L'éditeur de Downcodes a appris que des scientifiques de Meta, de l'Université de Californie à Berkeley et de l'Université de New York ont développé conjointement une nouvelle technologie appelée « Thinking Preference Optimization » (TPO), visant à améliorer les performances des grands modèles de langage (LLM). Cette technologie améliore la capacité de « réflexion » de l'IA en permettant au modèle de générer une série d'étapes de réflexion avant de répondre à une question et en utilisant le modèle d'évaluation pour optimiser la qualité de la réponse finale, lui permettant ainsi de mieux performer dans diverses tâches. Différente de la technologie traditionnelle de « pensée en chaîne », la TPO a une gamme d'applications plus large, montrant notamment des avantages significatifs dans l'écriture créative, le raisonnement de bon sens, etc.
Récemment, des scientifiques de Meta, de l’Université de Californie à Berkeley et de l’Université de New York ont collaboré pour développer une nouvelle technologie appelée Thought Preference Optimization (TPO). L'objectif de cette technologie est d'améliorer les performances des grands modèles de langage (LLM) lors de l'exécution de diverses tâches, permettant à l'IA d'examiner plus attentivement ses réponses avant de répondre.
Les chercheurs affirment que la pensée devrait avoir une grande utilité. Par exemple, dans les tâches d’écriture créative, l’IA peut utiliser des processus de réflexion internes pour planifier la structure globale et le développement des personnages. Cette méthode est très différente de la précédente technologie d'incitation de type « Chaîne de pensée » (CoT). Ce dernier est principalement utilisé dans des tâches mathématiques et logiques, tandis que le TPO a une gamme d'applications plus large. Les chercheurs ont mentionné le nouveau modèle o1 d'OpenAI et estiment que le processus de réflexion est également utile pour un plus large éventail de tâches.
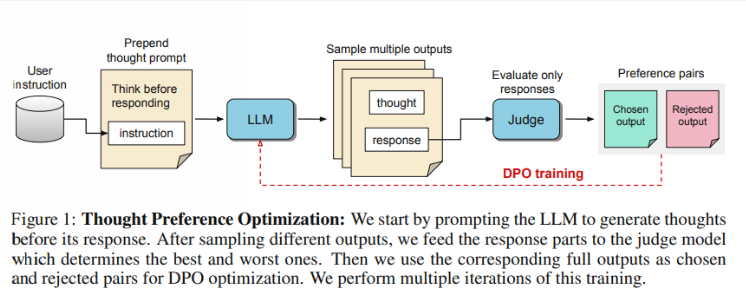
Alors, comment fonctionne le TPO ? Tout d’abord, le modèle génère une série d’étapes de réflexion avant de répondre à une question. Ensuite, il crée plusieurs résultats, qui sont ensuite évalués par un modèle d'évaluation uniquement sur la réponse finale, et non sur les étapes de réflexion elles-mêmes. Enfin, le modèle est formé grâce à l'optimisation des préférences de ces résultats d'évaluation. Les chercheurs espèrent que l’amélioration de la qualité des réponses pourra être obtenue en améliorant le processus de réflexion, afin que le modèle puisse acquérir des capacités de raisonnement plus efficaces dans l’apprentissage implicite.
Lors des tests, le modèle Llama38B utilisant TPO a obtenu de meilleurs résultats sur une instruction générale suivant un benchmark qu'une version sans inférence explicite. Dans les benchmarks AlpacaEval et Arena-Hard, les taux de réussite de TPO ont atteint respectivement 52,5 % et 37,3 %. Ce qui est encore plus intéressant, c’est que TPO progresse également dans des domaines qui ne nécessitent généralement pas de réflexion explicite, comme le bon sens, le marketing et la santé.
Cependant, l’équipe de recherche a noté que la configuration actuelle n’est pas adaptée aux problèmes mathématiques, car le TPO est en réalité moins performant que le modèle de base sur ces tâches. Cela suggère qu’une approche différente peut être nécessaire pour des tâches hautement spécialisées. Les recherches futures pourraient se concentrer sur des aspects tels que le contrôle de la durée des processus de pensée et l’impact de la pensée sur des modèles plus larges.
Souligner:
L'équipe de recherche a lancé « Thinking Preference Optimization » (TPO), qui vise à améliorer la capacité de réflexion de l'IA dans l'exécution des tâches.
?TPO utilise des modèles d'évaluation pour optimiser la qualité des réponses en laissant le modèle générer des étapes de réflexion avant de répondre.
Des tests ont montré que les TPO obtiennent de bons résultats dans des domaines tels que les connaissances générales et le marketing, mais de mauvais résultats dans les tâches mathématiques.
Dans l’ensemble, la technologie TPO ouvre une nouvelle direction pour l’amélioration des grands modèles de langage, et son potentiel dans l’amélioration des capacités de réflexion de l’IA mérite d’être attendu. Cependant, cette technologie présente également des limites et les recherches futures doivent encore améliorer et élargir son champ d’application. L'éditeur de Downcodes continuera de prêter attention aux derniers développements dans ce domaine et de proposer des rapports plus passionnants aux lecteurs.