Dans la communication vocale en temps réel, changer le timbre du locuteur sans affecter la sémantique et la prosodie a toujours été un problème technique. L'éditeur de Downcodes présentera aujourd'hui une technologie révolutionnaire - StreamVC, qui peut modifier le timbre de la voix du locuteur en temps réel tout en conservant le contenu et le rythme de la voix. Elle est adaptée aux plates-formes mobiles et offre de nouvelles possibilités de communication et d'anonymisation de la voix. La faible latence, la synthèse vocale de haute qualité et la stabilité de la tonalité de StreamVC lui confèrent des avantages significatifs dans le domaine des communications en temps réel.
Dans un monde de communication en temps réel, qu’il s’agisse d’un appel téléphonique ou d’une vidéoconférence, le son est un outil important pour nous exprimer. Mais avez-vous déjà pensé à ce qui se passerait si nous pouvions modifier le timbre de la voix d'un locuteur en temps réel sans affecter le contenu et le rythme de la langue ? L'émergence de la technologie StreamVC nous permet de le faire ?
StreamVC est une solution innovante de conversion vocale qui correspond au timbre de la voix cible tout en conservant le contenu et la prosodie de la voix source. Contrairement aux méthodes traditionnelles, StreamVC produit la forme d'onde résultante avec une faible latence sur le signal d'entrée, même sur les plates-formes mobiles, ce qui le rend adapté aux scénarios de communication en temps réel tels que les appels téléphoniques et les vidéoconférences, ainsi qu'à l'anonymisation vocale dans ces scénarios.
Points forts techniques :
En temps réel : StreamVC est capable d'effectuer 70,8 millisecondes d'inférence à faible latence sur les appareils mobiles.
Synthèse vocale de haute qualité : utilisez l'architecture et la stratégie de formation du codec audio neuronal SoundStream pour obtenir une synthèse vocale légère et de haute qualité.
Stabilité de la hauteur : en introduisant des informations blanchies sur la fréquence fondamentale (f0), la cohérence de la hauteur est améliorée sans fuite des informations de timbre du haut-parleur source.
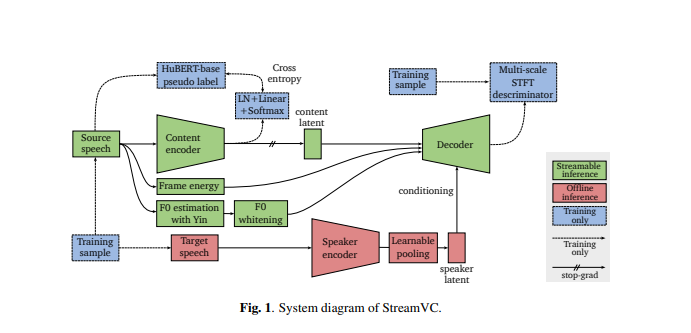
La conception de StreamVC est inspirée de Soft-VC et SoundStream. Il utilise des unités vocales discrètes extraites par le modèle HuBERT comme cibles de prédiction pour le réseau de codage de contenu. L'architecture et la stratégie de formation de l'encodeur et du décodeur de contenu sont conçues à partir du codec audio neuronal SoundStream pour obtenir une synthèse audio causale de haute qualité.
StreamVC a été comparé aux technologies existantes sur plusieurs critères, notamment le naturel, la compréhensibilité, la similarité des locuteurs et la cohérence du ton. Les résultats expérimentaux montrent que StreamVC réussit bien à préserver la tonalité de la langue source et est comparable au modèle affiné en termes de similarité des locuteurs.
StreamVC prouve qu'une conversion sonore efficace avec une faible latence sur les appareils mobiles est tout à fait réalisable. Les unités vocales logicielles dérivées de HuBERT peuvent être apprises grâce à une architecture de réseau neuronal convolutionnel causal diffusable, et l'injection d'informations f0 blanchies dans le décodeur est cruciale pour fournir une sortie de haute qualité.
Adresse papier : https://arxiv.org/pdf/2401.03078
L'émergence de la technologie StreamVC a apporté de nouvelles possibilités de communication vocale en temps réel. Ses capacités de conversion vocale à faible latence et de haute qualité favoriseront l'application de la technologie vocale dans davantage de domaines. Je pense qu'à l'avenir, StreamVC jouera un rôle plus important dans l'anonymisation de la voix, les effets spéciaux vocaux, etc. Dans l’attente de applications plus innovantes basées sur StreamVC !