L'éditeur de Downcodes vous fera comprendre un phénomène inquiétant dans le domaine de l'IA : l'effondrement des modèles. Imaginez qu'un modèle d'IA soit comme un blogueur culinaire qui commence à manger la nourriture qu'il cuisine. Plus il en mange, plus il en devient accro, et la nourriture devient de plus en plus désagréable. c'est lorsque le modèle s'effondre. Cela se produit lorsqu’un modèle d’IA s’appuie trop sur les données qu’il génère, ce qui entraîne une baisse de la qualité du modèle, voire un échec complet. Cet article examinera les causes, les effets et comment éviter l'effondrement du modèle.
Une chose étrange s'est produite récemment dans le cercle de l'IA, comme un blogueur culinaire qui a soudainement commencé à manger la nourriture qu'il cuisinait, et plus il mangeait, plus il devenait accro et la nourriture devenait de plus en plus désagréable. Cette chose est assez effrayante à dire. Le terme professionnel s’appelle l’effondrement du modèle.
Qu'est-ce que l'effondrement du modèle ? échouer.
C'est comme un écosystème fermé. Le modèle d'IA est le seul être vivant dans ce système, et la nourriture qu'il produit est constituée de données. Au début, elle pouvait encore trouver quelques ingrédients naturels (données réelles), mais au fil du temps, elle a commencé à s'appuyer de plus en plus sur les ingrédients « artificiels » qu'elle produisait (données synthétiques). Le problème est que ces ingrédients « artificiels » sont déficients sur le plan nutritionnel et présentent certains des défauts du modèle lui-même. Si vous mangez trop, le « corps » du modèle d'IA s'effondrera et les choses générées deviendront de plus en plus scandaleuses.
Cet article étudie le phénomène d’effondrement du modèle et tente de répondre à deux questions clés :
L’effondrement du modèle est-il inévitable ? Le problème peut-il être résolu en mélangeant des données réelles et synthétiques ?
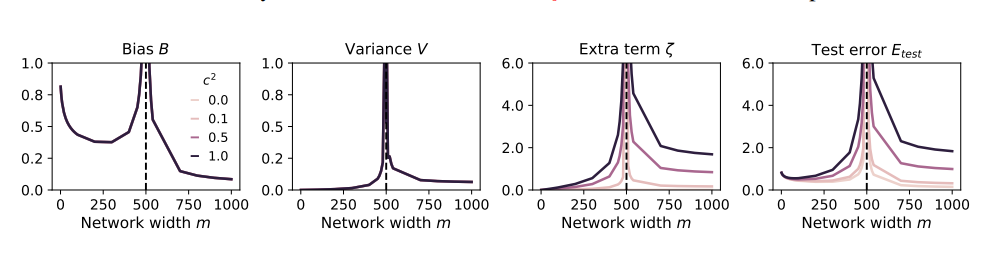
Plus le modèle est grand, plus il est facile de s'écraser ?
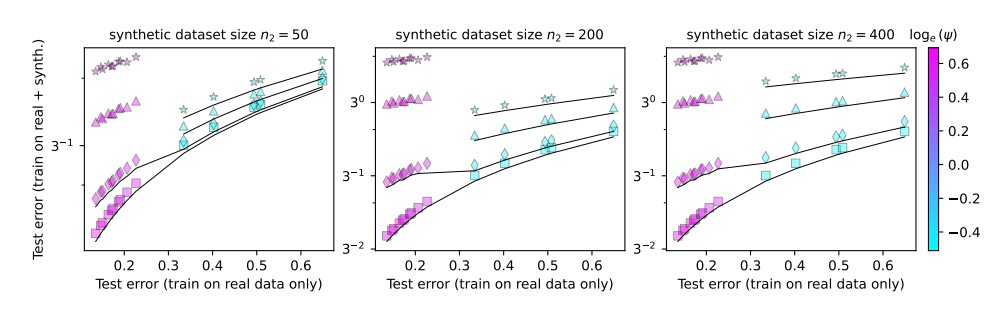
Afin d'étudier ces questions, les auteurs de l'article ont conçu une série d'expériences et utilisé un modèle de projection aléatoire pour simuler le processus de formation du réseau neuronal. Ils ont constaté que l’utilisation même d’une petite partie des données synthétiques (disons 1 %) pourrait entraîner l’effondrement du modèle. Pire encore, à mesure que la taille du modèle augmente, le phénomène d’effondrement du modèle devient plus grave.
C'est comme un blogueur culinaire qui a commencé à essayer toutes sortes d'ingrédients étranges afin d'attirer l'attention, mais qui a fini par avoir mal au ventre. Afin de récupérer les pertes, il ne pouvait qu'augmenter sa consommation de nourriture et manger des choses de plus en plus étranges. En conséquence, son estomac s'est aggravé et il a finalement dû quitter le monde de la nourriture et de la radiodiffusion.
Alors, comment éviter l’effondrement du modèle ?
Les auteurs de l'article ont fait quelques suggestions :
Donnez la priorité à l’utilisation de données réelles : les données réelles sont comme les aliments naturels, riches en nutriments et constituent la clé d’une croissance saine des modèles d’IA.
Utilisez les données synthétiques avec prudence : les données synthétiques sont comme les aliments artificiels. Même si elles peuvent compléter certains nutriments, vous ne devez pas trop vous y fier, sinon elles seront contre-productives.
Contrôlez la taille du modèle : plus le modèle est grand, plus l'appétit est grand et plus il est facile d'avoir mal au ventre. Lorsque vous utilisez des données synthétiques, contrôlez la taille du modèle pour éviter la suralimentation.
L'effondrement du modèle est un nouveau défi rencontré dans le processus de développement de l'IA. Il nous rappelle que tout en recherchant l'échelle et l'efficacité du modèle, nous devons également prêter attention à la qualité des données et à la santé du modèle. Ce n’est qu’ainsi que les modèles d’IA pourront continuer à se développer sainement et créer une plus grande valeur pour la société humaine.
Article : https://arxiv.org/pdf/2410.04840
Dans l'ensemble, l'effondrement du modèle est un problème digne d'attention dans le développement de l'IA. Nous devons traiter les données synthétiques avec prudence, prêter attention à la qualité des données réelles et contrôler l'échelle du modèle pour éviter le phénomène de « l'IA ». manger trop." J'espère que cette analyse pourra aider tout le monde à mieux comprendre l'effondrement des modèles et contribuer au développement sain de l'IA.