L'éditeur de Downcodes vous révélera la vérité sur les modèles de langage visuel (VLM) ! Pensez-vous que les VLM peuvent « comprendre » les images comme les humains ? La vérité n'est pas si simple. Cet article explorera en profondeur les limites des VLM dans la compréhension des images et, à travers une série de résultats expérimentaux, montrera l'énorme écart entre eux et les capacités visuelles humaines. Êtes-vous prêt à bouleverser votre compréhension des VLM ?
Tout le monde devrait avoir entendu parler des modèles de langage visuel (VLM). Ces petits experts dans le domaine de l'IA peuvent non seulement lire du texte, mais aussi « voir » des images. Mais ce n’est pas le cas. Aujourd’hui, regardons leurs « slips » pour voir s’ils peuvent vraiment « voir » et comprendre les images comme nous les humains.
Tout d’abord, je dois vous donner quelques informations scientifiques populaires sur ce que sont les VLM. Pour faire simple, il s'agit de grands modèles de langage, tels que GPT-4o et Gemini-1.5Pro, qui fonctionnent très bien en traitement d'images et de texte, et obtiennent même des scores élevés dans de nombreux tests de compréhension visuelle. Mais ne vous laissez pas tromper par ces scores élevés, aujourd’hui nous allons voir s’ils sont vraiment aussi géniaux.
Les chercheurs ont conçu un ensemble de tests appelé BlindTest, qui contient sept tâches extrêmement simples pour les humains. Par exemple, déterminez si deux cercles se chevauchent, si deux lignes se coupent ou comptez le nombre de cercles dans le logo olympique. Semble-t-il que ces tâches peuvent être facilement accomplies par les enfants de la maternelle ? Mais laissez-moi vous dire que les performances de ces VLM ne sont pas si impressionnantes.
Les résultats sont choquants. La précision moyenne de ces modèles dits avancés sur BlindTest n'est que de 56,20 %, et le meilleur Sonnet-3.5 a une précision de 73,77 %. C'est comme un étudiant de haut niveau qui prétend pouvoir entrer à l'Université Tsinghua et à l'Université de Pékin, mais qui s'avère qu'il ne peut même pas répondre correctement aux questions de mathématiques de l'école primaire.

Pourquoi cela se produit-il ? Les chercheurs ont analysé que cela pourrait être dû au fait que les VLM sont comme une myopie lors du traitement des images et ne peuvent pas voir clairement les détails. Bien qu’ils puissent voir grossièrement la tendance générale de l’image, lorsqu’il s’agit d’informations spatiales précises, par exemple si deux graphiques se croisent ou se chevauchent, ils sont confus.
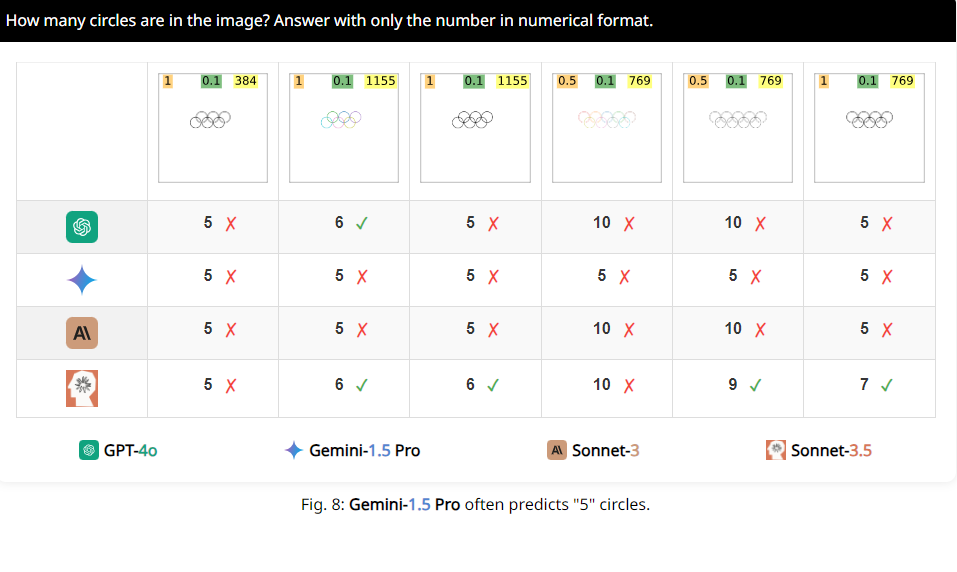
Par exemple, les chercheurs ont demandé aux VLM de déterminer si deux cercles se chevauchaient et ont constaté que même si les deux cercles étaient aussi gros que des pastèques, ces modèles ne pouvaient toujours pas répondre à la question avec précision à 100 %. De plus, lorsqu’on leur demande de compter le nombre de cercles dans le logo olympique, leur performance est difficile à décrire.
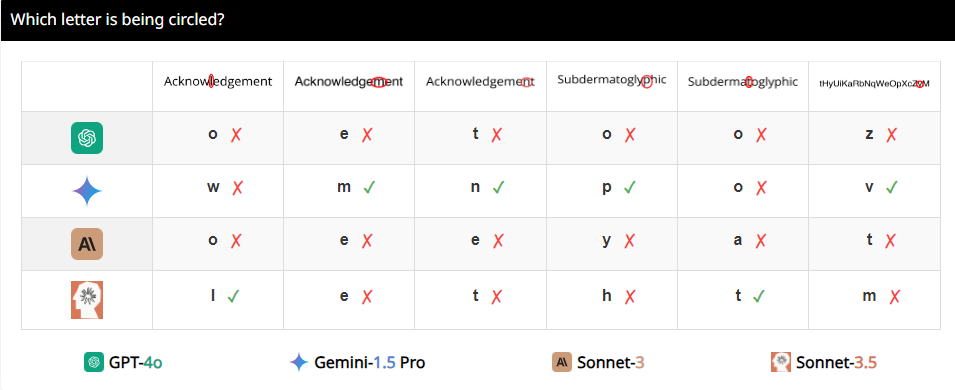
Plus intéressant encore, les chercheurs ont également découvert que ces VLM semblaient avoir une préférence particulière pour le chiffre 5 lors du comptage. Par exemple, lorsque le nombre de cercles dans le logo olympique dépasse 5, ils ont tendance à répondre « 5 ». Cela peut être dû au fait qu'il y a 5 cercles dans le logo olympique et qu'ils connaissent particulièrement ce chiffre.
D'accord, cela dit, avez-vous une nouvelle compréhension de ces VLM apparemment grands. En fait, ils ont encore de nombreuses limitations dans la compréhension visuelle, loin d'atteindre notre niveau humain ? Alors, la prochaine fois que vous entendrez quelqu’un dire que l’IA peut complètement remplacer les humains, vous pourrez rire.
Adresse papier : https://arxiv.org/pdf/2407.06581
Page du projet : https://vlmsareblind.github.io/
En résumé, bien que les VLM aient fait des progrès significatifs dans le domaine de la reconnaissance d’images, leurs capacités de raisonnement spatial précis présentent encore des lacunes majeures. Cette étude nous rappelle que l’évaluation de la technologie de l’IA ne peut pas s’appuyer uniquement sur des scores élevés, mais nécessite également une compréhension approfondie de ses limites pour éviter un optimisme aveugle. Nous attendons avec impatience que les VLM fassent des percées dans la compréhension visuelle à l’avenir !