Rapports de l'éditeur de downcodes : des équipes de recherche de l'Université Jiao Tong de Shanghai, de l'Université de Cambridge et du Geely Automobile Research Institute ont récemment lancé un nouveau système de synthèse vocale (TTS) appelé F5-TTS. Le système utilise une méthode sans autorégression, combinée à l'adaptation de flux et au transformateur de diffusion (DiT), qui simplifie efficacement le processus complexe du modèle TTS traditionnel et réalise des avancées significatives en termes de qualité de synthèse et de vitesse d'inférence. Comparé aux modèles TTS traditionnels, le F5-TTS est performant en termes de vitesse de traitement et de robustesse, ouvrant de nouvelles possibilités à la technologie de synthèse vocale.
Récemment, une équipe de recherche de l'Université Jiao Tong de Shanghai, de l'Université de Cambridge et du Geely Automobile Research Institute a lancé un nouveau système de synthèse vocale (TTS) appelé F5-TTS. La particularité de ce système est qu'il utilise une méthode sans autorégression qui combine l'adaptation de flux avec un transformateur de diffusion (DiT), simplifiant ainsi les étapes complexes du modèle TTS traditionnel.

Comme nous le savons tous, les modèles TTS traditionnels nécessitent souvent une modélisation complexe de la durée, un alignement des phonèmes et un codage de texte spécialisé, ce qui augmente la complexité du processus de synthèse. En particulier, les modèles précédents tels que E2TTS sont souvent confrontés à des problèmes tels qu'une convergence lente et un alignement imprécis du texte et de la parole, ce qui les rend difficiles à appliquer efficacement dans des scénarios du monde réel. L’émergence du F5-TTS vise précisément à résoudre ces défis.
Le principe de fonctionnement de F5-TTS est simple, tout d'abord, le texte saisi est traité via l'architecture ConvNeXt pour faciliter son alignement avec la parole. La séquence de caractères complétée est ensuite introduite dans le modèle avec une version bruitée de la parole d'entrée.
La formation du système s'appuie sur le transformateur de diffusion (DiT), qui mappe efficacement une distribution initiale simple à la distribution des données via une correspondance de flux. En outre, F5-TTS introduit également de manière innovante la stratégie Sway Sampling pendant l'inférence, qui peut donner la priorité aux premières étapes de flux de la phase d'inférence, améliorant ainsi l'alignement entre la parole générée et le texte saisi.
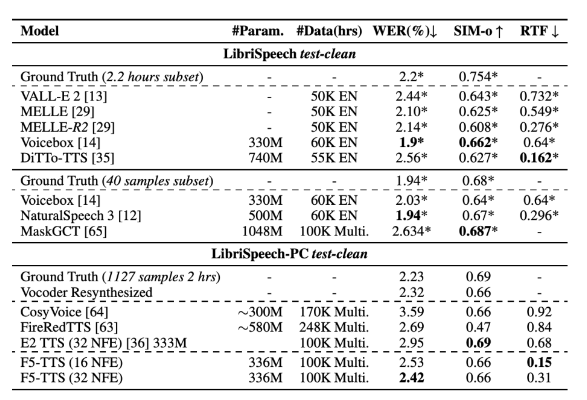
Selon les résultats de la recherche, le F5-TTS surpasse de nombreux systèmes TTS actuels en termes de qualité de synthèse et de vitesse d'inférence. Sur l'ensemble de données LibriSpeech-PC, le modèle a atteint un taux d'erreur sur les mots (WER) de 2,42 et un facteur temps réel (RTF) de 0,15 au moment de l'inférence, ce qui était nettement meilleur que le modèle de diffusion précédent E2TTS, qui fonctionnait mieux en termes de traitement. vitesse et Il y a des défauts de robustesse.
Dans le même temps, la stratégie Sway Sampling améliore considérablement le naturel et la compréhensibilité de la parole générée, permettant au modèle d'obtenir une génération fluide et expressive sans formation.
F5-TTS améliore la robustesse de l'alignement et la qualité de la synthèse en simplifiant le processus et en éliminant le besoin de prédiction de durée, d'alignement de phonèmes et de codage de texte explicite. En outre, les chercheurs ont également mis l’accent sur les considérations éthiques et ont proposé la nécessité d’établir des systèmes de filigrane et de détection pour empêcher toute utilisation abusive du modèle.
Entrée du projet : https://github.com/SWivid/F5-TTS
Souligner:
F5-TTS est un nouveau type de système de synthèse vocale autorégressive qui simplifie la complexité du modèle TTS traditionnel.
Le système utilise l'architecture ConvNeXt et DiT pour améliorer l'alignement du texte et de la parole et améliorer considérablement la qualité de la synthèse.
? Les chercheurs ont souligné la nécessité de prêter attention aux questions éthiques et ont suggéré l'introduction de mécanismes de tatouage et de détection pour prévenir les abus potentiels.
L'émergence du système F5-TTS a apporté de nouvelles avancées dans la technologie de synthèse vocale, et ses performances efficaces et ses processus simplifiés devraient être largement utilisés dans de nombreux domaines. Cependant, les questions éthiques nécessitent également une attention particulière et les recherches ultérieures devraient être consacrées à l'établissement d'un mécanisme de réglementation solide pour garantir le développement responsable de la technologie.