans les tâches de navigation Web, et sa précision a même dépassé GPT-4V qui utilise l'assistance aux informations HTML.
Lors du test AITW, OmniParser a considérablement amélioré les performances de GPT-4V dans les tâches de navigation sur téléphone mobile.
Quelles sont les lacunes d’OmniParser ?
Bien qu'OmniParser soit très puissant, il présente également quelques défauts mineurs, tels que :
Il est facile de se perdre face à des icônes ou du texte répétés , et des descriptions plus détaillées sont nécessaires pour les distinguer.
Parfois, le cadre n'est pas dessiné avec suffisamment de précision , ce qui entraîne le clic du GPT-4V dans la mauvaise position.
L'interprétation des icônes est parfois erronée et nécessite un contexte pour une description plus précise.
Cependant, les chercheurs travaillent dur pour améliorer OmniParser et pensent qu’il deviendra de plus en plus puissant et deviendra à terme le meilleur partenaire de GPT-4V !
Expérience modèle : https://huggingface.co/microsoft/OmniParser
Entrée papier : https://arxiv.org/pdf/2408.00203
Introduction officielle : https://www.microsoft.com/en-us/research/articles/omniparser-for-pure-vision-based-gui-agent/
Souligner:
✨OmniParser peut aider GPT-4V à mieux comprendre le contenu de l'écran et à effectuer les tâches avec plus de précision.
OmniParser a obtenu de bons résultats lors de divers tests, prouvant son efficacité.
?️OmniParser a encore quelques points à améliorer, mais il y a de l'espoir pour l'avenir.
Dans l'ensemble, OmniParser apporte des améliorations révolutionnaires à l'interaction de GPT-4V avec les interfaces utilisateur graphiques. Même s’il subsiste quelques lacunes, son potentiel est énorme et son développement futur mérite d’être attendu. L'éditeur de Downcodes estime qu'avec les progrès continus de la technologie, OmniParser deviendra une étoile brillante dans le domaine de l'intelligence artificielle !