L'éditeur de Downcodes vous présentera une dernière recherche de l'Université technique de Darmstadt en Allemagne. Cette étude a utilisé le problème de Bongard comme outil de test pour évaluer les performances du modèle d’image d’IA de pointe actuel dans des tâches simples de raisonnement visuel. Les résultats de la recherche sont surprenants. Même la précision des meilleurs modèles multimodaux comme GPT-4o est bien inférieure aux attentes, ce qui déclenche une réflexion approfondie sur les normes existantes d’évaluation des capacités visuelles de l’IA.
Les dernières recherches de l'Université technique de Darmstadt en Allemagne révèlent un phénomène qui incite à la réflexion : même les modèles d'images d'IA les plus avancés peuvent commettre des erreurs importantes lorsqu'ils sont confrontés à de simples tâches de raisonnement visuel. Les résultats de cette recherche proposent une nouvelle réflexion sur les normes d’évaluation de la capacité visuelle de l’IA.
L’équipe de recherche a utilisé le problème Bongard conçu par le scientifique russe Michail Bongard comme outil de test. Ce type de puzzle visuel se compose de 12 images simples réparties en deux groupes et nécessite d'identifier les règles qui distinguent les deux groupes. Cette tâche de raisonnement abstrait n'est pas difficile pour la plupart des gens, mais les performances du modèle d'IA étaient surprenantes.
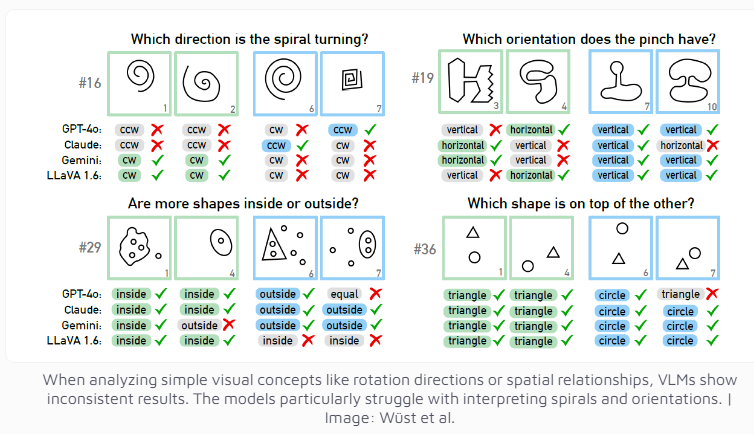
Même le modèle multimodal GPT-4o, actuellement considéré comme le plus avancé, n'a résolu avec succès que 21 énigmes visuelles sur 100. Les performances d'autres modèles d'IA bien connus tels que Claude, Gemini et LLaVA sont encore moins satisfaisantes. Ces modèles montrent des difficultés significatives à identifier les concepts visuels de base tels que les lignes verticales et horizontales, ou à juger la direction d'une spirale.
Les chercheurs ont constaté que même lorsque plusieurs choix étaient proposés, les performances du modèle d'IA ne s'amélioraient que légèrement. Ce n'est que sous des restrictions strictes sur le nombre de réponses possibles que GPT-4 et Claude ont amélioré leurs taux de réussite à 68 et 69 énigmes respectivement. Grâce à une analyse approfondie de quatre cas spécifiques, l’équipe de recherche a découvert que les systèmes d’IA rencontrent parfois des problèmes au niveau de la perception visuelle de base avant d’atteindre le stade de la réflexion et du raisonnement, mais que les raisons spécifiques sont encore difficiles à déterminer.
Ces recherches engagent également une réflexion sur les critères d’évaluation des systèmes d’IA. L'équipe de recherche a souligné : Pourquoi les modèles de langage visuel fonctionnent-ils bien sur les critères établis mais ont du mal à résoudre le problème apparemment simple de Bongard ? Dans quelle mesure ces critères sont-ils significatifs pour évaluer les capacités de raisonnement du monde réel ? Ces questions suggèrent que le système d'évaluation actuel de l'IA ? Il faudra peut-être le repenser pour mesurer plus précisément les capacités de raisonnement visuel de l’IA.
Cette recherche démontre non seulement les limites de la technologie actuelle de l’IA, mais ouvre également la voie au développement futur des capacités visuelles de l’IA. Cela nous rappelle que même si nous nous félicitons des progrès rapides de l’IA, nous devons aussi clairement comprendre qu’il reste encore des possibilités d’amélioration des capacités cognitives de base de l’IA.
Cette recherche montre clairement que les modèles d'IA ont encore beaucoup à faire en matière de raisonnement visuel, et que des méthodes d'évaluation plus efficaces et des percées technologiques sont nécessaires à l'avenir pour améliorer les capacités cognitives de l'IA. L'éditeur de Downcodes continuera de prêter attention aux progrès de pointe dans le domaine de l'IA et vous proposera des rapports plus passionnants.