L'éditeur de Downcodes vous fera découvrir les derniers résultats des recherches de l'Ecole Polytechnique Fédérale de Lausanne (EPFL) ! Cette étude fournit une comparaison approfondie de deux méthodes traditionnelles de formation adaptative pour les grands modèles de langage (LLM) : l'apprentissage contextuel (ICL) et le réglage fin de l'instruction (IFT), et utilise le benchmark MT-Bench pour évaluer la capacité du modèle à suivre instructions. Les résultats de la recherche montrent que les deux méthodes ont leurs propres mérites dans différents scénarios, fournissant une référence précieuse pour la sélection des méthodes de formation LLM.
Une étude récente de l'École Polytechnique Fédérale de Lausanne (EPFL) en Suisse a comparé deux méthodes traditionnelles de formation adaptative pour les grands modèles linguistiques (LLM) : l'apprentissage contextuel (ICL) et la mise au point pédagogique (IFT). Les chercheurs ont utilisé le benchmark MT-Bench pour évaluer la capacité d'un modèle à suivre des instructions et ont constaté que les deux méthodes fonctionnaient mieux et moins bien dans certaines circonstances.
Des recherches ont montré que lorsque le nombre d’échantillons de formation disponibles est faible (par exemple pas plus de 50), les effets de l’ICL et de l’IFT sont très proches. Cela suggère qu'ICL peut être une alternative à IFT lorsque les données sont limitées.
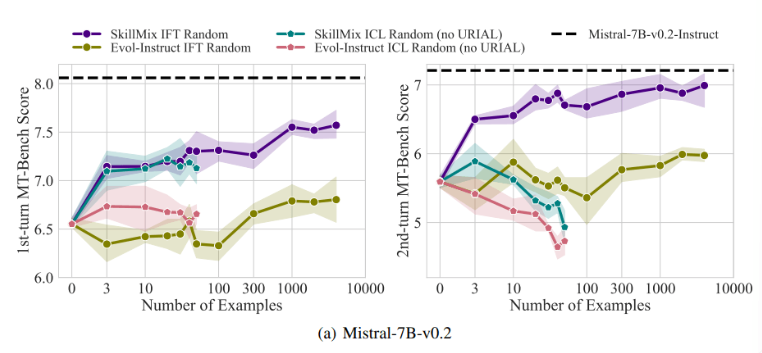
Cependant, à mesure que la complexité des tâches augmente, comme dans les scénarios de dialogue à plusieurs tours, les avantages de l'IFT deviennent évidents. Les chercheurs pensent que le modèle ICL a tendance à être surajusté au style d'un échantillon unique, ce qui entraîne de mauvaises performances lors du traitement de conversations complexes, voire pires que le modèle de base.
L'étude a également examiné la méthode URIAL, qui utilise seulement trois échantillons et instructions pour suivre des règles afin de former un modèle de langage de base. Bien que l'URIAL ait obtenu certains résultats, il existe encore un écart par rapport au modèle formé par l'IFT. Les chercheurs de l'EPFL ont amélioré les performances d'URIAL en améliorant la stratégie de sélection des échantillons, la rapprochant ainsi des modèles de réglage fin. Cela souligne l’importance de données de formation de haute qualité pour la formation ICL, IFT et des modèles de base.
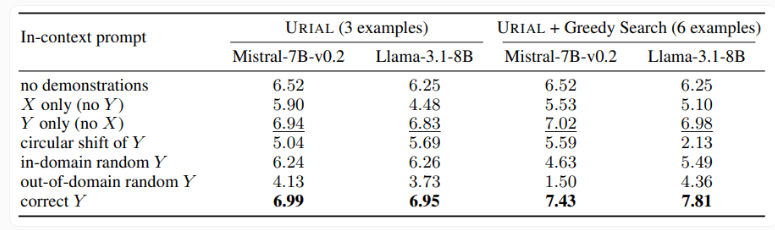
En outre, l’étude a également révélé que les paramètres de décodage ont un impact significatif sur les performances du modèle. Ces paramètres déterminent la manière dont le modèle génère du texte et sont essentiels à la fois pour le LLM de base et les modèles formés avec URIAL.
Les chercheurs notent que même le modèle de base peut suivre des instructions dans une certaine mesure, compte tenu des paramètres de décodage appropriés.
L’importance de cette étude est qu’elle révèle que l’apprentissage contextuel peut ajuster rapidement et efficacement les modèles de langage, en particulier lorsque les échantillons de formation sont limités. Mais pour les tâches complexes telles que les conversations à plusieurs tours, le réglage fin des commandes reste un meilleur choix.
À mesure que la taille de l'ensemble de données augmente, les performances de l'IFT continueront de s'améliorer, tandis que les performances de l'ICL se stabiliseront après avoir atteint un certain nombre d'échantillons. Les chercheurs soulignent que le choix entre ICL et IFT dépend de divers facteurs, tels que les ressources disponibles, le volume de données et les exigences spécifiques des applications. Quelle que soit la méthode que vous choisissez, des données d’entraînement de haute qualité sont cruciales.
Dans l’ensemble, cette étude de l’EPFL apporte de nouvelles informations sur la sélection de méthodes de formation pour les grands modèles de langage et ouvre la voie à de futures orientations de recherche. Choisir ICL ou IFT nécessite de peser le pour et le contre en fonction de la situation spécifique, et des données de haute qualité sont toujours la clé. Nous espérons que cette recherche pourra aider tout le monde à mieux comprendre et appliquer de grands modèles de langage.