L'éditeur de downcodes apporte de grandes nouvelles ! La technologie révolutionnaire d'accélération Transformer FlashAttention-3 est officiellement lancée ! Cette technologie révolutionnera la vitesse d'inférence et le coût des grands modèles de langage (LLM), permettant ainsi des améliorations d'efficacité sans précédent. La vitesse est augmentée de 1,5 à 2 fois, le fonctionnement à faible précision (FP8) maintient une haute précision et les capacités de traitement de texte long sont considérablement améliorées, ce qui apportera de nouvelles possibilités aux applications d'IA ! Examinons de plus près cette technologie révolutionnaire.
La nouvelle technologie d'accélération Transformer FlashAttention-3 est sortie. Il ne s'agit pas seulement d'une mise à niveau, elle annonce une forte augmentation de la vitesse d'inférence et une chute du coût de nos grands modèles de langage (LLM) !
Parlons d'abord de ce FlashAttention-3 Par rapport à la version précédente, il s'agit simplement d'un changement de fusil de chasse :
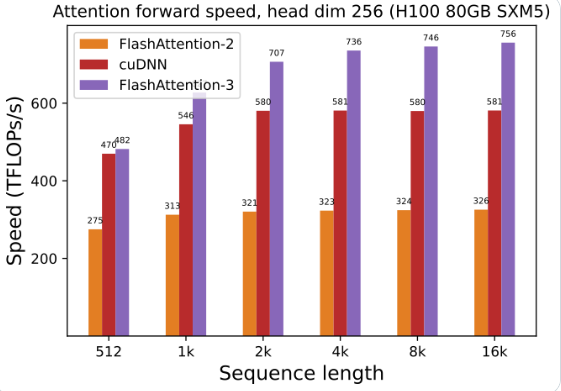
L'utilisation du GPU a été grandement améliorée : en utilisant FlashAttention-3 pour entraîner et exécuter de grands modèles de langage, la vitesse est directement doublée, 1,5 à 2 fois plus rapide. Cette efficacité est incroyable !
Faible précision, hautes performances : il peut également fonctionner avec des nombres de faible précision (FP8) tout en conservant la précision. Qu'est-ce que cela signifie : un coût réduit sans compromettre les performances !
Le traitement de textes longs est un jeu d'enfant : FlashAttention-3 améliore considérablement la capacité du modèle d'IA à traiter des textes longs, ce qui était inimaginable auparavant.
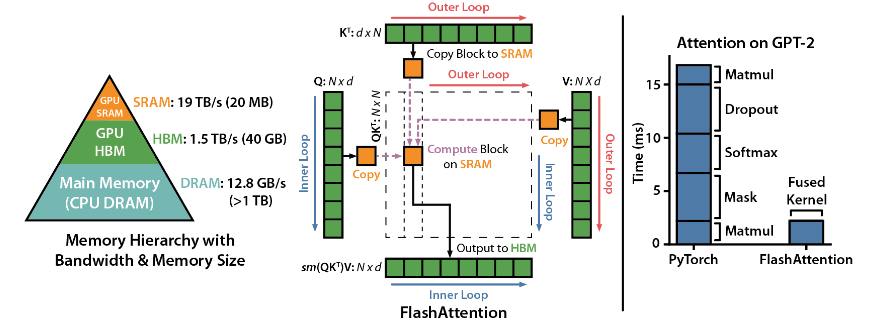
FlashAttention est une bibliothèque open source développée par Dao-AILab. Elle est basée sur deux articles lourds et fournit une implémentation optimisée du mécanisme d'attention dans les modèles d'apprentissage profond. Cette bibliothèque est particulièrement adaptée au traitement d'ensembles de données à grande échelle et de longues séquences. Il existe une relation linéaire entre la consommation de mémoire et la longueur de la séquence, bien plus efficace que la relation quadratique traditionnelle.
Points forts techniques :
Support technologique avancé : attention locale, rétropropagation déterministe, ALiBi, etc. Ces technologies portent la puissance d'expression et la flexibilité du modèle à un niveau supérieur.
Optimisation du GPU Hopper : FlashAttention-3 a spécialement optimisé sa prise en charge du GPU Hopper et les performances ont été améliorées de plus d'un point et demi.
Facile à installer et à utiliser : prend en charge CUDA11.6 et PyTorch1.12 ou supérieur, facile à installer avec la commande pip sous le système Linux. Bien que les utilisateurs Windows puissent avoir besoin de plus de tests, cela vaut vraiment la peine d'essayer.
Fonctions principales :
Performances efficaces : l'algorithme optimisé réduit considérablement les besoins en calcul et en mémoire, en particulier pour le traitement de données à longue séquence, et l'amélioration des performances est visible à l'œil nu.
Optimisation de la mémoire : par rapport aux méthodes traditionnelles, FlashAttention consomme moins de mémoire et la relation linéaire fait que l'utilisation de la mémoire n'est plus un problème.
Fonctionnalités avancées : l'intégration d'une variété de technologies avancées améliore considérablement les performances du modèle et la portée des applications.
Facilité d'utilisation et compatibilité : un guide d'installation et d'utilisation simple, associé à la prise en charge de plusieurs architectures GPU, permet à FlashAttention-3 d'être rapidement intégré dans une variété de projets.
Adresse du projet : https://github.com/Dao-AILab/flash-attention
L’émergence de FlashAttention-3 accélérera sans aucun doute l’application et le développement de modèles linguistiques à grande échelle et apportera de nouvelles avancées dans le domaine de l’intelligence artificielle. Ses performances efficaces et sa facilité d'utilisation en font un choix idéal pour les développeurs. Dépêchez-vous et faites-en l'expérience !