L'éditeur de Downcodes vous fera découvrir une recherche révolutionnaire de Google DeepMind : Mixture of Experts (MoE). Cette recherche a réalisé des progrès révolutionnaires dans l'architecture Transformer. Son cœur réside dans un mécanisme de récupération expert efficace en termes de paramètres qui utilise la technologie clé du produit pour équilibrer le coût de calcul et le nombre de paramètres, améliorant ainsi considérablement le potentiel du modèle tout en maintenant l'efficacité. Cette recherche explore non seulement les contextes extrêmes du MoE, mais prouve également pour la première fois que la structure de l'indice d'apprentissage peut être efficacement acheminée vers plus d'un million d'experts, ouvrant ainsi de nouvelles possibilités dans le domaine de l'IA.
Le modèle Mixture d'un million d'experts proposé par Google DeepMind est une recherche qui a franchi des étapes révolutionnaires dans l'architecture Transformer.
Imaginez un modèle capable d’effectuer des recherches éparses auprès d’un million de micro-experts. Cela ressemble-t-il un peu à l’intrigue d’un roman de science-fiction ? Mais c’est exactement ce que montrent les dernières recherches de DeepMind. Le cœur de cette recherche est un mécanisme de récupération expert efficace en termes de paramètres qui utilise une technologie clé de produit pour découpler le coût de calcul du nombre de paramètres, libérant ainsi le plus grand potentiel de l'architecture du transformateur tout en maintenant l'efficacité de calcul.
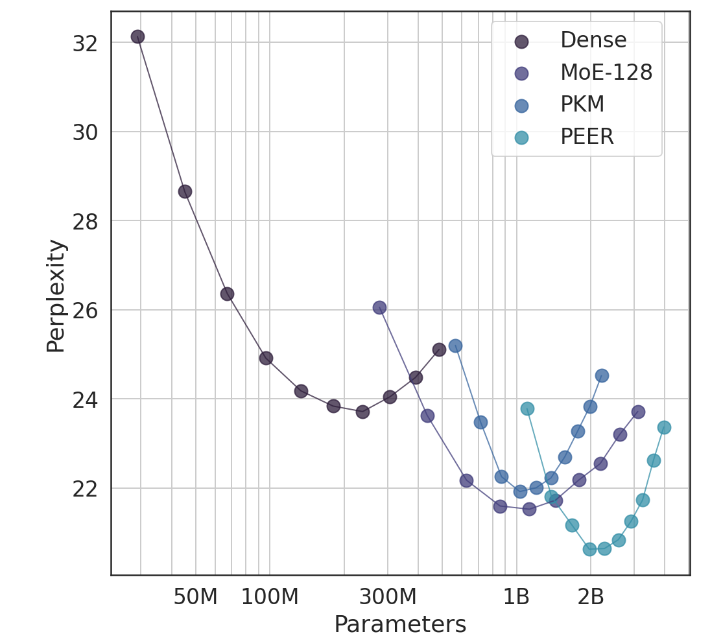
Le point culminant de ce travail est qu’il explore non seulement les paramètres extrêmes du MoE, mais démontre également pour la première fois qu’une structure d’index apprise peut être efficacement acheminée vers plus d’un million d’experts. C'est comme trouver rapidement quelques experts capables de résoudre le problème parmi une foule immense, et tout cela se fait dans le principe de coûts informatiques contrôlables.
Lors d'expériences, l'architecture PEER a démontré des performances de calcul supérieures et s'est révélée plus efficace que les couches denses FFW, MoE à gros grain et la mémoire de clé de produit (PKM). Il ne s’agit pas seulement d’une victoire théorique, mais aussi d’un énorme pas en avant dans l’application pratique. Grâce aux résultats empiriques, nous pouvons constater les performances supérieures du PEER dans les tâches de modélisation du langage. Il présente non seulement une perplexité moindre, mais également dans l'expérience d'ablation, en ajustant le nombre d'experts et le nombre d'experts actifs, les performances du PEER. le modèle a été considérablement amélioré.
L'auteur de cette étude, Xu He (Owen), est chercheur chez Google DeepMind. Son exploration à lui seul a sans aucun doute apporté de nouvelles révélations dans le domaine de l'IA. Comme il l'a montré, grâce à des méthodes personnalisées et intelligentes, nous pouvons améliorer considérablement les taux de conversion et fidéliser les utilisateurs, ce qui est particulièrement important dans le domaine de l'AIGC.
Adresse papier : https://arxiv.org/abs/2407.04153
Dans l'ensemble, la recherche sur les modèles hybrides de Google DeepMind, menée par un million d'experts, fournit de nouvelles idées pour la construction de modèles de langage à grande échelle. Son mécanisme efficace de récupération par des experts et ses excellents résultats expérimentaux indiquent un grand potentiel pour le développement futur de modèles d'IA. L’éditeur de Downcodes attend avec impatience d’autres résultats de recherche révolutionnaires similaires !