L'éditeur de Downcodes a appris que l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin s'est associé à un certain nombre d'universités pour lancer un grand modèle de compréhension vidéo ultra-longue appelé Video-XL. Le modèle fonctionne bien dans le traitement de longues vidéos de plus de dix minutes, atteignant des positions de leader dans plusieurs benchmarks, démontrant de fortes capacités de généralisation et une efficacité de traitement. Video-XL utilise des modèles de langage pour compresser de longues séquences visuelles et atteint une précision de près de 95 % dans des tâches telles que « trouver une aiguille dans une botte de foin ». Il n'a besoin que d'une carte graphique avec 80 Go de mémoire vidéo pour traiter 2 048 images d'entrée. L’open source de ce modèle favorisera la coopération et le développement de la communauté mondiale de recherche sur la compréhension vidéo multimodale.
L'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin a uni ses forces avec des universités telles que l'Université Jiao Tong de Shanghai, l'Université Renmin de Chine, l'Université de Pékin et l'Université des postes et télécommunications de Pékin pour lancer un grand modèle de compréhension vidéo ultra-long appelé Video-XL. Ce modèle constitue une démonstration importante des capacités de base des grands modèles multimodaux et une étape clé vers l’intelligence artificielle générale (AGI). Par rapport aux grands modèles multimodaux existants, Video-XL affiche de meilleures performances et efficacité lors du traitement de longues vidéos de plus de 10 minutes.

Video-XL utilise les capacités natives des modèles de langage (LLM) pour compresser de longues séquences visuelles, conserve la capacité de comprendre de courtes vidéos et présente d'excellentes capacités de généralisation dans la compréhension de vidéos longues. Ce modèle se classe premier dans plusieurs tâches sur plusieurs benchmarks de compréhension de vidéos longues grand public. Video-XL atteint un bon équilibre entre efficacité et performances. Il n'a besoin que d'une carte graphique avec 80 Go de mémoire vidéo pour traiter 2048 images d'entrée, échantillonner des vidéos d'une heure et atteindre près de 95 % dans la tâche vidéo « aiguille dans la botte de foin ». % précision.
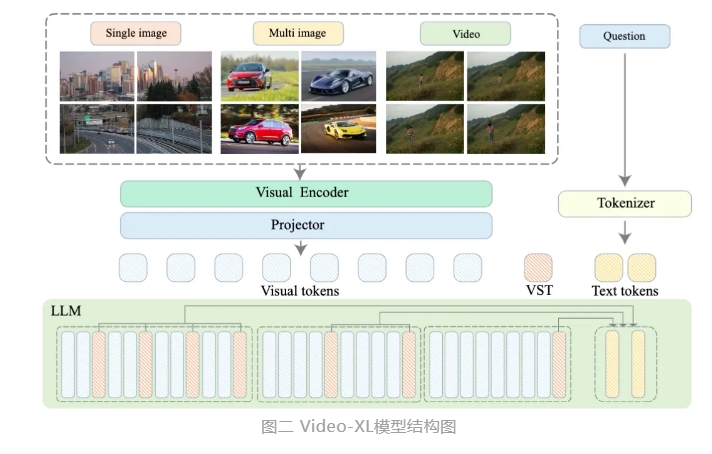
Video-XL devrait montrer une grande valeur d'application dans des scénarios d'application tels que le résumé de films, la détection d'anomalies vidéo et la détection de placement d'annonces, et devenir un assistant puissant pour la compréhension de vidéos longues. Le lancement de ce modèle marque une étape importante dans l'efficacité et la précision de la technologie de compréhension des vidéos longues, et fournit un support technique solide pour le traitement et l'analyse automatisés du contenu vidéo long à l'avenir.
Actuellement, le code modèle de Video-XL est open source pour promouvoir la coopération et le partage de technologies au sein de la communauté mondiale de recherche sur la compréhension vidéo multimodale.
Titre de l'article : Vidéo-XL : Modèle de langage à vision extra-longue pour la compréhension de la vidéo à l'échelle horaire
Lien papier : https://arxiv.org/abs/2409.14485
Lien du modèle : https://huggingface.co/sy1998/Video_XL
Lien du projet : https://github.com/VectorSpaceLab/Video-XL
L'open source de Video-XL apporte de nouvelles possibilités à la recherche et à l'application dans le domaine de la compréhension des vidéos longues. Son efficacité et sa précision favoriseront le développement ultérieur de technologies associées et fourniront un support technique pour davantage de scénarios d'application à l'avenir. Nous sommes impatients de voir des applications plus innovantes basées sur Video-XL à l'avenir.