Ces dernières années, l’intelligence artificielle a fait des progrès significatifs dans divers domaines, mais sa capacité de raisonnement mathématique a toujours constitué un goulot d’étranglement. Aujourd'hui, l'émergence d'un nouveau benchmark appelé FrontierMath fournit un nouveau critère d'évaluation des capacités mathématiques de l'IA. Il pousse les capacités de raisonnement mathématique de l'IA à des limites sans précédent et pose de sérieux défis aux modèles d'IA existants. L'éditeur de Downcodes vous amènera à avoir une compréhension approfondie de FrontierMath et à voir comment il bouleverse notre compréhension des capacités mathématiques de l'IA.
Dans le vaste univers de l’intelligence artificielle, les mathématiques étaient autrefois considérées comme le dernier bastion de l’intelligence artificielle. Aujourd'hui, un nouveau test de référence appelé FrontierMath a vu le jour, poussant les capacités de raisonnement mathématique de l'IA à des limites sans précédent.
Epoch AI s'est associé à plus de 60 grands cerveaux du monde des mathématiques pour créer conjointement ce domaine de défi de l'IA que l'on peut appeler l'Olympiade mathématique. Il ne s’agit pas seulement d’un test technique, mais aussi du test ultime de la sagesse mathématique de l’intelligence artificielle.
Imaginez un laboratoire rempli des meilleurs mathématiciens du monde, qui ont créé des centaines d'énigmes mathématiques qui dépassent l'imagination des gens ordinaires. Ces problèmes couvrent les domaines mathématiques les plus avancés tels que la théorie des nombres, l’analyse réelle, la géométrie algébrique et la théorie des catégories, et sont d’une complexité stupéfiante. Même un génie des mathématiques médaillé d’or aux Olympiades internationales de mathématiques a besoin d’heures, voire de jours, pour résoudre un problème.
Il est choquant de constater que les modèles d’IA de pointe actuels ont eu des résultats décevants sur ce benchmark : aucun modèle n’a été capable de résoudre plus de 2 % des problèmes. Ce résultat a été comme un signal d’alarme et a giflé l’IA au visage.
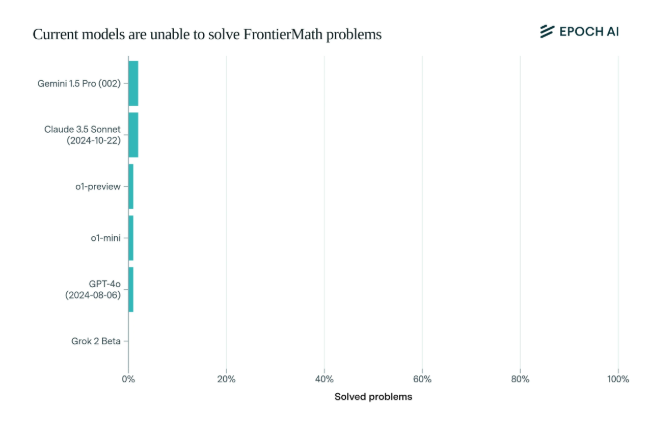
Ce qui rend FrontierMath unique, c'est son mécanisme d'évaluation rigoureux. Les tests de référence mathématiques traditionnels tels que MATH et GSM8K ont été optimisés par l'IA, et ce nouveau test utilise de nouvelles questions inédites et un système de vérification automatisé pour éviter efficacement la pollution des données et tester véritablement les capacités de raisonnement mathématique de l'IA.
Les modèles phares des plus grandes sociétés d'IA telles que OpenAI, Anthropic et Google DeepMind, qui ont attiré beaucoup d'attention, ont été collectivement renversés lors de ce test. Cela reflète une philosophie technique profonde : pour les ordinateurs, des problèmes mathématiques apparemment complexes peuvent être faciles, mais des tâches que les humains trouvent simples peuvent rendre l'IA impuissante.
Comme le disait Andrej Karpathy, cela confirme le paradoxe de Moravec : la difficulté des tâches intelligentes entre humains et machines est souvent contre-intuitive. Ce test de référence n’est pas seulement un examen rigoureux des capacités de l’IA, mais également un catalyseur pour l’évolution de l’IA vers des dimensions supérieures.
Pour la communauté mathématique et les chercheurs en IA, FrontierMath est comme un mont Everest invaincu. Il teste non seulement les connaissances et les compétences, mais également la perspicacité et la pensée créative. À l’avenir, celui qui pourra prendre les devants pour gravir ce sommet de l’intelligence sera inscrit dans l’histoire du développement de l’intelligence artificielle.
L'émergence du test de référence FrontierMath n'est pas seulement un test sévère du niveau technologique existant de l'IA, mais indique également la direction du développement futur de l'IA. Il indique que l'IA a encore un long chemin à parcourir dans le domaine du raisonnement mathématique. cela stimule également la recherche. Les chercheurs continuent d’explorer et d’innover pour surmonter les goulots d’étranglement des technologies existantes.