L'éditeur de Downcodes vous fera découvrir Emu3, le dernier modèle mondial multimodal publié par le Zhiyuan Research Institute ! Emu3 s'appuie sur sa capacité unique de « prédiction du prochain jeton » pour atteindre des capacités révolutionnaires de compréhension et de génération dans trois modalités : texte, image et vidéo. Il peut non seulement générer des images de haute qualité et des vidéos fluides et naturelles, mais également effectuer une compréhension précise des images et une prédiction vidéo. Ses performances dépassent celles de nombreux modèles open source bien connus. La nature open source d'Emu3 injecte également une nouvelle vitalité dans le développement de l'IA multimodale. Explorons l'innovation technologique et le potentiel futur qui la sous-tend.
L'Institut de recherche Zhiyuan a officiellement publié son modèle mondial multimodal de nouvelle génération Emu3. Le plus grand point fort de ce modèle est qu'il peut prédire le prochain jeton dans trois modes différents : texte, image et vidéo.

En termes de génération d'images, Emu3 est capable de générer des images de haute qualité basées sur la prédiction visuelle de jetons. Cela signifie que les utilisateurs peuvent s'attendre à des résolutions flexibles et à une variété de styles.

En termes de génération vidéo, Emu3 fonctionne d'une manière complètement nouvelle. Contrairement à d'autres modèles qui génèrent des vidéos via le bruit, Emu3 génère directement des vidéos via une prédiction séquentielle. Cette avancée technologique rend la génération vidéo plus fluide et plus naturelle.

Sur des tâches telles que la génération d'images, la génération de vidéos et la compréhension du langage visuel, les performances d'Emu3 dépassent celles de nombreux modèles open source bien connus, tels que SDXL, LLaVA et OpenSora. Derrière lui se trouve un puissant tokeniseur visuel capable de convertir des vidéos et des images en jetons discrets. Cette conception fournit de nouvelles idées pour le traitement unifié du texte, des images et des vidéos.
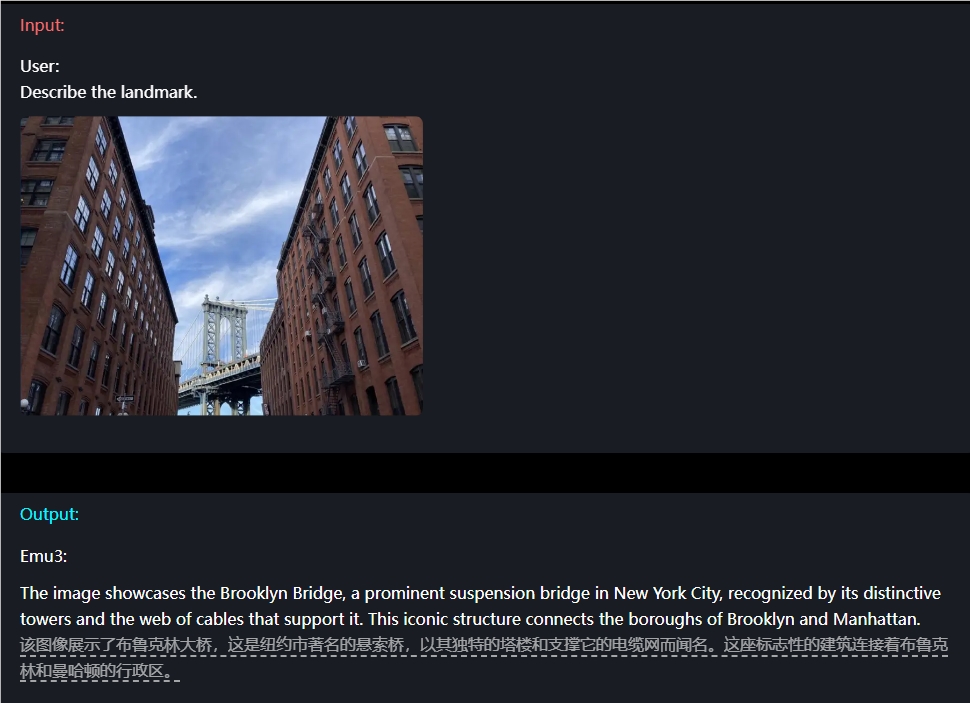
Par exemple, en termes de compréhension de l'image, les utilisateurs n'ont qu'à saisir une question et Emu3 peut décrire avec précision le contenu de l'image.
Emu3 dispose également de capacités de prédiction vidéo. Lorsqu'on lui donne une vidéo, Emu3 peut prédire ce qui va se passer ensuite en fonction du contenu existant. Cela lui permet de démontrer de fortes capacités de simulation d'environnements, de comportements humains et animaux, permettant aux utilisateurs de vivre une expérience interactive plus réaliste.

De plus, la flexibilité de conception d’Emu3 est rafraîchissante. Il peut être optimisé directement avec les préférences humaines afin que le contenu généré soit plus conforme aux attentes des utilisateurs. De plus, Emu3, en tant que modèle open source, a suscité de vives discussions au sein de la communauté technique. De nombreuses personnes pensent que cette réalisation va complètement changer le modèle de développement de l'IA multimodale.
URL du projet : https://emu.baai.ac.cn/about
Article : https://arxiv.org/pdf/2409.18869
Souligner:
Emu3 réalise une compréhension multimodale et la génération de texte, d'images et de vidéos grâce à la prédiction du prochain jeton.
Sur plusieurs tâches, les performances d'Emu3 ont dépassé celles de nombreux modèles open source bien connus, démontrant ainsi ses puissantes capacités.
La conception flexible et les fonctionnalités open source d'Emu3 offrent aux développeurs de nouvelles opportunités et devraient promouvoir l'innovation et le développement de l'IA multimodale.
L’émergence d’Emu3 marque une nouvelle étape dans le domaine de l’IA multimodale. Ses performances puissantes, sa conception flexible et ses fonctionnalités open source auront sans aucun doute un impact profond sur le développement futur de l’IA. Nous espérons qu'Emu3 sera utilisé dans davantage de domaines et apportera plus de commodité et de surprises à l'humanité !