Ces dernières années, les grands modèles multimodaux se sont développés rapidement et de nombreux excellents modèles ont vu le jour. Cependant, la plupart des modèles existants reposent sur des encodeurs visuels, qui souffrent de problèmes de biais d’induction visuelle causés par la séparation des entraînements, limitant ainsi l’efficacité et les performances. L'éditeur de Downcodes vous propose un nouveau modèle de langage visuel EVE lancé par l'Institut de recherche Zhiyuan en collaboration avec des universités. Il adopte une architecture sans codeur et a obtenu d'excellents résultats dans plusieurs tests de référence, offrant de nouvelles opportunités pour le développement de modèles multimodaux. .des idées.
Récemment, des progrès significatifs ont été réalisés dans la recherche et l’application de grands modèles multimodaux. Des sociétés étrangères telles que OpenAI, Google, Microsoft, etc. ont lancé une série de modèles avancés, et des institutions nationales telles que Zhipu AI et Step Star ont réalisé des percées dans ce domaine. Ces modèles s'appuient généralement sur des encodeurs visuels pour extraire des caractéristiques visuelles et les combiner avec de grands modèles de langage, mais il existe un problème de biais d'induction visuelle causé par la séparation de la formation, qui limite l'efficacité du déploiement et les performances des grands modèles multimodaux.
Afin de résoudre ces problèmes, l'Institut de recherche Zhiyuan, en collaboration avec l'Université de technologie de Dalian, l'Université de Pékin et d'autres universités, a lancé une nouvelle génération de modèle de langage visuel sans codeur EVE. EVE intègre la représentation, l'alignement et l'inférence visuo-linguistiques dans une architecture de décodeur pure unifiée grâce à des stratégies de formation raffinées et une supervision visuelle supplémentaire. En utilisant des données publiques, EVE fonctionne bien sur plusieurs tests visuo-linguistiques, se rapprochant, voire surpassant les méthodes multimodales traditionnelles basées sur des encodeurs.
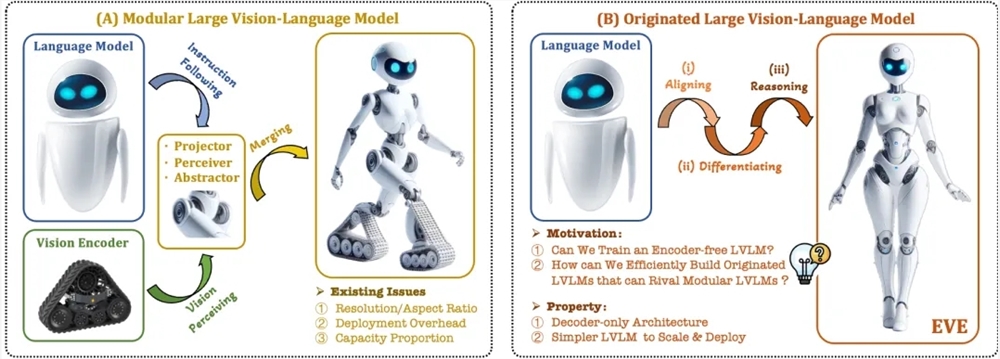
Les principales fonctionnalités d'EVE incluent :
Modèle de langage visuel natif : supprime l'encodeur visuel et gère n'importe quel rapport hauteur/largeur d'image, ce qui est nettement meilleur que le même type de modèle Fuyu-8B.
Faibles coûts de données et de formation : la pré-formation utilise des données publiques telles que OpenImages, SAM et LAION, et la durée de formation est courte.
Exploration transparente et efficace : fournit un chemin de développement efficace et transparent pour les architectures multimodales natives de décodeurs purs.
Structure du modèle :
Couche d'intégration de correctifs : obtenez la carte des caractéristiques 2D de l'image via une seule couche de convolution et une couche de regroupement moyenne pour améliorer les caractéristiques locales et les informations globales.
Couche d'alignement des correctifs : intégrez des fonctionnalités visuelles de réseau multicouche pour obtenir un alignement précis avec la sortie de l'encodeur visuel.
Stratégie de formation :
Étape de pré-formation guidée par de grands modèles de langage : établir le lien initial entre vision et langage.
Étape de pré-formation générative : Améliorer la capacité du modèle à comprendre le contenu visuo-linguistique.
Phase de mise au point supervisée : régule la capacité du modèle à suivre les instructions linguistiques et à apprendre des modèles de conversation.
Analyse quantitative : EVE fonctionne bien dans plusieurs tests de langage visuel et est comparable à une variété de modèles de langage visuel traditionnels basés sur un encodeur. Malgré les difficultés liées à la réponse précise à des instructions spécifiques, grâce à une stratégie de formation efficace, EVE atteint des performances comparables aux modèles de langage visuel dotés de bases d'encodeurs.
EVE a démontré le potentiel des modèles de langage visuel natifs sans encodeur. À l'avenir, il pourrait continuer à promouvoir le développement de modèles multimodaux grâce à de nouvelles améliorations des performances, à l'optimisation des architectures sans encodeur et à la construction de modèles multimodaux natifs. modèles.
Adresse papier : https://arxiv.org/abs/2406.11832
Code du projet : https://github.com/baaivision/EVE
Adresse du modèle : https://huggingface.co/BAAI/EVE-7B-HD-v1.0
Dans l’ensemble, l’émergence du modèle EVE offre de nouvelles orientations et possibilités pour le développement de grands modèles multimodaux. Sa stratégie de formation efficace et ses excellentes performances méritent l’attention. Nous attendons avec impatience que le futur modèle EVE puisse démontrer ses puissantes capacités dans davantage de domaines.