Récemment, le laboratoire d'intelligence artificielle de Tencent a lancé un nouveau modèle appelé VTA-LDM, conçu pour convertir efficacement le contenu vidéo en un son sémantiquement et temporellement cohérent. La technologie de base de ce modèle réside dans « l'alignement implicite », qui correspond parfaitement au contenu audio et vidéo généré, améliorant considérablement la qualité et les scénarios d'application de la génération audio. L'éditeur de Downcodes vous amènera à comprendre en profondeur les innovations et les perspectives d'application du modèle VTA-LDM.
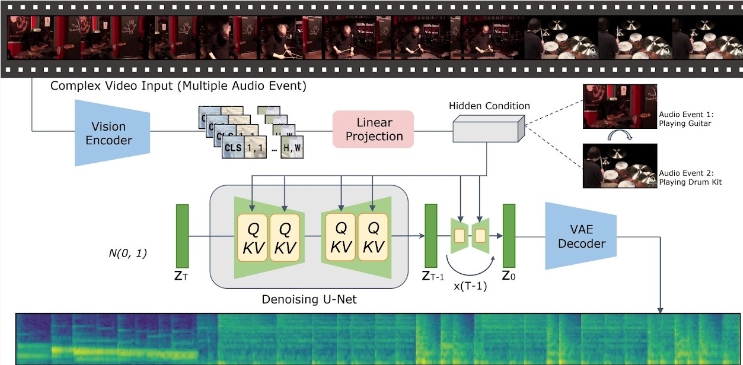
Avec les progrès significatifs de la technologie de génération texte-vidéo, la manière de générer un contenu audio sémantiquement et temporellement cohérent à partir d’une entrée vidéo est devenue un sujet brûlant parmi les chercheurs. Récemment, l'équipe de recherche du Tencent Artificial Intelligence Laboratory a lancé un nouveau modèle appelé « Implicitly Aligned Video to Audio Generation » - VTA-LDM, qui vise à fournir des solutions efficaces de génération audio.
Entrée du projet : https://top.aibase.com/tool/vta-ldm
L'idée principale du modèle VTA-LDM est de faire correspondre sémantiquement et temporellement le contenu audio et vidéo généré grâce à une technologie d'alignement implicite. Cette méthode améliore non seulement la qualité de la génération audio, mais élargit également les scénarios d'application de la technologie de génération vidéo. L'équipe de recherche a mené une exploration approfondie de la conception du modèle et a combiné divers moyens techniques pour garantir l'exactitude et la cohérence de l'audio généré.
La recherche se concentre sur trois aspects clés : les encodeurs visuels, les intégrations auxiliaires et les techniques d'augmentation des données. L’équipe de recherche a d’abord établi un modèle de base et mené un grand nombre d’expériences d’ablation sur cette base pour évaluer l’impact de différents encodeurs visuels et intégrations auxiliaires sur l’effet de génération. Les résultats de ces expériences montrent que le modèle fonctionne bien en termes de qualité de génération et d'alignement simultané de la vidéo et de l'audio, atteignant l'avant-garde de la technologie actuelle.
En termes d'inférence, les utilisateurs n'ont qu'à placer les clips vidéo dans le répertoire de données spécifié et à exécuter le script d'inférence fourni pour générer le contenu audio correspondant. L'équipe de recherche fournit également un ensemble d'outils pour aider les utilisateurs à fusionner l'audio généré avec la vidéo originale, améliorant ainsi encore la commodité de l'application.
Le modèle VTA-LDM propose actuellement plusieurs versions de modèle différentes pour répondre à différents besoins de recherche. Ces modèles couvrent des modèles de base et une variété de modèles améliorés, visant à offrir aux utilisateurs des choix flexibles pour s'adapter à diverses expériences et scénarios d'application.
Le lancement du modèle VTA-LDM marque un progrès important dans le domaine de la génération vidéo vers audio. Les chercheurs espèrent utiliser ce modèle pour promouvoir le développement de technologies connexes et créer des possibilités d'application plus riches.
## Points forts:
L'émergence du modèle VTA-LDM a apporté de nouvelles avancées dans le domaine de la génération vidéo et audio. Ses méthodes de fonctionnement efficaces et pratiques ainsi que ses fonctions puissantes laissent présager des perspectives d'application plus larges dans le futur. On pense qu’avec le développement continu de la technologie, le modèle VTA-LDM jouera un rôle important dans davantage de domaines.