Aujourd’hui, avec des interactions homme-machine de plus en plus fréquentes, une expérience de conversation fluide et naturelle reste un défi. L'éditeur de Downcodes vous présentera aujourd'hui une technologie révolutionnaire : Moshi, un système de dialogue vocal full-duplex développé par Kyutai Labs. Il s'engage à créer une conversation homme-machine plus naturelle et plus fluide, rendant la communication avec les machines aussi simple que parler avec des amis. L'innovation principale de Moshi réside dans sa méthode unique de génération de parole et sa technologie avancée capable de traiter plusieurs flux audio simultanément. Examinons de plus près les nombreux points forts de Moshi.
À l’ère du numérique, nos conversations avec les machines font désormais partie de notre quotidien. Cependant, ces dialogues manquent souvent de naturel et de fluidité, ce qui les rend un peu moins humains. Cependant, cela pourrait être sur le point de changer. Moshi, un système de dialogue vocal en duplex intégral développé par Kyutai Labs, inaugure une nouvelle ère de dialogue homme-machine plus naturel et plus fluide.
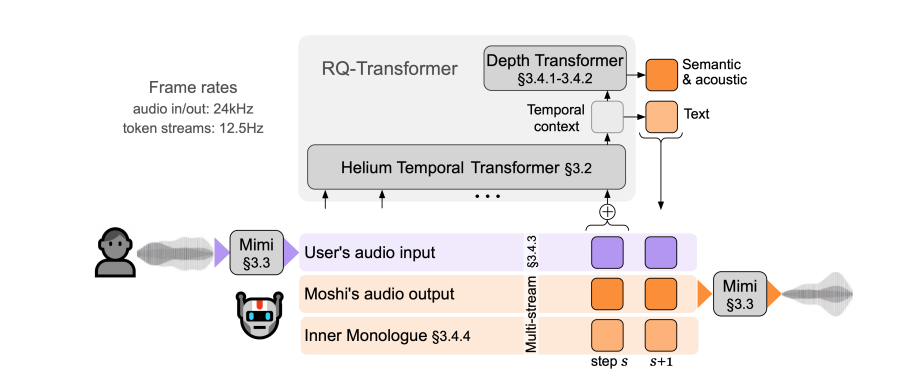
Moshi est un modèle de dialogue basé sur la parole et le texte. Sa principale innovation réside dans le traitement du dialogue comme un processus de génération parole-parole. Cette méthode résout intelligemment de nombreux problèmes existant dans les systèmes de dialogue vocal traditionnels, tels que les retards, la perte d'informations et les limitations des tours de parole. Moshi est unique en ce sens qu'il peut écouter et parler en même temps, tout comme nous, les humains, et gérer facilement les chevauchements, les interruptions et les interjections dans les conversations.
La puissante fonctionnalité de Moshi provient de trois technologies principales. Le premier est le modèle de langage de texte Helium, qui est le cerveau de Moshi. Il possède 7 milliards de paramètres et possède de puissantes capacités de compréhension et de génération du langage grâce à l'apprentissage massif de données en anglais. Vient ensuite le codec audio neuronal Mimi, qui agit comme la bouche et les oreilles de Moshi, convertissant les signaux vocaux et les unités discrètes que le modèle peut comprendre. Enfin, le modèle de langage audio multi-flux est l’innovation de Moshi, lui permettant de traiter plusieurs flux audio simultanément, permettant ainsi une compréhension simultanée des voix de plusieurs locuteurs.
Moshi a également une fonction de monologue intérieur unique. Avant de générer de la parole, il prédit les jetons de texte alignés dans le temps et synchronisés avec les jetons audio. Cela améliore non seulement la qualité linguistique de la parole générée, mais fournit également des services de reconnaissance vocale en streaming et de synthèse vocale, améliorant encore ses capacités conversationnelles.
Lors de divers tests de performances, Moshi a montré d'excellentes performances. Qu'il s'agisse de compréhension de texte, d'intelligibilité de la parole, de qualité audio ou de questions et réponses orales, Moshi a atteint le premier niveau parmi les modèles parole-texte existants. Cela signifie que nous nous rapprochons d’un dialogue homme-machine véritablement naturel et fluide.
Cependant, avec le développement de la technologie de l’IA, les problèmes de sécurité sont devenus de plus en plus importants. Il convient de noter que l’équipe de développement de Moshi a pris cela en considération dès le début. Ils prennent plusieurs mesures pour garantir la sécurité du système, notamment en évitant la génération de contenus préjudiciables, en protégeant la vie privée des utilisateurs et en garantissant une bonne cohérence. Moshi est capable d'identifier et de refuser de répondre aux questions inappropriées tout en conservant la cohérence de sa propre voix et en n'imitant pas la voix de l'utilisateur, ce qui offre aux utilisateurs une sécurité supplémentaire.
L’avènement de Moshi constitue non seulement une avancée technologique, mais annonce également une innovation majeure dans la manière d’interagir entre l’homme et la machine. Il nous montre les possibilités infinies des futurs systèmes de dialogue et nous permet d’entrevoir la brillante perspective d’un dialogue naturel, fluide et humain entre les humains et les machines. À mesure que cette technologie continue de se développer et de s’améliorer, nous pourrons bientôt parvenir à une communication véritablement sans obstacle et de haute qualité avec les machines, permettant ainsi de rejouer des scènes de films de science-fiction dans la vie réelle.
Adresse du modèle : https://huggingface.co/kyutai/moshiko-pytorch-bf16
Adresse papier : https://kyutai.org/Moshi.pdf
L'émergence de Moshi ouvre la voie à une future interaction homme-machine, et son expérience de conversation fluide et naturelle est passionnante. On pense qu’avec les progrès continus de la technologie, la communication entre les humains et les machines deviendra de plus en plus pratique et naturelle, pour finalement parvenir à une communication véritablement sans obstacle. Attendons et voyons !