Les grands modèles de langage (LLM) sont de plus en plus utilisés, mais leur grand nombre de paramètres entraîne d'énormes besoins en ressources informatiques. Afin de résoudre ce problème et d’améliorer l’efficacité et la précision du modèle dans différents environnements de ressources, les chercheurs continuent d’explorer de nouvelles méthodes. Cet article présentera le framework Flextron développé conjointement par des chercheurs de NVIDIA et de l'Université du Texas à Austin. Ce framework est conçu pour permettre un déploiement flexible de modèles d'IA sans ajustement supplémentaire et résoudre efficacement les problèmes d'inefficacité des méthodes traditionnelles. L'éditeur de Downcodes expliquera en détail les innovations du framework Flextron et ses avantages dans des environnements à ressources limitées.
Dans le domaine de l'intelligence artificielle, les grands modèles linguistiques (LLM) tels que GPT-3 et Llama-2 ont fait des progrès significatifs et peuvent comprendre et générer avec précision le langage humain. Cependant, le grand nombre de paramètres de ces modèles les oblige à nécessiter une grande quantité de ressources informatiques lors de la formation et du déploiement, ce qui pose un défi dans des environnements aux ressources limitées.
Entrée papier : https://arxiv.org/html/2406.10260v1
Traditionnellement, afin d’atteindre un équilibre entre efficacité et précision sous différentes contraintes de ressources informatiques, les chercheurs doivent former plusieurs versions différentes du modèle. Par exemple, la famille de modèles Llama-2 comprend différentes variantes avec 7 milliards, 1,3 milliard et 700 millions de paramètres. Cependant, cette méthode nécessite une grande quantité de données et de ressources informatiques et n’est pas très efficace.
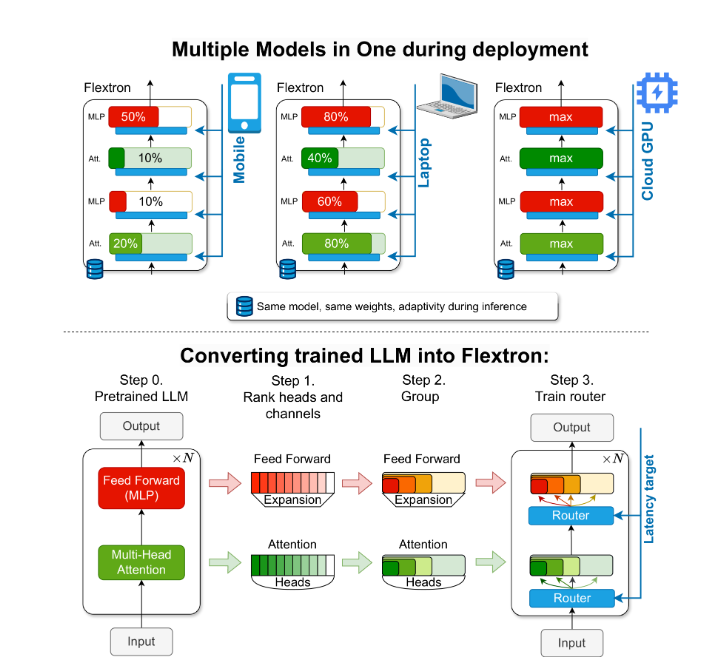
Pour résoudre ce problème, des chercheurs de NVIDIA et de l'Université du Texas à Austin ont introduit le framework Flextron. Flextron est une nouvelle architecture de modèle flexible et un cadre d'optimisation post-formation qui prend en charge le déploiement adaptatif de modèles sans nécessiter de réglages supplémentaires, résolvant ainsi les problèmes d'inefficacité des méthodes traditionnelles.
Flextron transforme les LLM pré-entraînés en modèles élastiques grâce à des méthodes de formation efficaces en matière d'échantillons et à des algorithmes de routage avancés. Cette structure présente une conception élastique imbriquée qui permet des ajustements dynamiques pendant l'inférence pour répondre à des objectifs spécifiques de latence et de précision. Cette adaptabilité permet d'utiliser un seul modèle pré-entraîné dans une variété de scénarios de déploiement, réduisant considérablement le besoin de plusieurs variantes de modèle.
L'évaluation des performances de Flextron montre qu'il surpasse en termes d'efficacité et de précision par rapport à plusieurs modèles formés de bout en bout et à d'autres réseaux élastiques de pointe. Par exemple, Flextron fonctionne bien sur plusieurs benchmarks tels que ARC-easy, LAMBADA, PIQA, WinoGrande, MMLU et HellaSwag, en utilisant seulement 7,63 % des marqueurs d'entraînement dans la pré-formation d'origine, économisant ainsi beaucoup de ressources informatiques et de temps. .
Le cadre Flextron comprend également des couches élastiques de perceptron multicouche (MLP) et d'attention multi-têtes élastiques (MHA), améliorant encore son adaptabilité. La couche élastique MHA utilise efficacement la mémoire disponible et la puissance de traitement en sélectionnant un sous-ensemble de têtes d'attention sur la base des données d'entrée, et est particulièrement adaptée aux scénarios avec des ressources informatiques limitées.
Souligner:
? Le framework Flextron prend en charge le déploiement flexible du modèle d'IA sans ajustement supplémentaire.
Grâce à une formation efficace des échantillons et à des algorithmes de routage avancés, l'efficacité et la précision du modèle sont améliorées.
La couche d'attention élastique multi-têtes optimise l'utilisation des ressources et est particulièrement adaptée aux environnements dotés de ressources informatiques limitées.
Ce rapport espère présenter l'importance et l'innovation du cadre Flextron aux élèves du secondaire d'une manière facile à comprendre.
Dans l'ensemble, le framework Flextron fournit une solution efficace et innovante au problème du déploiement de grands modèles de langage dans des environnements aux ressources limitées. Son architecture flexible et sa méthode de formation efficace en matière d'échantillons lui confèrent des avantages significatifs dans les applications pratiques et ouvrent une nouvelle direction pour le développement ultérieur de la technologie de l'intelligence artificielle. L'éditeur de Downcodes espère que cet article pourra aider tout le monde à mieux comprendre les idées fondamentales et les contributions techniques du framework Flextron.