L'éditeur de Downcodes vous fera découvrir une technologie innovante qui améliore l'efficacité des grands modèles de langage (LLM) - Q-Sparse. Les puissantes capacités de traitement du langage naturel des LLM ont attiré beaucoup d’attention, mais leur coût de calcul élevé et leur empreinte mémoire ont toujours constitué des goulots d’étranglement dans les applications pratiques. Q-Sparse utilise une méthode intelligente de sparsification pour améliorer considérablement l'efficacité de l'inférence tout en garantissant les performances du modèle, ouvrant ainsi la voie à une application généralisée des LLM. Cet article explorera en profondeur la technologie de base, les avantages et les résultats de la vérification expérimentale de Q-Sparse, montrant son énorme potentiel pour améliorer l'efficacité des LLM.
Dans le monde de l’intelligence artificielle, les grands modèles de langage (LLM) sont connus pour leurs capacités supérieures de traitement du langage naturel. Cependant, le déploiement de ces modèles dans des applications pratiques se heurte à d’énormes défis, principalement en raison de leur coût de calcul élevé et de leur empreinte mémoire lors de la phase d’inférence. Pour résoudre ce problème, les chercheurs ont étudié comment améliorer l’efficacité des LLM. Récemment, une méthode appelée Q-Sparse a attiré une grande attention.
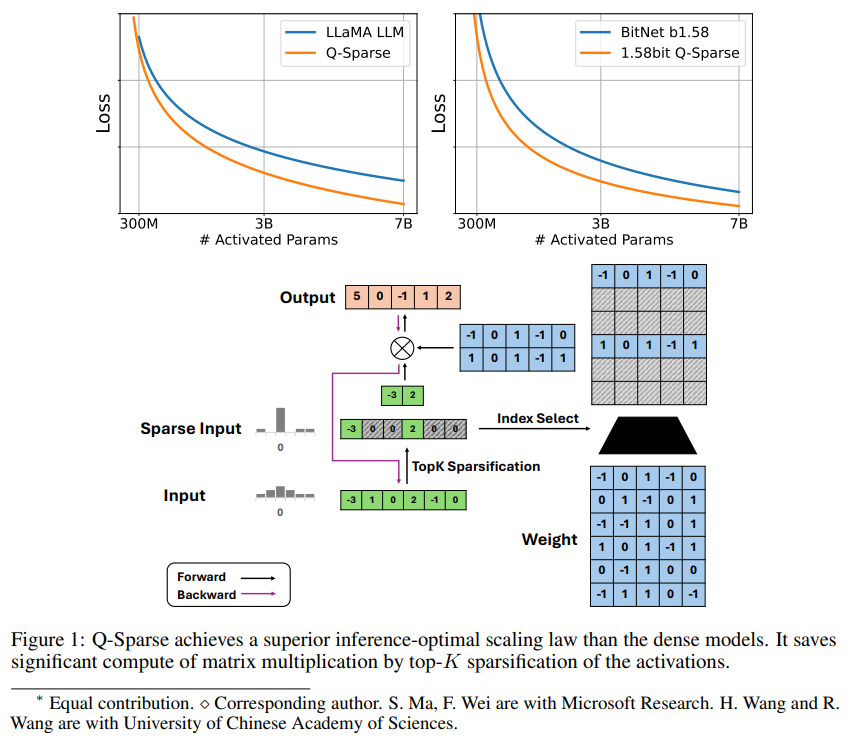
Q-Sparse est une méthode simple mais efficace qui permet d'obtenir une activation totalement clairsemée de LLM en appliquant une sparsification top-K dans les activations et un estimateur de passage dans la formation. Cela signifie des améliorations significatives de l’efficacité lors de l’inférence. Les principaux résultats de la recherche comprennent :
Q-Sparse atteint une efficacité d'inférence plus élevée tout en conservant des résultats comparables aux LLM de base.
Une règle d'expansion optimale inférentielle adaptée aux LLM à activation clairsemée est proposée.
Q-Sparse fonctionne dans différents contextes, y compris la formation à partir de zéro, la formation continue de LLM disponibles dans le commerce et le réglage fin.
Q-Sparse fonctionne avec une précision totale et des LLM 1 bit (par exemple BitNet b1.58).
Avantages de l’activation clairsemée
La parcimonie améliore l'efficacité des LLM de deux manières : premièrement, la parcimonie peut réduire la quantité de calcul de multiplication matricielle, car aucun élément ne sera calculé. Deuxièmement, la parcimonie peut réduire la quantité de transmission d'entrée/sortie (E/S), ce qui ; C'est le principal goulot d'étranglement dans la phase d'inférence des LLM.
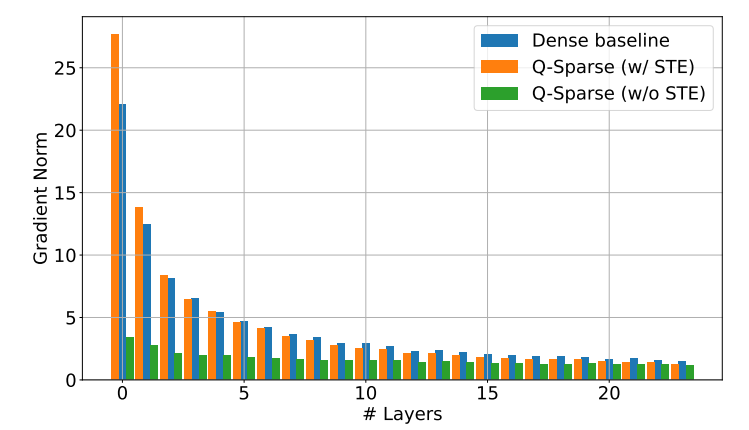
Q-Sparse atteint une parcimonie totale d'activations en appliquant une fonction de sparsification top-K dans chaque projection linéaire. Pour la rétropropagation, le gradient de l'activation est calculé à l'aide d'un estimateur pass-through. De plus, la fonction ReLU au carré est introduite pour améliorer encore la rareté de l'activation.
Vérification expérimentale
Les chercheurs ont étudié la loi d’expansion des LLM peu activés à travers une série d’expériences d’expansion et sont parvenus à des découvertes intéressantes :
Les performances des modèles d’activation clairsemés s’améliorent avec l’augmentation de la taille du modèle et du rapport de parcimonie.
Étant donné un rapport de parcimonie S fixe, les performances d'un modèle d'activation clairsemé s'adaptent à la taille du modèle N selon une loi de puissance.
Étant donné un paramètre N fixe, les performances du modèle d'activation clairsemée évoluent de façon exponentielle avec le rapport de parcimonie S.
Q-Sparse peut être utilisé non seulement pour une formation à partir de zéro, mais également pour une formation continue et un réglage précis des LLM disponibles dans le commerce. Dans les paramètres de formation continue et de réglage fin, les chercheurs ont utilisé la même architecture et le même processus de formation que la formation à partir de zéro, la seule différence était d'initialiser le modèle avec des poids pré-entraînés et de permettre aux fonctions clairsemées de poursuivre la formation.
Les chercheurs explorent l'utilisation de Q-Sparse avec des LLM 1 bit (tels que BitNet b1.58) et des experts mixtes (MoE) pour améliorer encore l'efficacité des LLM. De plus, ils travaillent à rendre Q-Sparse compatible avec le mode batch, ce qui offrira plus de flexibilité pour la formation et l'inférence des LLM.
L'émergence de la technologie Q-Sparse fournit de nouvelles idées pour résoudre le problème d'efficacité des LLM. Elle présente un grand potentiel en matière de réduction des coûts de calcul et de l'utilisation de la mémoire, et devrait promouvoir l'application des LLM dans davantage de domaines. On pense que d’autres résultats de recherche basés sur Q-Sparse apparaîtront à l’avenir pour améliorer encore les performances et l’efficacité des LLM.