L'éditeur de Downcodes a appris qu'Alibaba Damo Academy et l'Université Renmin de Chine ont conjointement ouvert un modèle de traitement de documents appelé mPLUG-DocOwl1.5. Le modèle peut comprendre le contenu d'un document sans reconnaissance OCR et fonctionne bien dans plusieurs tests de référence. Son cœur réside dans la méthode « d'apprentissage de structure unifié », qui améliore la compréhension structurelle des images de texte riche par le modèle multimodal de langage étendu (MLLM). . Le modèle a publié publiquement du code, des modèles et des ensembles de données sur GitHub, fournissant ainsi des ressources précieuses pour la recherche dans des domaines connexes.
L'Alibaba Damo Academy et l'Université Renmin de Chine ont récemment lancé conjointement un modèle de traitement de documents appelé mPLUG-DocOwl1.5. Ce modèle se concentre sur la compréhension du contenu des documents sans reconnaissance OCR et a obtenu des résultats dans plusieurs tests de référence de compréhension visuelle des documents.
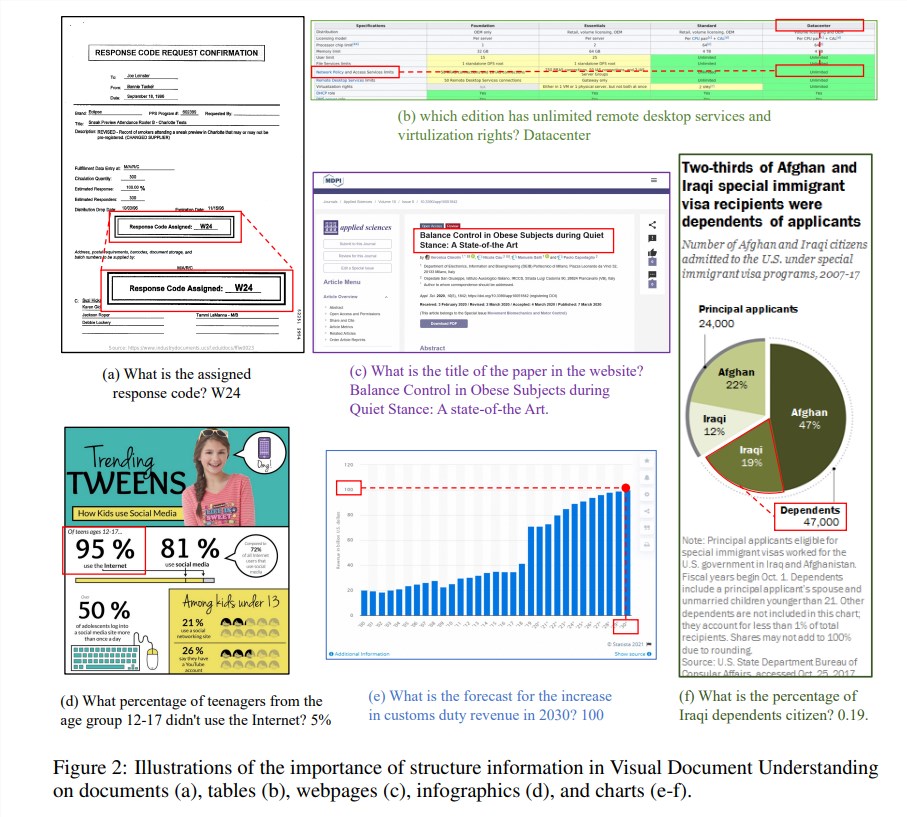
Les informations structurelles sont cruciales pour comprendre la sémantique des images riches en texte telles que les documents, les tableaux et les graphiques. Bien que les modèles multimodaux de langage étendu (MLLM) existants disposent de capacités de reconnaissance de texte, ils n'ont pas la capacité de comprendre la structure générale des images de documents en texte enrichi. Afin de résoudre ce problème, mPLUG-DocOwl1.5 souligne l'importance des informations structurelles dans la compréhension visuelle des documents et propose un « apprentissage de structure unifié » pour améliorer les performances du MLLM.
L'« apprentissage unifié de la structure » du modèle couvre 5 domaines : documents, pages Web, tableaux, graphiques et images naturelles, y compris les tâches d'analyse sensible à la structure et les tâches de positionnement de texte multi-granularité. Afin de mieux encoder les informations structurelles, les chercheurs ont conçu un module de conversion visuel-texte simple et efficace, H-Reducer, qui non seulement préserve les informations de mise en page, mais réduit également la longueur des caractéristiques visuelles en fusionnant les zones d'image adjacentes horizontalement par convolution, permettant de grands modèles de langage pour comprendre plus efficacement les images haute résolution.
De plus, pour prendre en charge l'apprentissage de la structure, l'équipe de recherche a créé DocStruct4M, un ensemble de formation complet contenant 4 millions d'échantillons basés sur des ensembles de données accessibles au public, qui contient des séquences de texte sensibles à la structure et des paires de cadres de délimitation de texte multi-granularité. Afin de stimuler davantage les capacités de raisonnement de MLLM dans le domaine des documents, ils ont également construit un ensemble de données de raisonnement affinant DocReason25K contenant 25 000 échantillons de haute qualité.
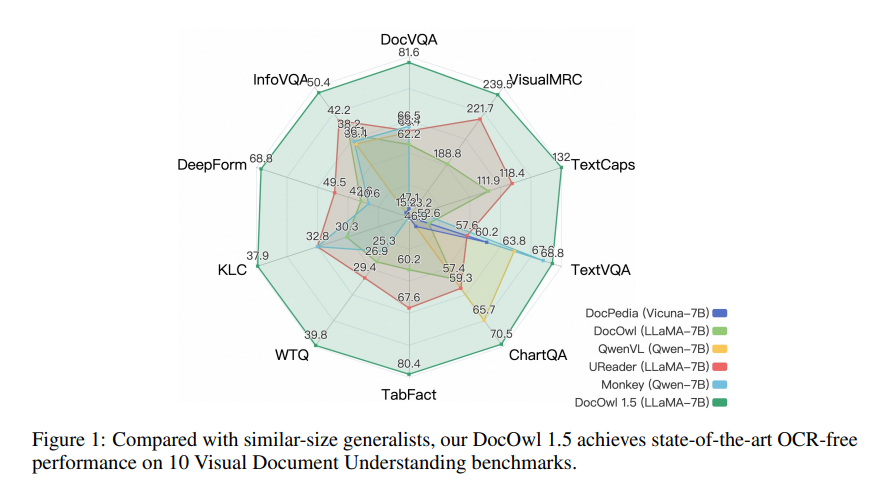
mPLUG-DocOwl1.5 adopte un cadre de formation en deux étapes, qui effectue d'abord un apprentissage de structure unifié, puis effectue un réglage fin multitâche dans plusieurs tâches en aval. Grâce à cette méthode de formation, mPLUG-DocOwl1.5 a atteint des performances de pointe dans 10 tests de compréhension de documents visuels, améliorant les performances SOTA du 7B LLM de plus de 10 points de pourcentage dans 5 tests.
Actuellement, le code, le modèle et l'ensemble de données de mPLUG-DocOwl1.5 ont été rendus publics sur GitHub.
Adresse du projet : https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
Adresse papier : https://arxiv.org/pdf/2403.12895
L'open source de mPLUG-DocOwl1.5 apporte de nouvelles possibilités à la recherche et à l'application dans le domaine de la compréhension visuelle des documents. Ses performances efficaces et ses méthodes d'accès pratiques méritent l'attention et l'utilisation des développeurs. On s’attend à ce que ce modèle puisse être utilisé dans des scénarios plus pratiques à l’avenir.